基于大数据的乡村水污染快速溯源方法及系统与流程
本发明涉及数据处理领域,具体涉及基于大数据的乡村水污染快速溯源方法及系统。
背景技术:
1、突发性水污染是指由于人的行为使得水资源在短期内恶化速率加大的水污染现象,在村规民约的不断完善过程中,部分群众的用水习惯和畜禽养殖业的发展是导致突发性水资源污染不断加重的主要因素,例如污水乱泼乱倒、养殖业随机处理等现象;而突发性水污染会对人民生命财产安全造成严重威胁,因此要尽量减少突发性水污染事件带来的损失,则需要及时而准确地追溯出污染源并加以处理。
2、现阶段对水污染溯源方法是通过人为检测污染地水样后,再对各养殖场地的水样进行抽取检测,通过检测结果追溯污染源,然而污水较强的流动性以及地形的复杂性都会影响到溯源结果的可靠性;同时人工检测需要花费较长时间来完成溯源,通过设置采样点并实时监测水体中污染物含量,进而构成不同采样点时序的污染物含量大数据,基于污染物含量的变化完成污水的溯源,提高溯源结果的可靠性及时效性。
技术实现思路
1、本发明提供基于大数据的乡村水污染快速溯源方法及系统,以解决现有的由于水体流动而影响污水快速溯源的问题,所采用的技术方案具体如下:
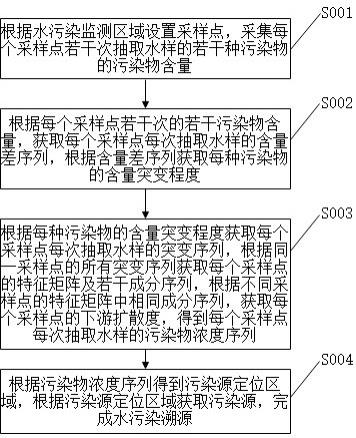
2、第一方面,本发明一个实施例提供了基于大数据的乡村水污染快速溯源方法,该方法包括以下步骤:
3、根据水污染监测区域设置采样点,采集每个采样点若干次抽取水样的若干种污染物的污染物含量;
4、根据每个采样点每次抽取水样的每种污染物的污染物含量,获取每个采样点每次抽取水样的含量差序列,根据含量差序列获取每种污染物的含量突变概率,根据含量差序列获取每种污染物的关键采样点,根据关键采样点的含量差序列及含量突变概率,获取每种污染物的含量突变程度;
5、根据每个采样点每次抽取水样的每种污染物的污染物含量,以及每种污染物的含量突变程度,获取每个采样点每次抽取水样的突变序列,根据突变序列获取每个采样点的特征矩阵及若干成分序列,根据不同采样点的同种成分序列,获取每个采样点每种成分序列的相似数量,根据相似数量及不同采样点的同种成分序列,获取每个采样点的下游扩散度,根据下游扩散度及突变序列获取每个采样点的污染物浓度序列;
6、根据污染物浓度序列得到污染源定位区域,根据污染源定位区域获取污染源,完成水污染溯源。
7、可选的,所述获取每个采样点每次抽取水样的含量差序列,包括的具体方法为:
8、以任意一个采样点为目标采样点,目标采样点的任意一次抽取水样为目标次抽取水样,计算目标采样点的目标次抽取水样与相邻前一次抽取水样中,每种污染物的污染物含量的差值绝对值,记为目标采样点目标次抽取水样中每种污染物的含量差,将所有含量差从大到小降序排列,得到的序列记为目标采样点目标次抽取水样的含量差序列;
9、获取目标采样点每次抽取水样的含量差序列,获取每个采样点每次抽取水样的含量差序列。
10、可选的,所述根据含量差序列获取每种污染物的含量突变概率,包括的具体方法为:
11、
12、
13、其中,表示第种污染物在含量差序列中的次序熵,表示含量差序列中的次序数量,表示第种污染物的含量差在所有采样点的所有含量差序列中排在第位的频率,所述频率为第种污染物的含量差排在第位的含量差序列数量与含量差序列总数量的比值,表示以10为底的对数;
14、其中,表示第种污染物的含量突变概率,表示所有采样点的所有含量差序列中第种污染物的含量差均值,表示污染物的种类数,表示第种污染物在含量差序列中的次序熵,表示所有采样点的所有含量差序列中第种污染物的含量差均值。
15、可选的,所述根据含量差序列获取每种污染物的关键采样点,包括的具体方法为:
16、以任意一个采样点为目标采样点,获取目标采样点所有含量差序列中第种污染物的含量差均值,记为目标采样点第种污染物的含量均差;获取每个采样点第种污染物的含量均差,将含量均差大于的采样点记为第种污染物的关键采样点,其中表示所有采样点的所有含量差序列中第种污染物的含量差均值;
17、获取每种污染物的关键采样点。
18、可选的,所述获取每种污染物的含量突变程度,包括的具体方法为:
19、
20、其中,表示第种污染物的含量突变程度,表示第种污染物的含量突变概率,表示第种污染物的关键采样点数量,表示抽取水样次数,表示每个采样点的含量差序列数量,表示第个关键采样点的第个含量差序列,表示第个关键采样点的第个含量差序列,表示求皮尔逊相关系数。
21、可选的,所述获取每个采样点每次抽取水样的突变序列,包括的具体方法为:
22、以任意一个采样点为目标采样点,目标采样点的任意一次抽取水样为目标次抽取水样,将目标采样点目标次抽取水样的每种污染物的污染物含量按照含量突变程度的大小关系降序从大到小排列,得到的序列记为目标采样点目标次抽取水样的突变序列;
23、获取每个采样点每次抽取水样的突变序列。
24、可选的,所述根据突变序列获取每个采样点的特征矩阵及若干成分序列,包括的具体方法为:
25、以任意一个采样点为目标采样点,以目标采样点第一次抽取水样的突变序列为矩阵的第一行,目标采样点每次抽取水样的突变序列按照抽取水样次序从小到大作为矩阵的每一行,得到的矩阵记为目标采样点的特征矩阵;
26、将特征矩阵中第一列所有元素从上到下排列得到的序列,记为目标采样点的第一成分序列,得到目标采样点的第一、第二直到第六成分序列,得到目标采样点的若干成分序列;
27、获取每个采样点的特征矩阵及若干成分序列。
28、可选的,所述获取每个采样点每种成分序列的相似数量,包括的具体方法为:
29、以每个采样点的第一成分序列为例,获取每个第一成分序列中的元素均值,将元素均值最大的第一成分序列作为聚类中心,聚类距离采用不同第一成分序列之间的dtw距离,利用k-shape算法对所有第一成分序列进行聚类,得到的若干类别记为第一类别,对所有第一成分序列聚类得到了若干第一类别;对所有第二成分序列聚类得到若干第二类别,对每种成分序列都进行聚类,得到若干第三类别直到若干第六类别;
30、以任意一个第一类别为目标第一类别,将目标第一类别中与其他所有第一成分序列的dtw距离均值最小的第一成分序列,作为目标第一类别的类别中心,获取每个类别的类别中心;
31、获取第个采样点的第一成分序列与所属第一类别的类别中心的dtw距离,记为第个采样点的第一成分序列的类内距离;获取第个采样点的第一成分序列所属第一类别中其他每个第一成分序列与第个采样点的第一成分序列的dtw距离,将dtw距离小于类内距离的第一成分序列记为第个采样点的第一成分序列的相似序列,相似序列的数量记为第个采样点的第一成分序列的相似数量;
32、获取每个采样点的每种成分序列的相似数量。
33、可选的,所述获取每个采样点的下游扩散度,包括的具体方法为:
34、
35、其中,表示第个采样点的下游扩散度,表示污染物种类数,即成分序列的种类数,表示第个采样点第种污染物对应成分序列所属类别中成分序列的数量,表示第个采样点第种污染物对应成分序列的相似数量。
36、第二方面,本发明另一个实施例提供了基于大数据的乡村水污染快速溯源系统,该系统包括:
37、污染数据采集模块,根据水污染监测区域设置采样点,采集每个采样点若干次抽取水样的若干种污染物的污染物含量;
38、数据处理分析模块:根据每个采样点每次抽取水样的每种污染物的污染物含量,获取每个采样点每次抽取水样的含量差序列,根据含量差序列获取每种污染物的含量突变概率,根据含量差序列获取每种污染物的关键采样点,根据关键采样点的含量差序列及含量突变概率,获取每种污染物的含量突变程度;
39、根据每个采样点每次抽取水样的每种污染物的污染物含量,以及每种污染物的含量突变程度,获取每个采样点每次抽取水样的突变序列,根据突变序列获取每个采样点的特征矩阵及若干成分序列,根据不同采样点的同种成分序列,获取每个采样点每种成分序列的相似数量,根据相似数量及不同采样点的同种成分序列,获取每个采样点的下游扩散度,根据下游扩散度及突变序列获取每个采样点的污染物浓度序列;
40、污染溯源管理模块,根据污染物浓度序列得到污染源定位区域,根据污染源定位区域获取污染源,完成水污染溯源。
41、本发明的有益效果是:本发明通过采样点对应的含量序列构建含量突变程度,含量突变程度考虑了每个采样点多次抽取水样中污染物含量差的稳定程度,其避免将地形等环境因素导致采样点处污染物含量突变作为误判为突发性水污染导致的现象;根据含量突变程度获取采样点的突变序列,进而得到成分序列并获取下游扩散度,下游扩散度考虑了采样点不同突变程度的污染物成分序列对下游区域的扩散程度,通过对不同成分序列分析计算,更好地对不同采样点中污染物的传播能力进行表达,规避了其余污染源对突发性污水源溯源的影响,提高后续获取污染源定位区域的精度;最后利用apriori规则算法从污染源定位区域实现对突发性水污染的污染溯源的目的,避免其余污水排放源对溯源精度的影响。
- 还没有人留言评论。精彩留言会获得点赞!