一种面向结构化数据的稠密向量检索方法
本发明涉及结构化数据检索,尤其涉及一种面向结构化数据的稠密向量检索方法。
背景技术:
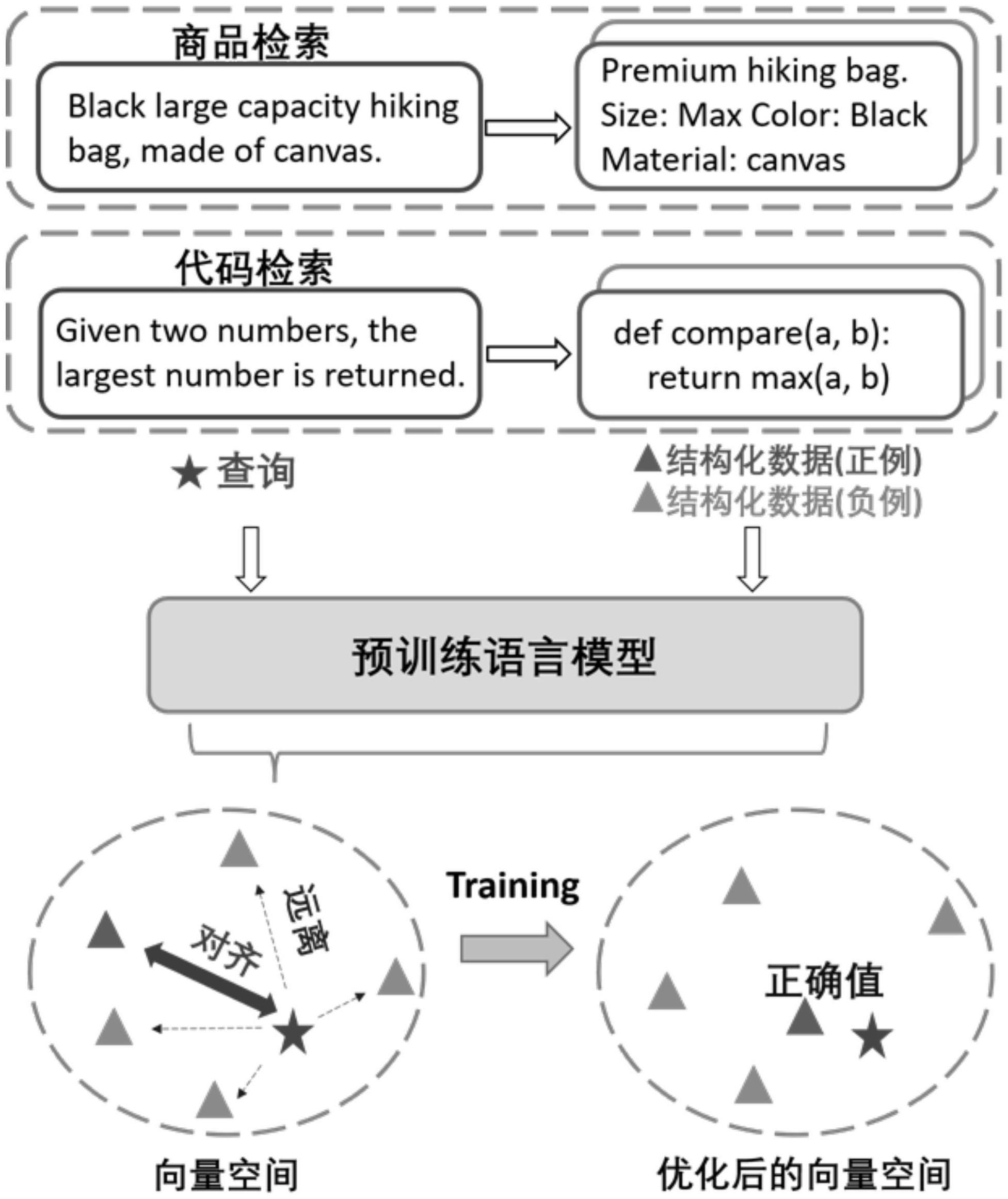
1、稠密检索已在许多自然语言处理应用中表现出强大的效果,例如开放领域问答、对话搜索和事实验证。给定用户查询和数据文档,稠密检索器使用语言模型对查询和数据文档进行编码,将它们映射到向量空间中进行匹配,并返回满足用户查询需求的数据文档。但是现实中存在许多结构化数据检索场景,例如:代码检索和商品检索任务。这些结构化数据检索任务要求语言模型按照稠密检索的方式为用户查询检索相应的结构化数据,来获得用户需要的结构化数据项。因此学习表示结构化数据对于构建更完备的检索系统至关重要。
2、―zhangyin feng,dayaguo,duyu tang,nan duan,xiaocheng feng,ming gong,linjunshou,bing qin,ting liu,daxin jiang,and ming zhou.2020.codebert:a pre-trained model for programming and natural languages.in findings of theassociation for computational linguistics:emnlp 2020,pages1536–1547.”中,codebert是第一个大型自然语言-编程语言预训练模型,该预训练模型能够处理许多自然语言-编程语言问题,例如用自然语言搜索代码、生成代码等。在模型训练的设计上,主要包括两个训练目标,其一是掩码语言建模,其二是可替换字符检测。目标一:掩码语言建模。将自然语言-编程语言对作为输入,随机挑选自然语言和编程语言中的字符并且使用特殊的掩码字符进行替换。目标二:替换词检测,和electra做法相似。但是codebert的缺陷在于基本上沿用了非结构化数据的预训练思路,即传统的掩码语言建模和基于electra的对抗学习。并没有针对结构化数据蕴含的结构信息提出相应的预训练策略。
3、―zhangyin feng,dayaguo,duyu tang,nan duan,xiaocheng feng,ming gong,linjunshou,bing qin,ting liu,daxin jiang,and ming zhou.2020.codebert:a pre-trained model for programming and natural languages.in findings of theassociation for computational linguistics:emnlp 2020,pages 1536–1547.”中,codet5是一个统一的预训练编码器-解码器模型,在模型的整体架构上和t5相同。它可以更好地利用开发人员分配的标识符中所传达的代码语义。模型采用统一的框架来支持代码理解和生成任务,并建模多种代码学习任务。同时还提出了一种新的标识符感知预训练任务,使模型能够区分哪些代码字符是标识符。此外,还利用用户编写的代码注释和双峰双生成任务进行更好的自然语言-编程语言对齐。但是codet5的缺陷在于没有很好的学习到结构化数据的向量表示。codet5虽然仿照之前的无监督训练方式,针对特定结构化数据设计了特定的掩码策略,和独特的生成式对齐任务,但没有进行有效的结构化数据表示学习,限制了模型在结构化数据检索任务上的性能。
4、―xiaonan li,yeyun gong,yelong shen,xipengqiu,hang zhang,bolun yao,weizhen qi,daxin jiang,weizhu chen,and nan duan.2022.coderetriever:large-scale contrastive pre-training for code search.”中,coderetriever针对代码检索任务提出了单模态和双模态的对比学习策略,在模型架构上和起始参数上与graphcodebert相同。对于单模态的对比学习,以无监督的方式根据代码中的自然语言信息,来构建具有相似功能的代码对。对于双模态的对比学习,则利用代码的文档和存在于代码中的零散注释来构建代码文本对。但是coderetriever的缺陷在于仅仅针对跨模态的数据和同模态的数据进行了对比学学习,初步优化了结构化数据的向量表示,并没有进一步针对结构化数据的结构信息进行学习,使得其结构感知能力还不够强。
技术实现思路
1、本发明所要解决的技术问题是:如何设计一种新的面向结构化数据的稠密向量检索模型,有效的理解和学习结构化数据中潜在的结构知识,以提高检索结构化数据的效果。基于上述技术问题,本发明的目的就是提出一种能够利用当前预训练语言模型潜在的能力,通过继续训练语言模型使其具有结构感知能力,更加适用于结构化数据的检索任务。为了弥合结构化和非结构化数据之间的模态差距来更好的表示结构化数据,使用结构化数据对齐任务来训练语言模型,在向量空间中对齐匹配的结构化和非结构化数据。同时为了进一步的从结构化数据中捕获语义信息,采用掩码实体预测任务用于掩码结构化数据中实体,训练语言模型预测结构数据中被掩码部分。
2、本发明的技术方案:一种面向结构化数据的稠密向量检索方法,具体包括步骤如下:
3、步骤1:建立语言模型结构,以t5模型为基础架构;所述t5模型基于标准的transformer结构;
4、步骤2:数据处理;收集结构化数据和非结构化数据对,识别结构化数据中的实体;
5、步骤3:结构化数据和非结构化数据对齐;通过对现有的结构化数据和非结构化数据作对比学习训练语言模型,优化语言模型中的向量空间;
6、步骤4:实体掩码预测;对步骤2所识别的结构化数据中的实体采用掩码语言建模的方式来训练语言模型,进一步优化语言模型中的向量空间;
7、所述步骤2具体为:
8、步骤2.1:数据收集,从现有的开源数据集收集预训练数据,在代码检索和商品检索两个检索景上收集相应的结构化数据和非结构化数据对;
9、步骤2.2:数据处理,对于收集到的预训练数据,解析结构化数据,获取结构化数据中的实体;
10、对于代码检索场景,收集代码数据,包括结构化的代码语言数据以及对应非结构化的文档描述;对于商品检索场景,收集商品数据,包括结构化的商品描述数据和非结构化的商品要点数据。
11、所述结构化的代码语言数据中,代码中的标识符为实体,通过tree_sitter工具识别获取代码中的标识符;所述标识符包括代码的变量、函数名、外部库和方法;所述结构化的商品描述数据中,同时出现在商品描述和商品标题中的名词以及特殊名词为实体,通过nltk工具识别获取名词以及特殊名词;所述名词和特殊名词用于描述商品的属性。
12、所述步骤3具体为:
13、步骤3.1:根据步骤2的数据构造,对于每条结构化数据,均对应有与其具有相同语义的非结构化数据;步骤1中选取的语言模型分别将非结构化数据和结构化数据编码为向量;对于非结构化数据,将其和对应的结构化数据视为正样本对,和其余的结构化数据视为负样本对;通过交叉熵损失函数对比学习,在语言模型的向量空间中拉近正样本对,分离负样本对;
14、步骤3.2:通过上述对比学习得到的损失值反向传播来更新语言模型的参数,对齐结构化数据和非结构化数据,优化语言模型的向量空间;
15、所述步骤4具体为:
16、步骤4.1:在实体预测任务中,通过恢复被掩码的实体来指导语言模型更好地理解结构化数据的语义。对于步骤2中识别出来的实体,使用来自t5模型的特殊标记替换他们,得到被掩码的结构化数据,并将这些实体组合为实体序列;对于一条结构化数据:{x1,x2,ent1,x3,ent2,…,xn},在结构化数据文档中出现的实体使用所述特殊标记掩码得到被掩码实体的结构化数据:
17、x3,<extra_id_1>,…,xn},从步骤
18、2获得的实体则按照如下形式组合作为实体序列:yd={<extra_id_0>,ent1,…,<extra_id_n>,entn},其中<extra_id_i>表示第i+1个被掩码的实体,x为结构化数据中的其它词,ent为步骤2.2中识别出来的实体;通过上述方式得到被掩码实体的结构化数据和对应的实体序列;我们将上述被掩码的结构化数据作为语言模型的编码器端输入,实体序列作为语言模型解码器端预测结果,然后得到语言模型预测的实体;
19、步骤4.2:语言模型的编码器将输入的被掩码实体的结构化数据编码为上下文向量,并输入到解码器中自回归地逐个预测并生成所述被掩码实体,得到预测实体序列;通过交叉熵损失函数得到预测的实体和真实实体之间的损失值,进一步优化语言模型,从而更好地捕捉实体信息,理解结构化数据的语义;
20、所述特殊标记来自t5模型的词表,形式为{<extra_id_0>,<extra_id_1>,...,<extra_id_99>}。
21、本发明的有益效果:本发明所提出的预训练方法,在代码检索和商品检索方面取得了最先进的效果。从实验结果来看,我们的模型在多个代码检索数据集,包括ruby,javascript,go,python,java,php在内的六种编程语言上都取得了很好的效果,超过了包括coderetriever在内的多个代码预训练语言模型。同时在商品检索数据集上也获得了很好的结果,超过了现有的预训练语言模型。此外我们的模型还具有很强的零样本能力,在一些数据集上甚至超过了其它模型微调后的效果。
- 还没有人留言评论。精彩留言会获得点赞!