基于多模态神经网络模型的图文视频化方法、装置及设备与流程
本发明涉及深度学习领域及数字医疗领域,尤其涉及一种基于多模态神经网络模型的图文视频化方法、装置、电子设备及计算机可读存储介质。
背景技术:
1、基于多模态神经网络模型的图文视频化是指将静态的图片与文本组建成动态的视频的过程,以用于提升图片与文本的信息传播速度。
2、目前,随着深度学习技术的兴起,通过对医疗关键字进行特征提取,并在医疗图片数据库中查找医疗关键字的相关图片的技术,可以快速查询与某一疾病相关的图片内容,从而支持疾病辅助诊断、健康管理等功能,然而,与通过医疗关键字查询图片的技术相比,以医疗图片搜索其他医疗图片的技术稍显逊色,大多数医疗领域的图文的视频化都以人工的方式进行,需要创作者自行搜索相关医疗图片进行剪辑拼接,创作门槛较高,创作耗时也较长,在医疗文字材料数目多的情况下,效率很低;并且由于大多数创作者对医疗业务不熟练,在对医疗图片与医疗文本进行搭配时往往会出现搭配得不合适的情况。因此,医疗图文的视频化效率较低。
技术实现思路
1、本发明提供一种基于多模态神经网络模型的图文视频化方法、装置、电子设备及计算机可读存储介质,其主要目的在于提高医疗图文的视频化效率。
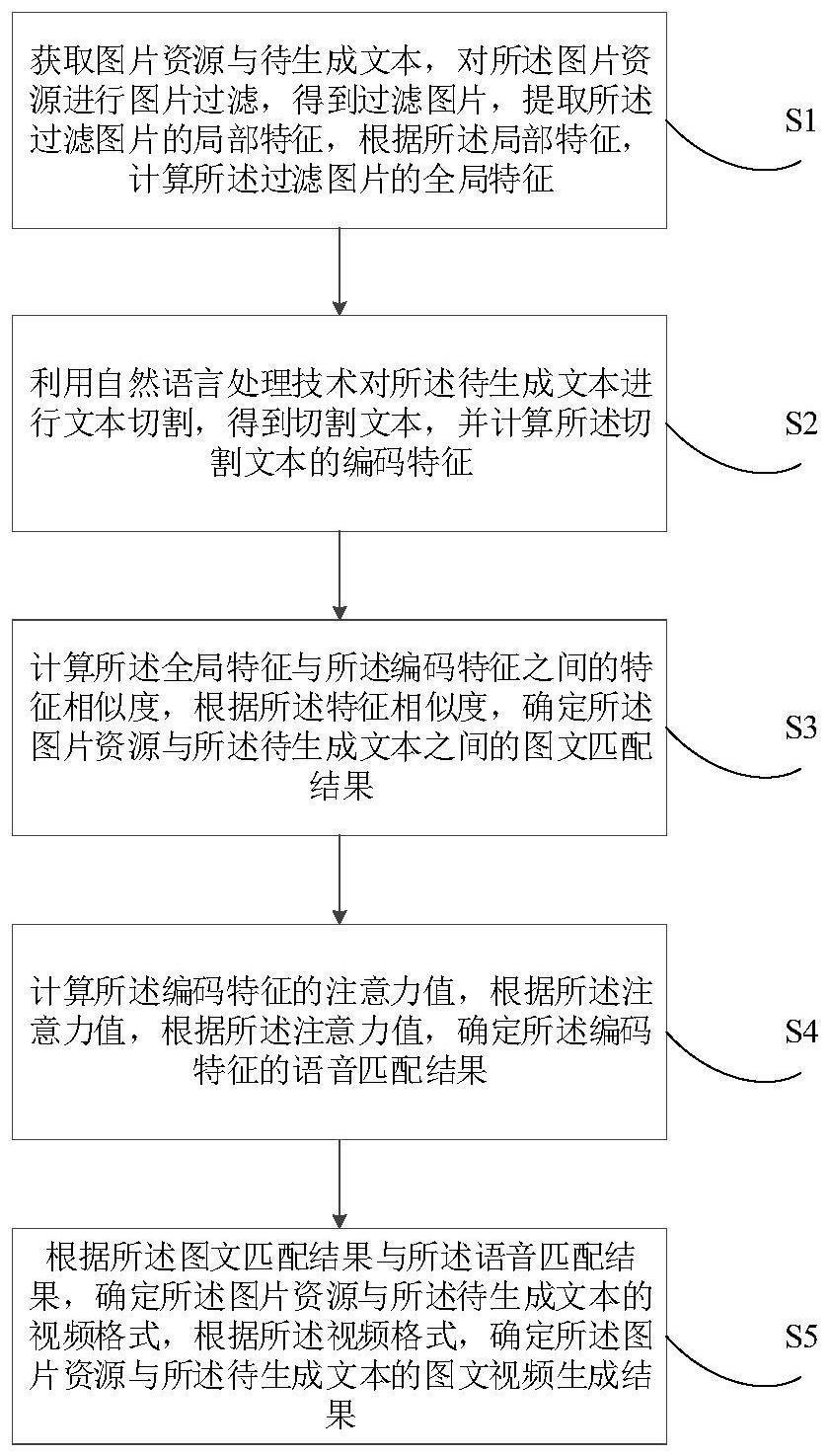
2、为实现上述目的,本发明提供的一种基于多模态神经网络模型的图文视频化方法,包括:
3、获取图片资源与初始文本,对所述图片资源进行图片过滤,得到过滤图片,提取所述过滤图片的局部特征,根据所述局部特征,计算所述过滤图片的全局特征;
4、利用自然语言处理技术对所述初始文本进行文本切割,得到切割文本,计算所述切割文本的编码特征;
5、计算所述全局特征与所述编码特征之间的特征相似度,根据所述特征相似度,确定所述图片资源与所述初始文本之间的图文匹配结果;
6、计算所述编码特征的注意力值,根据所述注意力值,确定所述编码特征的语音匹配结果;
7、根据所述图文匹配结果与所述语音匹配结果,确定所述图片资源与所述初始文本的视频格式,根据所述视频格式,确定所述图片资源与所述初始文本的图文视频生成结果。
8、可选地,所述对所述图片资源进行图片过滤,得到过滤图片,包括:
9、配置所述图片资源的过滤类别;
10、构建所述过滤类别的过滤编码;
11、对所述图片资源进行灰度级转换,得到转换灰度级图片;
12、计算所述转换灰度级图片的平均灰度;
13、根据所述平均灰度,对所述图片资源进行像素编码,得到编码像素;
14、计算所述过滤编码与所述编码像素之间的编码距离;
15、根据所述编码距离,确定所述图片资源中的过滤图片。
16、可选地,所述提取所述过滤图片的局部特征,包括:
17、构造所述过滤图片的检测窗口;
18、根据所述检测窗口,利用下述公式计算所述过滤图片的局部差异:
19、
20、其中,e(u,v)表示所述过滤图片的局部差异,w(x,y)表示窗口函数,i(x+u,y+v)表示利用所述检测窗口在所述过滤图片中平移之后的过滤图片,u与v表示利用所述检测窗口在所述过滤图片中平移的横纵距离,i(x,y)表示未平移之前的过滤图片;
21、计算所述局部差异的泰勒展开结果:
22、
23、
24、
25、
26、其中,表示所述泰勒展开结果,w(x,y)表示窗口函数,i(x+u,y+v)表示利用所述检测窗口在所述过滤图片中平移之后的过滤图片,u与v表示利用所述检测窗口在所述过滤图片中平移的横纵距离,i(x,y)表示未平移之前的过滤图片,ix与iy表示i(x,y)的偏导;
27、计算所述泰勒展开结果的特征指数:
28、
29、
30、
31、其中,(λ1,λ2)表示所述特征指数,u与v表示利用所述检测窗口在所述过滤图片中平移的横纵距离,i(x,y)表示未平移之前的过滤图片,ix与iy表示i(x,y)的偏导,m表示对所述泰勒展开结果进行形式转换之后的实对称矩阵,r表示旋转因子,λ1和λ2是指对m对角化处理后的两个正交方向的变化分量;
32、配置所述特征指数的特征阈值,根据所述特征指数与所述特征阈值,确定所述过滤图片的局部特征。
33、可选地,所述利用自然语言处理技术对所述初始文本进行文本切割,得到切割文本,包括:
34、利用所述自然语言处理技术中的词典表技术构建所述初始文本的文本词典;
35、利用所述自然语言处理技术中的中文分词技术对所述初始文本进行随机文本分割,得到随机分割文本;
36、将所述随机分割文本与所述文本词典进行文本匹配;
37、在所述随机分割文本与所述文本词典文本匹配失败时,返回上述利用所述自然语言处理技术中的中文分词技术对所述初始文本进行随机文本分割,得到随机分割文本的步骤;
38、在所述随机分割文本与所述文本词典文本匹配成功时,将所述随机分割文本作为所述切割文本。
39、可选地,所述计算所述切割文本的编码特征,包括:
40、对所述切割文本进行文本编码,得到编码文本;
41、利用下述公式计算所述编码文本的文本词频:
42、
43、其中,tf表示所述编码文本的文本词频,n表示编码文本在一篇文章中出现的次数,n表示这篇文章的总编码文本数;
44、利用下述公式计算所述编码文本的逆文本词频:
45、
46、其中,idf表示所述编码文本的逆文本词频,p表示全部文章数,m表示包含该词的文章总数;
47、根据所述文本词频与所述逆文本词频,利用下述公式计算所述编码文本的特征指数:
48、tf-idf=tf*idf
49、其中,tf-idf表示所述编码文本的特征指数,tf表示所述编码文本的文本词频,idf表示所述编码文本的逆文本词频;
50、根据所述特征指数,确定所述编码文本的编码特征。
51、可选地,所述根据所述特征相似度,确定所述图片资源与所述初始文本之间的图文匹配结果,包括:
52、配置所述特征相似度的相似度阈值;
53、将所述特征相似度与所述相似度阈值进行大小匹配;
54、在所述特征相似度与所述相似度阈值大小匹配成功时,则确定所述图片资源与所述初始文本之间的图文匹配结果为匹配成功;
55、在所述特征相似度与所述相似度阈值大小匹配失败时,则确定所述图片资源与所述初始文本之间的图文匹配结果为匹配失败。
56、可选地,所述根据所述图文匹配结果与所述语音匹配结果,确定所述图片资源与所述初始文本的视频格式,包括:
57、查询所述图文匹配结果与所述语音匹配结果对应的图片信息、文本信息与语音信息;
58、识别所述图片信息、所述文本信息与所述语音信息的信息类别;
59、根据所述信息类别,匹配所述图片信息、所述文本信息与所述语音信息对应的渲染格式;
60、识别所述图片信息、所述文本信息与所述语音信息的位置顺序;
61、根据所述位置顺序,确定所述图片信息、所述文本信息与所述语音信息的位置格式;
62、根据所述渲染格式与所述位置格式,确定所述图片资源与所述初始文本的视频格式。
63、为了解决上述问题,本发明还提供一种基于多模态神经网络模型的图文视频化装置,所述装置包括:
64、全局特征计算模块,用于获取图片资源与初始文本,对所述图片资源进行图片过滤,得到过滤图片,提取所述过滤图片的局部特征,根据所述局部特征,计算所述过滤图片的全局特征;
65、编码特征计算模块,用于利用自然语言处理技术对所述初始文本进行文本切割,得到切割文本,并计算所述切割文本的编码特征;
66、图文匹配确定模块,用于计算所述全局特征与所述编码特征之间的特征相似度,根据所述特征相似度,确定所述图片资源与所述初始文本之间的图文匹配结果;
67、语音匹配确定模块,用于计算所述编码特征的注意力值,根据所述注意力值,确定所述编码特征的语音匹配结果;
68、图文视频生成模块,用于根据所述图文匹配结果与所述语音匹配结果,确定所述图片资源与所述初始文本的视频格式,根据所述视频格式,确定所述图片资源与所述初始文本的图文视频生成结果。
69、为了解决上述问题,本发明还提供一种电子设备,所述电子设备包括:
70、至少一个处理器;以及,
71、与所述至少一个处理器通信连接的存储器;其中,
72、所述存储器存储有可被所述至少一个处理器执行的计算机程序,所述计算机程序被所述至少一个处理器执行,以实现上述所述的基于多模态神经网络模型的图文视频化方法。
73、为了解决上述问题,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质中存储有至少一个计算机程序,所述至少一个计算机程序被电子设备中的处理器执行以实现上述所述的基于多模态神经网络模型的图文视频化方法。
74、可以看出,本发明实施例通过获取图片资源与初始文本,以用于将静态的医疗图片与医疗文本转换为动态的医疗视频流形式,本发明实施例通过对所述图片资源进行图片过滤,以用于筛选掉低质量的、不适合用于发表医疗视频的医疗图片,进一步地,本发明实施例通过提取所述过滤图片的局部特征,以用于将对整体医疗图片的特征提取转换为对更加细致的医疗图片分块的特征提取,提升对医疗图片检索的精确度,进一步地,本发明实施例通过根据所述局部特征,计算所述过滤图片的全局特征,以用于根据提取到的医疗图片的细节特征来确定医疗图片的整体特征,这样可以提升对医疗图片特征提取的细致程度,保障后续对医疗图片进行检索的多样性,本发明实施例通过利用自然语言处理技术对所述初始文本进行文本切割,以用于将包含多个维度信息且较难匹配到合适的医疗图片的医疗长文本转换为能够表示某张医疗图片信息的单维度的医疗文本,提升后续检索与医疗文本相配的图片的效率,进一步地,本发明实施例通过计算所述切割文本的编码特征,以用于从庞大的编码数据中寻找能够概括周边数据的特征数据,减少数据的冗余性,提升对数据分析的效率。其中,所述编码特征是指所述初始文本的文本特征,本发明实施例通过计算所述全局特征与所述编码特征之间的特征相似度,以用于确定所述全局特征对应的医疗图片与所述编码特征对应的医疗文本是否相匹配,进一步地,本发明实施例通过根据所述特征相似度,确定所述图片资源与所述初始文本之间的图文匹配结果,以用于利用神经网络模型实现对医疗图片与医疗文本的自动检索匹配,保障后续将匹配好的医疗图片与医疗文本生成同一个医疗视频的内容,本发明实施例通过计算所述编码特征的注意力值,以用于提升神经网络模型专注于其输入或特征子集的能力,进一步地,本发明实施例通过根据所述注意力值,确定所述编码特征的语音匹配结果,以用于识别与所述初始医疗文本相匹配的医疗语音数据,本发明实施例通过根据所述图文匹配结果与所述语音匹配结果,确定所述图片资源与所述初始文本的视频格式,以用于利用不同类型的视频格式对所述医疗图文匹配结果与所述医疗语音匹配结果进行情感渲染,增强视频的感染力,提升医疗图文视频的质量,进一步地,本发明实施例通过根据所述视频格式,确定所述图片资源与所述初始文本的图文视频生成结果,以用于实现对静态医疗图片与医疗文本的自动化生成医疗视频的过程,提升医疗图文视频化的效率。因此,本发明实施例提出的一种基于多模态神经网络模型的图文视频化方法、装置、电子设备及计算机可读存储介质可以提高医疗图文的视频化效率。
- 还没有人留言评论。精彩留言会获得点赞!