一种多视角全身人体图像生成方法
本发明属于图像生成与计算机图形学领域,具体涉及到一种多视角人体图像生成方法。
背景技术:
1、近年来,生成对抗网络(generative adversarial networks,gan)被广泛用于生成高分辨率的、高质量的逼真图像。其中,stylegan被提出并且成为了先进的无条件图像生成模型。相比较于先前的生成模型,stylegan将单独的属性因子(即样式)注入生成器,以影响生成图像的外观。在这之后,stylegan2重新设计了归一化、多尺度方案和正则化方法,以校正stylegan模型所生成的图像中的伪影。最新的stylegan3模型揭示了细节纹理出现在固定像素位置的非理想情况,并提出了无别名网络。
2、如今,如何将传统gan的生成能力拓展到3d层面受到越来越多的关注,如何生成多视角一致的图像以及如何生成对应图像中的3d形状被广泛研究。随着神经辐射场(neuralradiance field,nerf)的发展,许多工作如graf、giraffe、stylenerf尝试将其引入到gan中,以增强生成图像的多视角一致性。giraffe将神经辐射场与卷积结构的解码器结合在一起,以此提升训练和渲染效率。stylenerf则采用类似stylegan结构的网络生成神经辐射场,以实现对于样式更精准的控制。stylesdf使用有向距离场替代神经辐射场中的密度,进一步提升了几何一致性。
3、尽管现有的生成模型在人脸生成、物体生成方面取得了巨大进步,全身人体图像的生成依然是一个十分困难的任务。不同人之间的高矮、胖瘦等身体形态各不相同,且人体的姿态复杂多变,这些都加大了生成难度。一方面,受限制于训练使用的数据,这些方法生成的图像质量往往不佳;另一方面,由于缺乏严格的3d建模环节,这些方法也难以确保较为准确的人体图像几何一致性。此外,如何控制生成过程,使得能指定生成的人体图像中人体的姿态,也是一个技术难点。
技术实现思路
1、为了解决现有技术中的上述问题,本发明提出了一种多视角人体图像生成方法,与现有的图像生成模型不同,本发明构造的生成模型能指定生成图像中人体的姿态,并可生成不同视角下的人体图像。
2、该方法包括如下步骤:
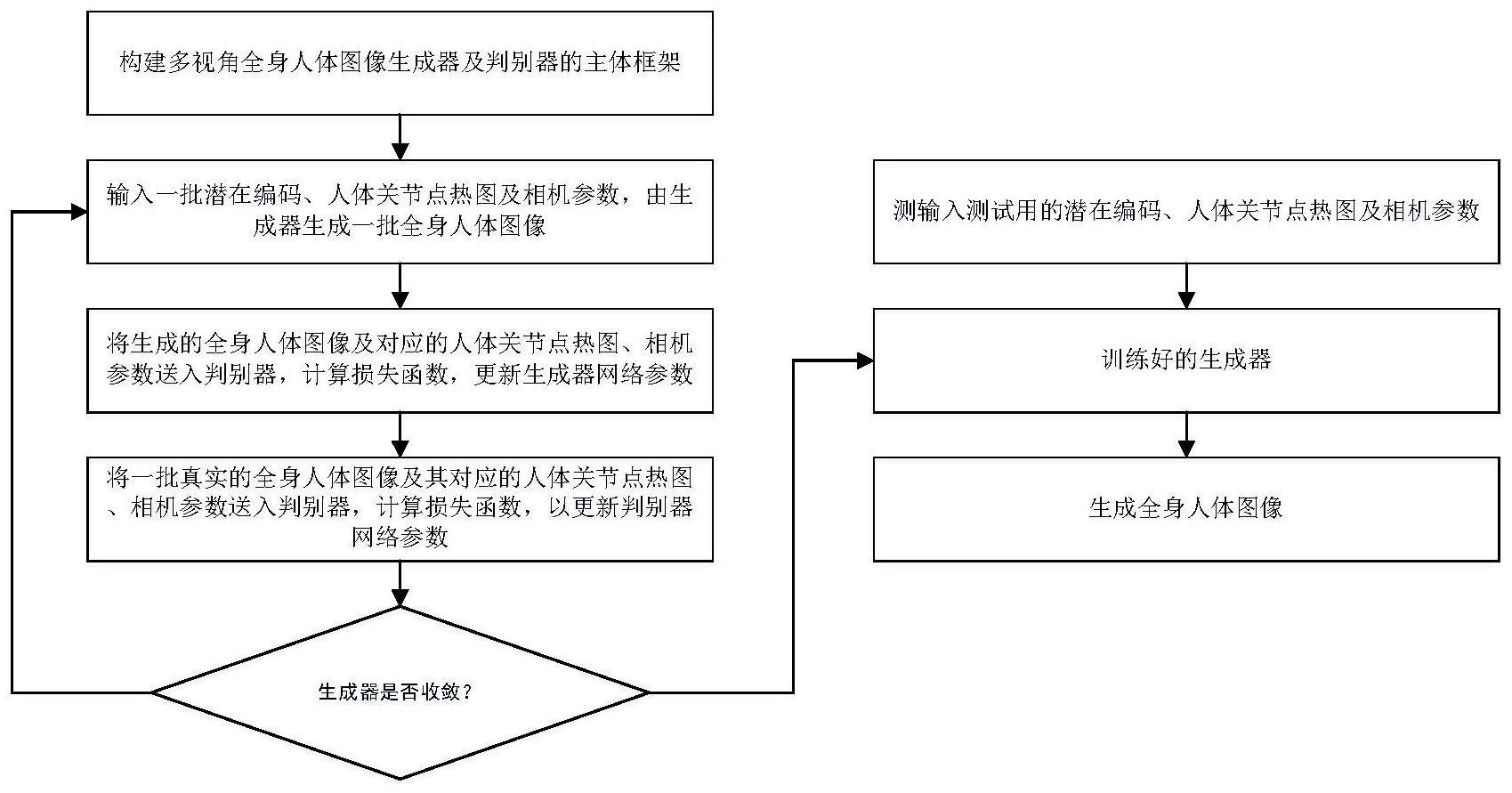
3、步骤1,构建多视角全身人体图像生成器及判别器的主体框架;
4、步骤2,输入一批潜在编码、人体关节点热图及相机参数,由生成器生成一批全身人体图像;
5、步骤3,将生成的全身人体图像及对应的人体关节点热图、相机参数送入判别器,计算损失函数,以更新生成器网络参数;
6、步骤4,将一批真实的全身人体图像及其对应的人体关节点热图、相机参数送入判别器,计算损失函数,以更新判别器网络参数,完成一次网络训练;
7、步骤5,重复步骤2到步骤4,直至训练收敛,得到最终的全身人体图像生成器;步骤6,在测试阶段,把潜在编码、人体关节点热图及相机参数输入最终的生成器,得到生成的全身人体图像。
8、优选地,所述步骤1需要构造多视角人体图像生成器的主体框架。生成器包含姿态编码器、骨干网络、体渲染模块以及超分辨率模块。
9、姿态编码器由多个残差模块组成,能提取人体关节点热图中的有效信息,为生成过程提供引导,减少生成难度;
10、骨干网络为stylegan2生成器结构,包括一个映射网络及多层上采样模块,其输入为潜在编码、人体关节点热图及相机参数,能生成中间表征,用于体渲染;骨干网络输出的特征图经空间变换,转化为三平面表征,该表征在保证信息有效性的同时,节省了存储空间,提升了生成器生成效率,使得生成的特征图包含更多有效信息,且同时保证生成器较快的运算速度;
11、体渲染模块采用相机参数进行光线采样,在三平面表征提取特征,以渲染得到特征图像,体渲染使得在测试阶段能通过输入不同的相机视角参数,控制生成的人体图像的观察视角,体渲染模块用于渲染小尺寸的人体图像,经过超分辨率模块得到大尺寸的人体图像,该设计能大大减少生成器计算需求,加快推理速度;
12、超分辨率模块以特征图像为输入,输出上采样8倍分辨率后的全身人体图像,该模块使得体渲染无需直接渲染大尺寸图像,大大提升了生成器运行速度;
13、生成器总体输入包括人体关节点热图,使得在推理阶段,能通过输入不同的关节点热图控制生成图像中的人体姿态。
14、优选地,所述步骤1需要构造多视角人体图像判别器的主体框架。判别器为stylegan2判别器结构,其输入为全身人体图像、人体关节点热图及相机参数,输出图像为真实图像的概率值,该判别器能捕获不同尺度的图像信息,更有效地判断生成的人体图像是否真实,保证了生成的全身人体图像质量,同时也使得生成的人体图像与输入的人体关节点热图相匹配。
15、优选地,所述步骤2中,潜在编码由随机对高斯分布进行采样取得,该高斯分布均值为0,方差为1,每个潜在编码为随机采样512次构成的512维向量,该潜在编码使得生成器在测试阶段能便捷地控制输入。
16、优选地,所述步骤2中,潜在编码与相机参数首先堆叠到一起,构成一个537维的向量,作为调制信号送入生成器。额外送入相机参数能使得生成器建模与视角相关的信息,由此生成过程能额外受到视角信息的引导,有利于生成器建模视角相关的信息,能增强生成图像中细节的质量。
17、优选地,所述步骤2中,人体关节点热图经过姿态编码器处理后送入生成器,能引导生成过程,减小生成器生成难度。
18、优选地,所述步骤2中,相机参数为25维向量,前9个数值表示相机内参,后16个数值表示相机外参,对于所有图像,相机内参均固定为相同值,以此减小生成器生成中间表征的难度,提升最终图像的生成质量。
19、优选地,所述步骤3及步骤4中,人体图像与人体关节点热图首先堆叠在一起,然后送入判别器。该堆叠使得判别器能判断生成的人体图像是否与输入的人体关节点热图相匹配。其中,步骤3中提出一种三重判别法,渲染得到的人体图像、超分辨率后的人体图像以及人体关节点热图首先堆叠在一起,构成维度为7×512×512的特征,之后送入判别器;相机参数作为调制信号,送入判别器。人体图像与人体关节点热图的堆叠使得生成的人体图像与输入的人体关节点热图相匹配。相机参数的引入使得判别器能获取更多视角信息,有助于判断生成的人体图像是否真实。此外,相比较于其他条件判别方法,堆叠减少了计算量,提升了判别器运算速度。
20、优选地,所述步骤5中,由于损失函数无法直接显示出生成器收敛状态,使用fréchet inception distance(fid)指标以及kernel inception distance(kid)指标评估生成器是否收敛,当fid指标和kid指标下降到较低的数值,并在小范围内振荡时,认定为生成器已收敛,停止训练。
21、本发明的有益效果在于:解决了全身人体图像生成质量不足、真实性低的技术问题,能控制生成的全身人体图像的人体姿态,以及生成某种人体的多视角图像,同时实现了较快的生成速度;此外,本发明还能应用到虚拟现实、影视娱乐、数字人体等领域。
- 还没有人留言评论。精彩留言会获得点赞!