信息推荐方法及装置与流程
本公开涉及计算机,特别涉及信息推荐方法及装置、计算机可存储介质。
背景技术:
1、在推荐广场,当用户对于同一类信息(兴趣点)产生大量行为后,推荐系统更倾向于为该用户推荐同类型的信息(兴趣点)。这将导致推荐系统中出现信息茧房效应,信息茧房(information cocoon)是指用户沉浸在自己喜欢的信息之中,与外界的信息隔绝的现象。
技术实现思路
1、为解决推荐系统中存在的信息茧房效应,避免用户由于沉浸于自己感兴趣的信息,忽略其他可能感兴趣的信息,而导致的观点偏狭,本公开提出了一种解决方案,可以为用户推荐更加全面的信息,提高信息推荐的全面性和多样性。
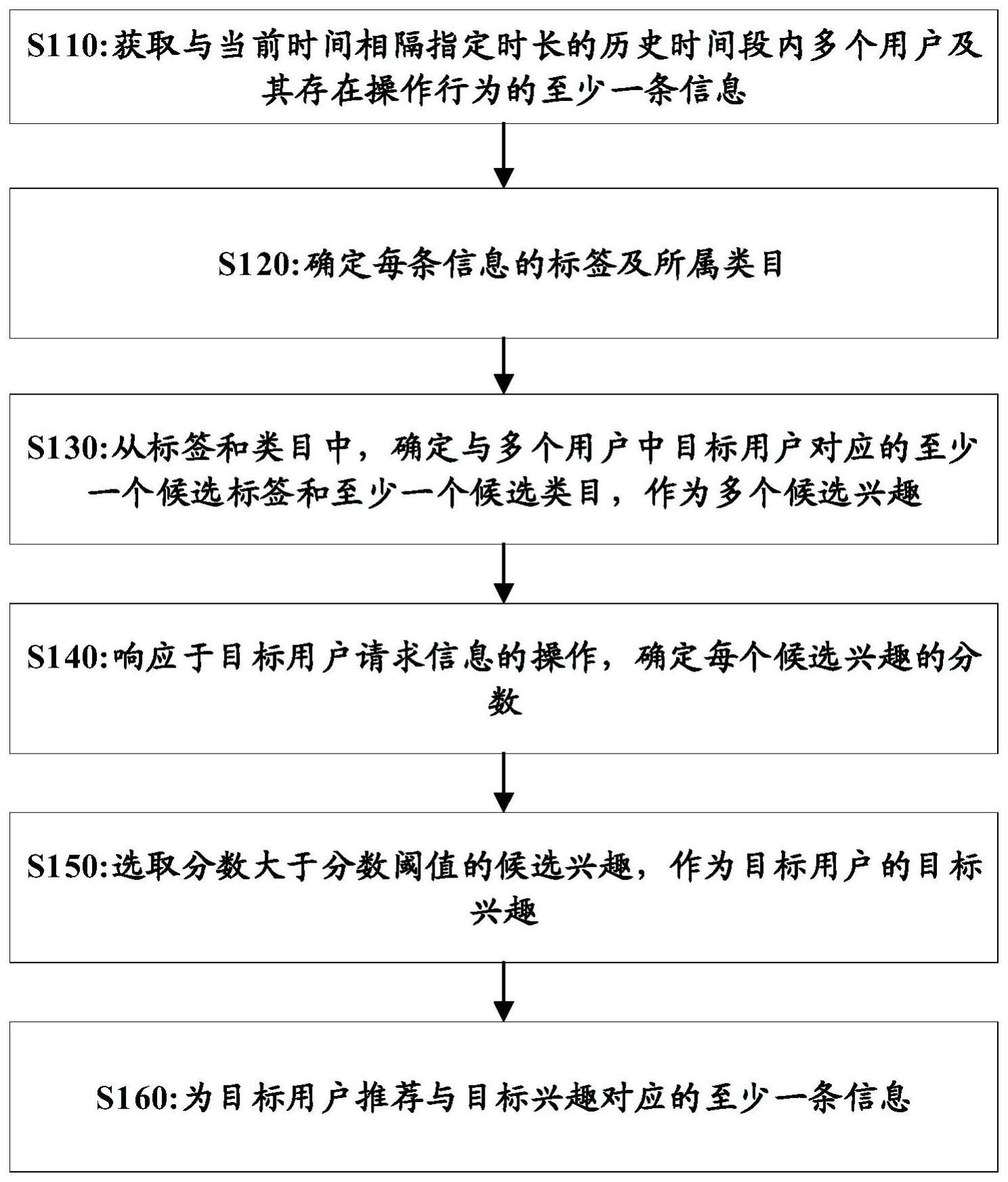
2、根据本公开的第一方面,提供了一种信息推荐方法,包括:获取与当前时间相隔指定时长的历史时间段内多个用户及其存在操作行为的至少一条信息;确定每条信息的标签及所属类目;从所述标签和所述类目中,确定与所述多个用户中目标用户对应的至少一个候选标签和至少一个候选类目,作为多个候选兴趣,其中,所述多个候选兴趣包括所述目标用户在所述历史时间段内不存在操作行为的信息的标签及所属类目;响应于所述目标用户请求信息的操作,确定每个候选兴趣的分数,其中,所述分数表征所述目标用户对所述每个候选兴趣的感兴趣程度;选取分数大于分数阈值的候选兴趣,作为所述目标用户的目标兴趣;为所述目标用户推荐与所述目标兴趣对应的至少一条信息。
3、在一些实施例中,确定每个候选兴趣的分数包括:利用汤普森采样法,根据每个候选兴趣对应的贝塔分布的阿尔法参数和贝塔参数,确定所述每个候选兴趣的分数。
4、在一些实施例中,信息推荐方法,还包括:根据所述目标用户查看所述目标信息的情况以及所述目标用户针对所述目标信息的互动行为的情况,更新与所述目标信息对应的所述目标兴趣所对应的阿尔法参数和贝塔参数;响应于所述目标用户再次请求信息的操作,根据更新后的阿尔法参数和更新后的贝塔参数,重复执行确定所述每个候选兴趣的分数、选取分数大于分数阈值的候选兴趣和为所述目标用户推荐与所述目标兴趣对应的目标信息的步骤。
5、在一些实施例中,更新与所述目标信息对应的所述目标兴趣所对应的阿尔法参数和贝塔参数包括:在所述目标用户查看了所述目标信息且所述目标用户对所述目标信息存在互动行为的情况下,对与所述目标信息对应的所述目标兴趣所对应的阿尔法参数增加指定值;在所述目标用户查看了所述目标信息但所述目标用户对所述目标信息不存在互动行为的情况下,对与所述目标信息对应的所述目标兴趣所对应的贝塔参数增加指定值。
6、在一些实施例中,从所述标签和所述类目中,确定与所述多个用户中目标用户对应的至少一个候选标签和至少一个候选类目包括:确定每个用户的向量表示、每条信息的标签的向量表示和每条信息所属的类目的向量表示;选取向量表示与所述目标用户的向量表示之间的相似度大于相似度阈值的用户、标签和类目,作为参考用户、参考标签和参考类目;从所述标签和所述类目中,获取所述参考用户在所述历史时间段与所述目标用户之间存在互动行为的类目和标签,作为参考标签和参考类目;从所述参考标签和所述参考类目中,过滤所述目标用户在所述历史时间段内存在操作行为的信息的标签和所属类目,得到所述至少一个候选标签和所述至少一个候选类目。
7、在一些实施例中,确定每个用户的向量表示、每条信息的标签的向量表示和每条信息所属的类目的向量表示包括:构建图网络,所述图网络包括用户节点、标签节点、类目节点以及用户节点与标签节点之间的单向边、用户节点与类目节点之间的单向边、不同的用户节点之间的单向边或双向边;根据所述图网络,训练图卷积网络gcn模型,得到每个用户的向量表示、每条信息的标签的向量表示和每条信息所属类目的向量表示。
8、在一些实施例中,根据所述图网络,训练图卷积网络gcn模型包括:对所述图网络进行数据清洗;根据数据清洗后的图网络,训练所述gcn模型。
9、在一些实施例中,对所述图网络进行数据清洗包括:删除对信息的操作行为的数量少于第一行为数量阈值的用户所对应的用户节点;和/或删除对信息的操作行为的数量大于第二行为数量阈值的用户所对应的用户节点,其中,所述第二行为数量阈值大于所述第一行为数量阈值。
10、在一些实施例中,对所述图网络进行数据清洗包括:删除与标签对应的操作行为的数量排名靠后的指定百分比的标签所对应的标签节点;和/或删除覆盖用户的百分比大于百分比阈值的标签节点。
11、在一些实施例中,对所述图网络进行数据清洗包括:删除覆盖用户的百分比大于所述百分比阈值的类目节点。
12、在一些实施例中,对所述图网络进行数据清洗包括:在以用户节点为起点的边的数量大于边数量阈值的情况下,通过随机采样的方式,删除以用户节点为起点的边,使得删除后的以用户为起点的边的数量小于或等于边数量阈值。
13、在一些实施例中,所述gcn模型包括图采样和聚合graphsage模型。
14、在一些实施例中,选取向量表示与所述目标用户的向量表示之间的相似度大于相似度阈值的用户、标签和类目,作为参考用户、参考标签和参考类目包括:分别对所述多个用户的向量表示、所述至少一条信息的标签的向量表示和所述至少一条信息所属的类目的向量表示,构建向量索引服务,得到用户向量索引服务、标签向量索引服务、类目向量索引服务;基于所述用户向量索引服务,选取向量表示与所述目标用户的向量表示之间的相似度大于相似度阈值的用户,作为参考用户;基于所述标签向量索引服务,选取向量表示与所述目标用户的向量表示之间的相似度大于相似度阈值的标签,作为参考标签;基于所述类目向量索引服务,选取向量表示与所述目标用户的向量表示之间的相似度大于相似度阈值的类目,作为参考类目。
15、在一些实施例中,为所述目标用户推荐与所述目标兴趣对应的至少一条信息包括:确定与所述目标兴趣对应的信息中与所述当前时间相隔最近的至少一条信息,作为与所述目标兴趣对应的目标信息;为所述目标用户推荐与所述目标兴趣对应的目标信息。
16、在一些实施例中,确定与所述目标兴趣对应的信息中与所述当前时间相隔最近的至少一条信息,作为与所述目标兴趣对应的目标信息包括:按照与所述目标兴趣对应的信息的时间戳的先后顺序,对与所述目标兴趣对应的信息进行倒排序;根据所述倒排序的结果,确定与所述目标兴趣对应的信息中与所述当前时间相隔最近的至少一条信息,作为与所述目标兴趣对应的目标信息。
17、根据本公开第二方面,提供了一种信息推荐装置,包括:获取模块,被配置为获取与当前时间相隔指定时长的历史时间段内多个用户及其存在操作行为的至少一条信息;第一确定模块,被配置为确定每条信息的标签及所属类目;第二确定模块,被配置为从所述标签和所述类目中,确定与所述多个用户中目标用户对应的至少一个候选标签和至少一个候选类目,作为多个候选兴趣,其中,所述多个候选兴趣包括所述目标用户在所述历史时间段内不存在操作行为的信息的标签及所属类目;第三确定模块,被配置为响应于所述目标用户请求信息的操作,确定每个候选兴趣的分数,其中,所述分数表征所述目标用户对所述每个候选兴趣的感兴趣程度;选取模块,被配置为选取分数大于分数阈值的候选兴趣,作为所述目标用户的目标兴趣;推荐模块,被配置为为所述目标用户推荐与所述目标兴趣对应的至少一条信息。
18、根据本公开第三方面,提供了一种信息推荐装置,包括:存储器;以及耦接至所述存储器的处理器,所述处理器被配置为基于存储在所述存储器的指令,执行上述任一实施例所述的信息推荐方法。
19、根据本公开的第四方面,提供了一种计算机可存储介质,其上存储有计算机程序指令,该指令被处理器执行时实现上述任一实施例所述的信息推荐方法。
20、在上述实施例中,可以为用户推荐更加全面的信息,提高信息推荐的全面性和多样性。
- 还没有人留言评论。精彩留言会获得点赞!