面向多元锂离子电池数据的全生命周期演化趋势预测方法
本发明涉及锂离子电池领域,特别是涉及一种面向多元锂离子电池数据的全生命周期演化趋势预测方法。
背景技术:
1、锂离子电池作为最成熟的储能技术,是电动车辆和储能系统(ess)最核心的组成部分,因而面向蓄能产品的故障预测和健康管理(prognostics and health management,phm)对于运行维护至关重要。从电池全生命周期管理的角度来讲,锂离子电池的电化学机理在使用或搁置过程会逐渐退化,使系统性能的供电能力和安全特性等管理指标也表现为衰减趋势,为降低电池运行成本、实现及时维护和故障防控,基于电池管理系统(bmss)对健康状态(soh)进行在线监控是很有必要的。从电池管理的角度来讲,故障预测的核心是针对电池系统运行欠佳或失效的异常进行刨析,健康管理的核心是面向容量和阻抗等指标的健康状态(state of health,soh)估计。
2、目前,基于模型驱动的健康状态预测占多数。该类方法是根据有穷小规模数据的背景分布或领域经验设定数学假设,通过假设建模最优拟合度的映射函数,并基于函数运算值实现预测。基于模型驱动的健康状态预测方法更易于调整模型参数、适应性更强,针对相似机理或同等工况的模型具备普适性。然而,现有驱动模式的时序预测方法存在难以挖掘现在和未来间细粒度映射关系、难以提升智能预测服务准确性、鲁棒性和可解释性的技术问题。
技术实现思路
1、针对现有技术中的上述不足,本发明提供的一种面向多元锂离子电池数据的全生命周期演化趋势预测方法解决了现有预测方法难以挖掘现在和未来间细粒度映射关系、难以提升智能预测服务准确性、鲁棒性和可解释性的技术问题。
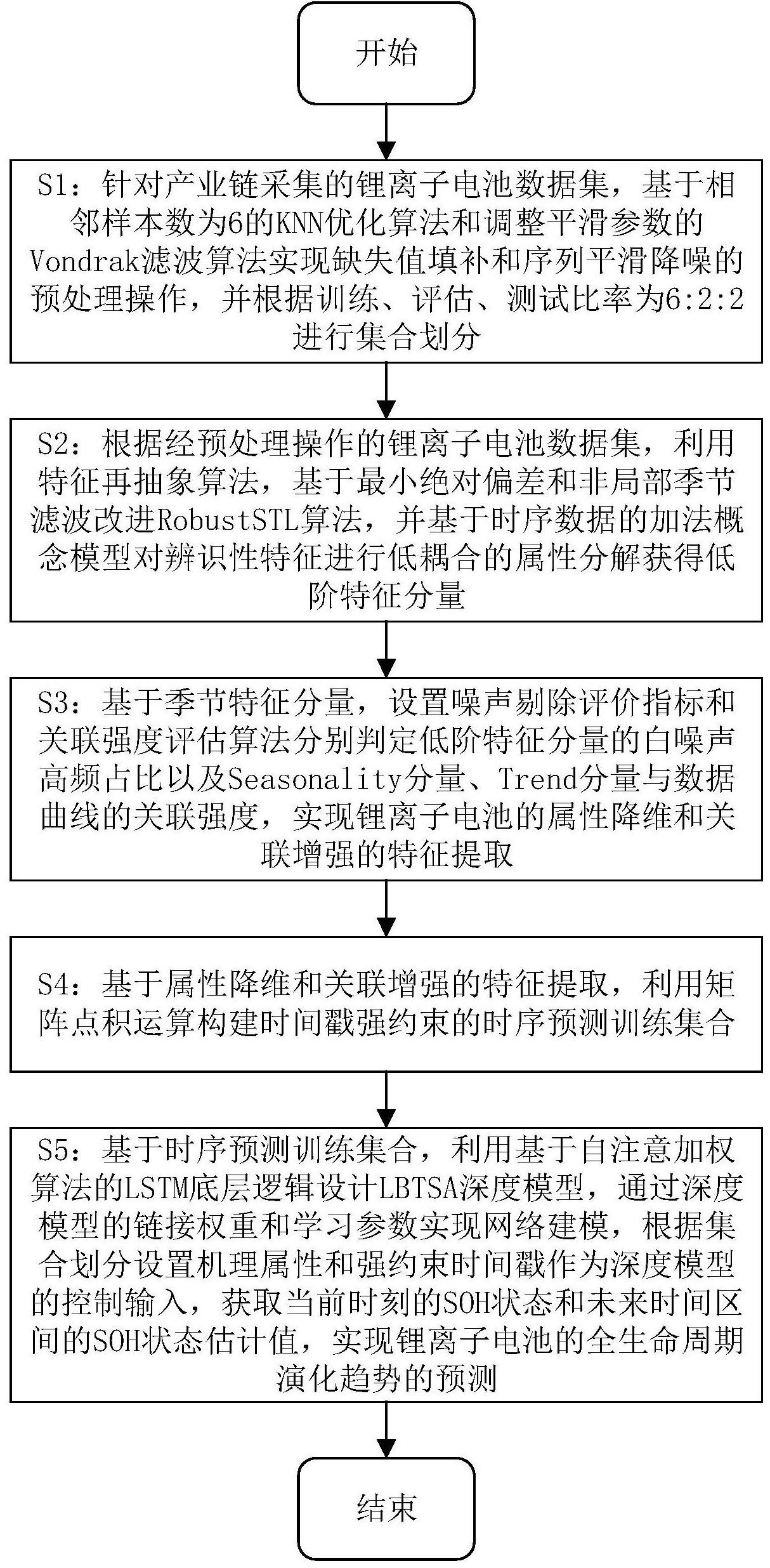
2、为了达到上述发明目的,本发明采用的技术方案为:一种面向多元锂离子电池数据的全生命周期演化趋势预测方法,所述方法包括以下步骤:
3、s1:针对产业链采集的锂离子电池数据集,基于相邻样本数为6的knn优化算法和调整平滑参数的vondrak滤波算法实现缺失值填补和序列平滑降噪的预处理操作,并根据训练、评估、测试比率为6:2:2进行集合划分;
4、s2:根据经预处理操作的锂离子电池数据集td,利用特征再抽象算法,基于最小绝对偏差和非局部季节滤波改进robuststl算法,并基于时序数据的加法概念模型对辨识性特征进行低耦合的属性分解获得低阶特征分量;
5、s3:基于低阶特征分量,设置噪音剔除评价指标和关联强度评估算法分别判定低阶特征分量的白噪声高频占比以及seasonality分量、trend分量与数据曲线的关联强度,实现锂离子电池的属性降维和关联增强的特征提取;
6、s4:基于属性降维和关联增强的特征提取,利用矩阵点积运算构建时间戳强约束的时序预测训练集合;
7、s5:基于时序预测训练集合,利用基于自注意加权算法的lstm底层逻辑设计lbtsa深度模型,通过深度模型的链接权重和学习参数实现网络建模,根据集合划分设置机理属性和强约束时间戳作为深度模型的控制输入,获取当前时刻的soh状态和未来时间区间的soh状态估计值,实现锂离子电池的全生命周期演化趋势的预测。
8、上述方案的有益效果是:本发明基于数据驱动的大数据智能分析框架提出了针对多元长周期锂离子电池序列的soh状态预测算法,是以fra再抽象序列算法为核心的特征提取和以lbtsa深度模型为主体的数据建模。解决了现有预测方法难以挖掘现在和未来间细粒度映射关系、难以提升智能预测服务准确性、鲁棒性和可解释性的技术问题。
9、进一步地,s1中利用knn优化算法,根据欧氏距离确定距离缺失样本点接近的6个样本,并通过计算6个样本观测点的加权平均值估计缺失数据。
10、上述进一步方案的有益效果是:序列缺失数值将激化数据稀疏性敏感问题,价值挖掘会因空值现象而陷入混乱,导致不可靠信息的输出,导致时序预测表现的不确定性因素更加突出,蕴含的确定性因素更难把握,采用上述技术方案,有效解决序列缺失问题。
11、进一步地,s1中vondrak滤波算法q公式为
12、
13、其中,f为逼真拟合度,λ为正常值,s为粗糙光滑度,n为数据规模,i为数据规模取值,pi为观测点的数值权重,yi为观测数值,为观测值的平均值,δ为差分符号,δ3为三阶差分;
14、设定无量纲正数ε为
15、
16、将无量纲正数ε定义为平滑因子,在观测数据的绝对逼真和绝对拟合之间起到平滑作用。
17、上述进一步方案的有益效果是:针对产业链数据集存在噪音干扰及离群点密集的预处理问题,本发明通过调参优化了vondrak滤波机制。其中,vondrak滤波是面向航天高精度序列数据的处理算法,可以剔除高频噪音并最大程度保留价值区间,通过定义平滑因子,在观测数据的绝对逼真和绝对拟合之间起到平滑作用。
18、进一步地,s2中改进的robuststl算法通过设置内循环与外循环实现鲁棒局部加权回归的权重调节、趋势拟合及周期分量的系统运算,使经改进的robuststl算法分解的特征分量对异常波动和趋势突变具有强的鲁棒性;
19、所述改进的robuststl算法包括基于白噪音平滑的residual更新阶段,基于序列差分的trend分解阶段和基于领域覆盖的seasonality分解阶段。
20、上述进一步方案的有益效果是:通过对robuststl算法进行改进,提升算法的鲁棒性,利于方案的实施。
21、进一步地,基于白噪音平滑的residual更新阶段包括以下公式:
22、根据序列加法概念模型将residual分量描述为
23、residuali=ai+ni
24、其中,residuali为由白噪声ni、尖峰ai或低谷构成的残差集合;
25、利用双边滤波算法剔除不稳定因素以保证residual分量和trend分量的稳健性,所述双边滤波算法公式如下:
26、
27、其中,td'i为去噪样本,j为长度为2h+1的滤波窗口,为时刻i的观测点邻接区间为j的滤波权重;
28、
29、其中,σ为无量纲的归一化相关参数,e为指数函数,和为算法预设的平滑度控制参数,tdj为邻接区间为j的观测值,tdi为时刻i的观测值;
30、则更新后的一阶residual分量为
31、
32、其中,residual'i为更新后的一阶residual分量,为趋势trendi中白噪音的错误或干扰因素。
33、上述进一步方案的有益效果是:通过上述公式,用于实现基于白噪音平滑的residual更新阶段,residual表现为采集工况中因信号错误或噪声污染掺杂的不稳定因素,通过利用双边滤波技术剔除不稳定因素以保证trend分量和seasonality分量的稳健性。
34、进一步地,基于序列差分的trend分解阶段包括以下公式:
35、通过设定基于seasonality分量和residual分量的季节性差分值趋于极小值的假设条件减轻季节性特征在序列成分中的影响因子,季节性差分gi公式为
36、
37、其中,t为循环周期,代表差分操作,seasonalityi为seasonality分量;
38、基于季节性差分gi构建加权目标函数恢复一阶加权目标函数公式为
39、
40、其中为季节性二阶差分值,λ1和λ2为目标函数的权衡参数,n为观测序列的样本点数量;
41、通过加权目标函数,得到trend分量公式为
42、
43、其中,为trend分量的优化输出,上标~为优化输出的标识,为首次迭代输出的趋势分量,x为fra算法的迭代次数;
44、更新后的二阶residual分量residual”i为
45、
46、其中,trendi为trend分量;
47、基于lad损失回归函数分解trend分量后,去趋势集合td”i表示为
48、
49、上述进一步方案的有益效果是:通过上述公式用于实现基于序列差分的trend分解阶段。
50、进一步地,基于领域覆盖的seasonality分解阶段中采用非局部季节性过滤算法公式为
51、
52、
53、ω={(i',j)|(i'=t-k×t,j=i'±h)}k=1,2,…,k;h=1,2,…,h
54、其中,为长度为2h+1的滤波窗口的邻接区间为(i′,j)的滤波权重,ω为邻接区间的集合表示,tdj″为邻接区间(i′,j)时的去趋势集合,t、k、k、h和h均为正实数。
55、上述进一步方案的有益效果是:通过上述公式用于实现基于领域覆盖的seasonality分解阶段,为确保seasonality的估算精度,本方案采用非局部季节性过滤算法。
56、进一步地,s3中包括以下公式
57、面向序列白噪音分解纯度的评估阶段,针对特征分量的二阶抽象运算函数tsr表示为
58、tsr=fra(trend,seasonality,residual|θ,μ,td,ψ)
59、其中,fra为再抽象算法,θ为预设定的提取纯度,μ为白噪音分解纯度,ψ为fra的算法参数,td为观测值;
60、判定白噪音分解占比μ′n的公式为
61、
62、其中,n为实验序列长度,μ′n为第n次算法迭代时residual分量相较第n-1次residual分量的收敛性,residuali,n为第n次residual分量,residuali,n-1为第n-1次residual分量;
63、通过比较μ′n与预设值,评估白噪声的高频占比;
64、面向trend分量和seasonality分量提取纯度的评估阶段,利用pearson相关系数衡量特征分量和评估参数定距变量间的线性关系,通过健康指标soh判定特征分量提取纯度的公式为
65、
66、
67、其中,和为不同序列在第n次迭代时的总体相关评估强度,sohi为第i个时间戳的健康指标值,为trend的平均值,为soh的平均值。
68、上述进一步方案的有益效果是:通过上述技术方案,获得白噪声高频占比以及seasonality分量、trend分量和数据曲线的关联强度,实现序列演化规律和波动频率的无监督学习。
69、进一步地,s4中通过搭建矩阵运算逻辑,构建时间戳强约束的时序预测训练集合,包括以下公式:
70、根据季节趋势分量,通过矩阵点积运算构建一阶训练集tsf'为
71、
72、
73、其中,tsr为特征分量,p为2×3阶矩阵,上标t为矩阵的转置,⊙为同或运算符;
74、锂离子电池数据集合中,基于序列周期cycle和采集频率af构建的时间戳time位于维度为13的第12列,基于实际电容c构建的soh评估参数位于第13列,自注意力机制在信息加权时要设定时间特性的数学假设,其中,一对一映射的时间戳time标签列能够表现时间依赖性,soh标签设定为建模的目标参数,在训练阶段用于深度模型的负反馈优化,测试阶段用于预测性能评估,提取参数的矩阵点积公式为
75、
76、其中,q为2×13阶矩阵;
77、基于一阶训练集tsf',通过矩阵点积运算构建二阶训练集tsf”为
78、
79、上述进一步方案的有益效果是:通过上述技术方案,利用矩阵点积运算构建时序预测训练集合,点积(多重复制)注意力函数,其计算规则与传统self-attention的运算规则一致,在实践中,点积注意力的运行时效性表现很优秀,速度更快,空间效率更高。
80、进一步地,s5中设计lbtsa深度模型利用嵌套的建模架构机制,融合self-attention机制的序列加权及lstm神经网络的远距离信息继承,实现针对lstm单元门控机制和seq2seq架构的优化,所述嵌套的建模架构机制,基于lstm神经网络的seq2seq架构实现,包括以下分步骤:
81、s5-1:将lstm神经网络的概念化模型拆分为编码器和解码器,利用lstm encoder对特征训练集tsf进行序列编码,利用门控输出针对时间戳time、trend和seasonality列进行计算,隐藏状态针对soh列进行计算,得到全局时间步的序列输出和最后时间步的隐藏状态,包括以下公式:
82、采用点积注意力加权算法,并构建了基于点积注意力加权算法的lstm解码器模型lbtsa,所述点积注意力加权算法构建query,key,value矩阵向量为
83、
84、其中,query、keyi和valuei为抽象向量,hd为隐藏状态,qi为第i个观测值的特征向量,ωq、ωk和ωv为神经网络的参数;
85、s5-2:利用self-attention算法建立序列输出和隐藏状态间的自注意机制,基于序列输出对隐藏状态关联度的加权操作,得到融合自注意力机制的序列矩阵,包括以下公式:
86、基于抽象向量query,key,value构建注意力得分矩阵g为
87、
88、其中,dk为key的维度;
89、为缩放因子,防止内积数值过大影响lbtsa深度模型的无监督自适应学习机制;
90、针对各时间步特征向量构建的注意力权重矩阵a为
91、
92、其中,gi为时间步为i时注意力得分矩阵的列向量,exp为针对注意力得分矩阵的运行以e为底的指数运算;
93、lbtsa深度模型的self-attention算法构建加权序列z2(q,k,v)为
94、
95、s5-3:利用lstm decoder对序列矩阵进行解码,得到预测序列。
96、上述进一步方案的有益效果是:通过上述技术方案,解决了结构化长周期序列预测的数据稀疏性敏感问题,实现了长序预测的性能优化。
- 还没有人留言评论。精彩留言会获得点赞!