歌曲搜索方法、装置、存储介质和计算设备与流程
本公开的实施方式涉及计算机,更具体地,本公开的实施方式涉及一种歌曲搜索方法、装置、存储介质和计算设备。
背景技术:
1、本部分旨在为说明书中陈述的本公开的实施方式提供背景或上下文。此处的描述不因为包括在本部分中就承认是现有技术。
2、在相关技术中,歌曲搜索一般是根据搜索方提供的搜索文本,从字面粒度上进行歌曲匹配。
3、通过这种方式搜索到的歌曲主要体现为:歌曲名称与搜索文本在字面上一致。然而,某些歌曲的歌曲名称虽然与搜索文本不一致、但其歌曲主题或者表达的情感恰好符合搜索文本的搜索需求,这样的歌曲无法被搜索到,导致相关技术提供的歌曲搜索存在搜搜结果不全面的问题。
技术实现思路
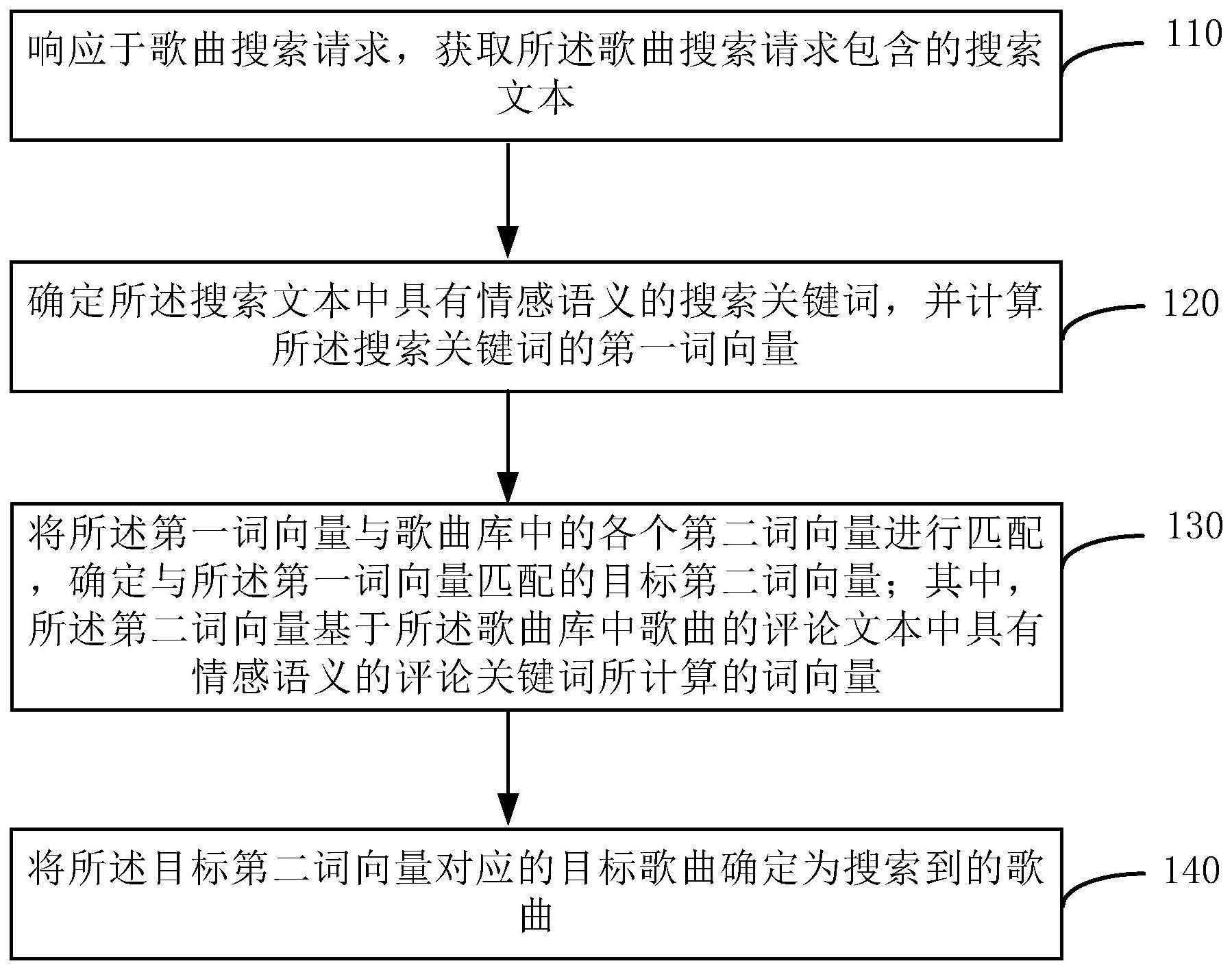
1、在本公开实施方式的第一方面中,提供了一种歌曲搜索方法。该方法包括:
2、响应于歌曲搜索请求,获取所述歌曲搜索请求包含的搜索文本;
3、确定所述搜索文本中具有情感语义的搜索关键词,并计算所述搜索关键词的第一词向量;
4、将所述第一词向量与歌曲库中的各个第二词向量进行匹配,确定与所述第一词向量匹配的目标第二词向量;其中,所述第二词向量基于所述歌曲库中歌曲的评论文本中具有情感语义的评论关键词所计算的词向量;
5、将所述目标第二词向量对应的目标歌曲确定为搜索到的歌曲。
6、可选的,所述第一词向量和第二词向量通过相同的词向量模型计算得到,并且所述词向量模型通过以下方式训练:
7、获取不同用户的历史搜索行为构建的若干消费序列,和不同歌曲的历史评论文本构建的若干评论序列;其中,每个消费序列由对应的历史搜索行为中的若干搜索关键词构成,每个评论序列由对应的历史评论文本中的若干评论关键词构成;
8、将所述消费序列和所述评论序列合并为样本序列后输入到词向量模型进行训练,以使所述词向量模型学习所述样本序列中各个关键词的上下文中其他词汇的出现概率,并基于所述关键词的上下文中其他词汇的出现概率生成所述关键词的词向量。
9、可选的,在所述学习所述样本序列中各个关键词的上下文中其他词汇的出现概率之前,还包括:
10、针对每个样本序列的每个关键词,确定负例词和正例词;其中,正例词包括该关键词的上下文中出现的关键词,负例词包括该关键词的上下文中没有出现的关键词;
11、将所述正例词和负例词作为训练标签随样本序列输入到词向量模型。
12、可选的,所述确定负例词,包括:
13、随机获取若干待校验的负例词;
14、从第三方的词向量库中获取每个待校验的负例词的词向量,以及该关键词的词向量;
15、计算待校验的负例词的词向量与该关键词的词向量之间的语义相关程度;
16、筛选语义相关程度低于预设程度的待校验的负例词作为该关键词的负例词。
17、可选的,所述评论序列中还插入有对应歌曲的歌曲唯一标识。
18、可选的,所述将所述第一词向量与歌曲库中的各个第二词向量进行匹配,包括:
19、计算所述第一词向量与歌曲库中的各个第二词向量的余弦相似度;
20、将余弦相似度大于阈值的第二词向量确定为与所述第一词向量匹配的目标第二词向量。
21、可选的,所述歌曲库中歌曲的评论文本包括优质评论文本。
22、可选的,还包括:
23、基于自然语言处理技术,生成与所述目标歌曲对应的可解释性的引导文案;其中,所述引导文案包括与所述目标歌曲的评论关键词相关的引导语。
24、可选的,所述生成与所述目标歌曲对应的可解释性的引导文案,包括:
25、响应于所述目标歌曲的评论关键词的数量超过第一阈值,计算每个评论关键词与所述搜索文本之间的余弦相似度;
26、基于余弦相似度确定最佳关键词,生成与所述最佳关键词对应的可解释性的引导文案。
27、可选的,还包括:
28、响应于所述引导文案的数量超过第二阈值,计算每个引导文案与所述搜索文本之间的余弦相似度;
29、基于余弦相似度确定最佳引导文案,将所述最佳引导文案确定为最终用于展示的引导文案。
30、可选的,所述自然语言处理技术包括预训练生成式转换器模型;
31、所述基于自然语言处理技术,生成与所述目标歌曲对应的可解释性的引导文案,包括:
32、将所述目标歌曲的评论关键词与预设模版组装为任务指令;
33、将所述任务指令发送给所述预训练生成式转换器模型,获取所述预训练生成式转换器模型生成与所述目标歌曲对应的可解释性的引导文案。
34、可选的,所述生成与所述目标歌曲对应的可解释性的引导文案,包括:
35、获取所述歌曲搜索请求的发起方的个性化信息;其中,所述个性化信息基于所述发起方的历史行为数据确定;
36、生成与所述目标歌曲对应的可解释性的、且符合所述个性化信息的引导文案。
37、可选的,所述词向量模型包括基于神经网络的跳字模型。
38、在本公开实施方式的第二方面中,提供了一种歌曲搜索装置,所述装置包括:
39、获取单元,响应于歌曲搜索请求,获取所述歌曲搜索请求包含的搜索文本;
40、计算单元,确定所述搜索文本中具有情感语义的搜索关键词,并计算所述搜索关键词的第一词向量;
41、匹配单元,将所述第一词向量与歌曲库中的各个第二词向量进行匹配,确定与所述第一词向量匹配的目标第二词向量;其中,所述第二词向量基于所述歌曲库中歌曲的评论文本中具有情感语义的评论关键词所计算的词向量;
42、确定单元,将所述目标第二词向量对应的目标歌曲确定为搜索到的歌曲。
43、可选的,所述第一词向量和第二词向量通过相同的词向量模型计算得到,并且所述词向量模型通过训练单元训练得到;
44、所述训练单元,进一步包括:
45、序列获取子单元,获取不同用户的历史搜索行为构建的若干消费序列,和不同歌曲的历史评论文本构建的若干评论序列;其中,每个消费序列由对应的历史搜索行为中的若干搜索关键词构成,每个评论序列由对应的历史评论文本中的若干评论关键词构成;
46、模型训练子单元,将所述消费序列和所述评论序列合并为样本序列后输入到词向量模型进行训练,以使所述词向量模型学习所述样本序列中各个关键词的上下文中其他词汇的出现概率,并基于所述关键词的上下文中其他词汇的出现概率生成所述关键词的词向量。
47、可选的,所述模型训练子单元在所述学习所述样本序列中各个关键词的上下文中其他词汇的出现概率之前,还包括:
48、负采样子单元,针对每个样本序列的每个关键词,确定负例词和正例词;其中,正例词包括该关键词的上下文中出现的关键词,负例词包括该关键词的上下文中没有出现的关键词;
49、输入子单元,将所述正例词和负例词作为训练标签随样本序列输入到词向量模型。
50、可选的,所述确定子单元确定负例词,进一步包括:
51、校验子单元,随机获取若干待校验的负例词;从第三方的词向量库中获取每个待校验的负例词的词向量,以及该关键词的词向量;计算待校验的负例词的词向量与该关键词的词向量之间的语义相关程度;筛选语义相关程度低于预设程度的待校验的负例词作为该关键词的负例词。
52、可选的,所述评论序列中还插入有对应歌曲的歌曲唯一标识。
53、可选的,所述匹配单元,进一步用于计算所述第一词向量与歌曲库中的各个第二词向量的余弦相似度;将余弦相似度大于阈值的第二词向量确定为与所述第一词向量匹配的目标第二词向量。
54、可选的,所述歌曲库中歌曲的评论文本包括优质评论文本。
55、可选的,还包括:
56、生成单元,基于自然语言处理技术,生成与所述目标歌曲对应的可解释性的引导文案;其中,所述引导文案包括与所述目标歌曲的评论关键词相关的引导语。
57、可选的,所述生成单元,进一步包括:
58、第一计算子单元,响应于所述目标歌曲的评论关键词的数量超过第一阈值,计算每个评论关键词与所述搜索文本之间的余弦相似度;
59、文案生成子单元,基于余弦相似度确定最佳关键词,生成与所述最佳关键词对应的可解释性的引导文案。
60、可选的,还包括:
61、第二计算子单元,响应于所述引导文案的数量超过第二阈值,计算每个引导文案与所述搜索文本之间的余弦相似度;
62、文案筛选子单元,基于余弦相似度确定最佳引导文案,将所述最佳引导文案确定为最终用于展示的引导文案。
63、可选的,所述自然语言处理技术包括预训练生成式转换器模型;所述生成单元,进一步包括:
64、指令组装子单元,将所述目标歌曲的评论关键词与预设模版组装为任务指令;
65、文案获取子单元,将所述任务指令发送给所述预训练生成式转换器模型,获取所述预训练生成式转换器模型生成与所述目标歌曲对应的可解释
66、
67、性的引导文案。
68、可选的,所述生成单元,进一步包括:
69、个性化信息获取子单元,获取所述歌曲搜索请求的发起方的个性化信息;其中,所述个性化信息基于所述发起方的历史行为数据确定;
70、个性化文案生成子单元,基于自然语言处理技术,生成与所述目标歌曲对应的可解释性的、且符合所述个性化信息的引导文案。
71、可选的,所述词向量模型包括基于神经网络的跳字模型。
72、在本公开实施方式的第三方面中,提供了一种计算机可读存储介质,包括:
73、当所述计算机可读存储介质中的指令由电子设备的处理器执行时,使得电子设备能够执行如前任一项所述的歌曲搜索方法。
74、在本公开实施方式的第四方面中,提供了一种计算设备,包括:
75、处理器;
76、用于存储所述处理器可执行指令的存储器;
77、其中,所述处理器被配置为执行所述可执行指令,以实现如前任一项所述的歌曲搜索方法。
78、根据本公开实施方式提供的歌曲搜索方案,通过将基于搜索文本的歌曲搜索转化为基于情感的歌曲搜索,如此可以更为全面地搜索到与用户的情感相匹配的歌曲,从而提高用户的使用体验。
79、具体地,通过计算搜索文本中具有情感语义的搜索关键词的第一词向量,并将第一词向量与歌曲库中预先计算的各个第二词向量进行匹配,以获取到与第一词向量对应的搜索关键词语义相近的目标第二词向量;由于目标第二词向量具有与搜索文本相近的情感语义,因此可以将第二词向量对应的目标歌曲确定为所搜到的歌曲。
80、这种基于情感语义的词向量匹配方式,不局限于文本上一致的歌曲,可以扩展到情感一致、文本不一致的歌曲。因此,可以更为全面地搜索到与用户的情感相匹配的歌曲。
- 还没有人留言评论。精彩留言会获得点赞!