一种发散式关联的风机设备运检知识图谱构建及检索方法与流程
本发明属于风机设备运检与知识图谱领域,具体涉及一种发散式关联的风机设备运检知识图谱构建及检索方法。
背景技术:
1、随着越来越多的物联网、人工智能等技术被引入风机运检中,运检过程中的新设备、新方法也让风机运检过程变得更加复杂。在这种情况下,风机运检的业务将面临越来越大的挑战。风机运检过程中存在大量的多源异构数据,管理类别众多且繁杂,管理效率低下。
2、知识图谱是一种语义网,它以结构化的形式表示事物以及事物之间的关系,可以有效利用大量的结构化、半结构化和非结构化数据。知识图谱的构建包括知识抽取、知识融合与知识表示等。知识图谱分为通用知识图谱和领域知识图谱。通用知识图谱主要应用于搜索引擎;领域知识图谱主要应用于特定的领域,专业化程度更高,已在医疗、法律、金融、电商等领域有应用。
3、领域知识图谱构建的一个关键挑战是缺乏领域内的数据集且专业术语和概念较多。传统的基于规则或基于模板的知识抽取需要人工构建大量的规则模板,适用范围有限,难以适应复杂的需求。
4、因此,现阶段需设计一种发散式关联的风机设备运检知识图谱构建及检索方法,来解决以上问题。
技术实现思路
1、本发明目的在于提供一种发散式关联的风机设备运检知识图谱构建及检索方法,用于解决上述现有技术中存在的技术问题,构建知识图谱,减少人工的精力消耗,实现自动化地从原始数据中获取知识,并以neo4j图数据库进行可视化存储。
2、为实现上述目的,本发明的技术方案是:
3、一种发散式关联的风机设备运检知识图谱构建及检索方法,包括以下步骤:
4、s1:通过数据获取模块获取文档、表格及新闻等原始数据,将原始数据进行预处理,得到包括结构化数据与半/非结构化数据的预处理后的数据;并采用bert-bilstm-crf模型/关系抽取和属性抽取进行结构化进行实体抽取。
5、s2:对非结构化数据进行实体识别和实体消歧,通过对语句进行标签定义,确定语句中实体所处的范围。基于实体命名属性关系类似度比较法,将各组多源数据的共同命名实体以及所选属性存储在表中,对各个具备条件的属性设置不同权重,计算所有属性的加权值判断实体的相似度。
6、s3:采用path-rnn模型进行知识推理,采用路径推理法,将目标实体之间的路径,转化为rnn网络的输入,从而进行知识推理。
7、s4:风机故障知识图谱实体部分构建,结合textrank和tf idf技术对术语进行识别处理。创建概念实体。操作术语、事故处理术语、操作术语和故障术语是由两种算法提取的关键词创建的术语:校正、融合、筛选和分类。筛选方法结合数据材料完成术语,详细解释专业术语,并通过搜索和匹配添加相关的调度和安全规定。
8、s5:知识图谱的存储、展示和查询,根据实体框架,将各类实体结构化;在neo4j中灵活运用neo4j-web和neo4j-import,将通过数据清洗后得到的各个风机缺陷、缺陷原因、设备及零部件部件等标准结构化数据进行控制导入。用cypher查询语言进行语义查询,实现运用与图数据库的联接和交互;实现基于图数据库的各类语义类型、关系及节点对象、关系对象的查询、展示、修改。
9、所述步骤s1具体包括:应用网络爬虫技术,依法获取并下载各发电公司或设备厂家公开发布的文档以及风机运检过程的表格,然后需要针对不同的文件格式,分别利用开源软件模块python-docx、xlrd和pdfminer读取word、excel和pdf中包含的数据。
10、然后,从文本中获得的原始数据经过变换和编码,转换成适合计算机处理的向量形式,本发明使用了skip-gram模型优化词向量矩阵l,为每个词语学习准确的词向量表示。给定任意n元组(w,c)=wn-c…wn-1wnwn+1…wn+c,模型利用中心词的词向量e(wn)预测上下文中第t个词汇wt的概率为:
11、
12、上式中,wn表示中心词;e(wn)∈rd表示wn所对的d维度词向量,这种向量可通过向量矩阵l检索获得;c是规模大小,代表背景的窗口大小。模型的目标函数如下:
13、
14、在模型训练完毕后,可以得到优化后的词向量矩阵,包含此表中的全部分布式向量的表示。
15、针对文本数据的知识抽取。本专利利用双向长短期记忆神经网络(bidirectionallong short term memory,bilstm)结合条件随机场(conditionalrandom field,crf)的模型,进行命名实体的识别。
16、当给定词汇序列x=x0x1...xn,在已训练完成的的词向量表中查找到每个词汇对应的词向量en∈rd1,d1代表的是其向量的维度。lstm是由一个记忆存储单元和三个门来控制的它的输入是前一时刻的隐藏层表示hi-1和前一电力信息与通信技术时刻的输出wi-1,输出是当前时刻的隐藏层表示hi。计算方法如下:
17、in=σ(wie(wn-1)+uihn-1+vicn-1+bi)
18、fn=σ(wfe(wn-1)+ufhn-1+vfcn-1+bf)
19、on=σ(woe(wn-1)+uohn-1+vocn-1+bo)
20、
21、
22、
23、hn=on⊙tanh(cn)
24、
25、式中,in、fn、on分别代表输入、遗忘和输出门;cn代表记忆单元;wn、un、vn等和bi、bf、bo表示线性关系的偏移和系数,σ(x)表示激活函数,⊙表示点积。
26、前序的lstm得到的每个字符对应的隐藏层的表达是
27、
28、同理,后续的lstm得到隐藏层的表达则是
29、
30、前序隐藏层捕捉e(i)及其左部分的综合信息e(0)到e(i-1),后续隐藏层捕捉e(i)及其右侧信息e(i+1)到et。lstm将前序和后续隐藏层进行拼接,最终通过以下公式对条件概率p(y|x)进行建模:
31、
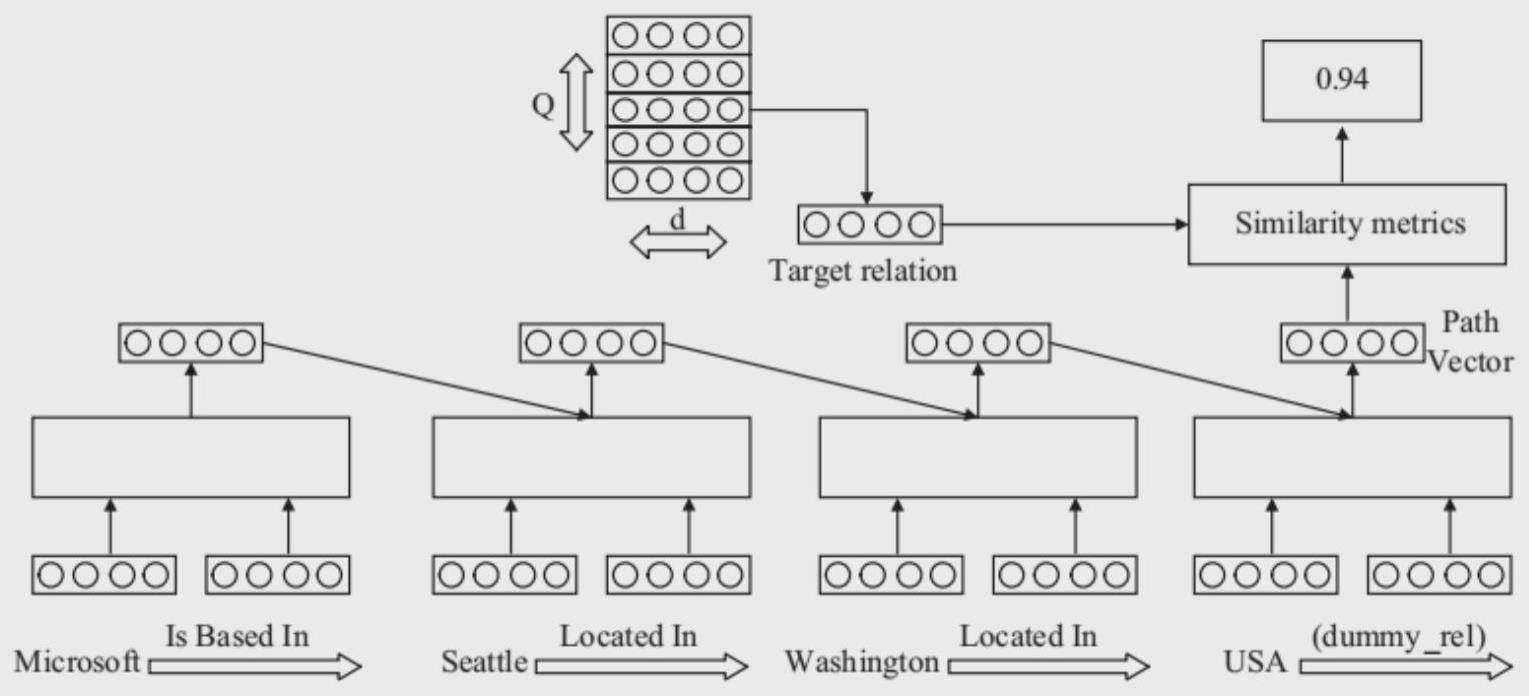
32、在上式中ρk是其参数;fk(yi+1,yi,m,i)是定义在序列m的前后相邻位置的转移函数。通过模型将其解码后得到如下结果:
33、
34、所述步骤s2具体包括:通过依存语法(dependency parsing,dp)来分析句中多个词语之间的支配与被支配的关系,展示整个句子的结构,即通过分析句子中包含的主语、谓语、宾语、定语、状语、补语等语法成分,总结各成分之间的关系。本专利使用mst进行依存句的句法分析。构建输入句的无环向图,其中包含了对应词汇的节点集合和有向边的集合。在依存结构图中支配者head,被支配者为dependency,不依存于其他词语的即为句子中的核心谓词节点。两两节点之间可能会有同方向但依存关系不同的有向边。mst将获取最佳依存结构转换为在有向图中寻找打分最高的依存树。
35、假定句子a的分析结果为b,模型参数是ε,使用条件概率模型sc(ai|bi;ε),训练过程中将找寻使i=1到n之间的模型最大的ε值。
36、mstparser定义整棵句法树的打分是树中各条弧分值的加权和:
37、
38、上式中:s为分数,b是句子a的依存树之一;w是特征f(·)的权值向量。
39、所述步骤s3具体包括:通过path-rnn模型将每条路径分解为关系序列,并将其加入到rnn中,从而构造路径的向量表示,然后通过路径向量表示的点积计算路径和候选关系的相关性。第一步先通过嵌入式矩阵,将全部的输入实体和关系转化为向量,方法同步骤s1。饥饿者使用pra来获得同关系r最相关的训练实例(es,r,et)的关系路径。将给定的三元组,进行pra的路径随机游走。从实体的头部到尾部,记录全部连接关系,获取多条关系路径,{r1,r2,...rn}加入中间实体,得到随机路径
40、k=[es,r1,e1....et],将路径扩展完整,其模型如图1所示。
41、当路径表示的搜索空间很大时,组合所有的路径并不能提供足够的证据来推断实体之间的关系,因此,为了缩小搜索范围,在模型上进行了扩展,对路径分布执行多步推理。多步推理是指对从bilstm中得到的路径向量多次使用注意力机制,将每次使用注意力机制得出的结果继续使用注意力机制去提高推理结果的精确值。每一步推理都会生成一个新的关系嵌入向量u来表示推理证据。
42、uz+1=wo(o2+u2)
43、获取路径后,进行实体消歧,流程如图2所示,基于实体命名属性关系类似度比较法,将各组多源数据的共同命名实体以及所选属性存储在表中,对各个具备条件的属性设置不同权重,计算所有属性的加权值判断实体的相似度。以风机的知识库实体名字、关系与数值属性作为特征分析量,计算2个实体的语义相似度。计算如下式所示:
44、
45、式中:a0,b0指的是a实体和b实体的实体名称;ai,bi指的是a实体与b实体的数值属性值;aj,bj指a实体和b实体的对象属性值;sim(a,b)指的是2个属性值的语义相似度;α+β+γ=1,其中α、β、γ分别代表了实体名称相似度、实体数值属性值相似度、实体对象属性值相似度的权重。对于数值属性实体,用下式进行计算:
46、
47、对集合型属性实体,用下式进行计算:
48、
49、对文本属性实体,用下式进行计算:
50、
51、所述步骤s4具体包括:创建一个风机运检领域的中心概念模型,以此为基础建立一个本体框架,如图3所示。构建风机设备故障知识图谱的本体是整个流程中的关键任务。风机设备本体的构建包涵了定义、概念、层次和类别,概念属性关系定义等步骤。本体概念类别划分主要是对设备故障类型进行类别划分与定义,按照其内部元素构成可分为以下几类:设备类、部件类、故障原因类、建议及措施类。概念属性关系定义能够使得本体更加细化,进而形成具有良好结构的分类层次体系,每个故障类由设备、部件、故障原因、建议及措施构成,都能被抽象成实体与实体状态形式描述。从而形成定义准确、以风场拓扑中节点为知识图谱中实体,开关以及线路用知识图谱中关系表示,节点的信息以属性形式存储在知识图谱中。将风机设备信息转化为结构化的三元组数据。
52、生产管理类知识构建,包括风机故障调度相关部门、风机故障发生时处理部门业务流程关系、部门对应负责人信息。
53、部门包括:部门【名称、任务、位置、负责人、电话】。
54、人员包括:人员【姓名、所在部门、年龄、职位、专业技能、电话】
55、风机故障处理事件部分构建
56、风机故障包括:故障【名称、别名、原因、属性、有何表现、处理方法、专家经验、对应人员】
57、所述步骤s5具体包括:根据实体框架,将各类实体结构化;在neo4j中灵活运用neo4j-web和neo4j-import,将通过数据清洗后得到的各个风机缺陷、缺陷原因、设备及零部件部件等标准结构化数据进行控制导入。
58、利用cypher查询语言进行语义查询,实现运用与图数据库的联接和交互;实现基于图数据库的各类语义类型、关系及节点对象、关系对象的查询、展示、修改。操作人员可以通过输入查询内容,经过语义理解和问题模板匹配转换为计算机可识别的cypher语言进行知识查询,利用cypher对知识库的实体关系直接进行检索,并通过数据可视化库(data-driven document,d3.js)技术以实体-关系-属性三元组的形式展示。
59、与现有技术相比,本发明所具有的有益效果为:
60、本方案其中一个有益效果在于,本发明提出了一种发散式关联的风机设备运检知识图谱构建方法,针对结构化数据如关系型数据库中的数据,完成从结构化数据到知识图谱到映射,实现从数据库向知识图谱的转化;针对非结构化数据,主要采用深度学习的方法,对风机运检过程产生的文本和网页信息进行知识抽取,完成实体识别与关系抽取,并将知识融合后的数据存入到neo4j中,通过neo4j图数据库实现知识图谱的可视化展示并可以使用cypher查询语言进行语义查询。方便运维人员快速查询运维知识,挖掘运维数据。
- 还没有人留言评论。精彩留言会获得点赞!