一种虚拟谈话数字人生成方法
本发明涉及数据处理,特别是涉及一种虚拟谈话数字人生成方法。
背景技术:
1、随着人工智能技术的迅速发展与普及,虚拟数字人技术逐渐成熟,并慢慢地进入人们的日常生活中。然而目前大量的虚拟数字人基本上以人造形象为主,该形象不是动漫角色就是对真人的模拟(存在大量肉眼可见的不真实的外表)。目前以现实生活中的真人形象设计的虚拟谈话数字人主要应用在主持人播报场景下。
2、传统的虚拟谈话数字人形象往往倾向于先建立数字人的三维形象,接着对该三维形象上贴上不同的纹理,再根据不同的音频条件驱动三维结构的变形,然后渲染出不同的图像。该方案往往在渲染出的图像上失真,无法达到现实生活中人物图像那般复杂的纹理结构,只对动漫形象较为简单化的形象具有较好的效果。
3、近年来,随着深度学习神经网络在虚拟数字人领域不断的探索应用,传统方案的保真性得到了很大程度的解决,但随之带来的超大计算量,使得传统方案无法做到实时驱动,这对人机交互应用就带来巨大挑战。另一条深度学习数字人路线为驱动图像的变形,在实时驱动和形象保真两方面取得了平衡。本发明沿用该路线发明出语音驱动下形象逼真的实时谈话虚拟数字人。
技术实现思路
1、本发明的目的在于提供一种虚拟谈话数字人生成方法,能够得到形象更加逼真、更接近现实生活中人物的谈话虚拟数字人。
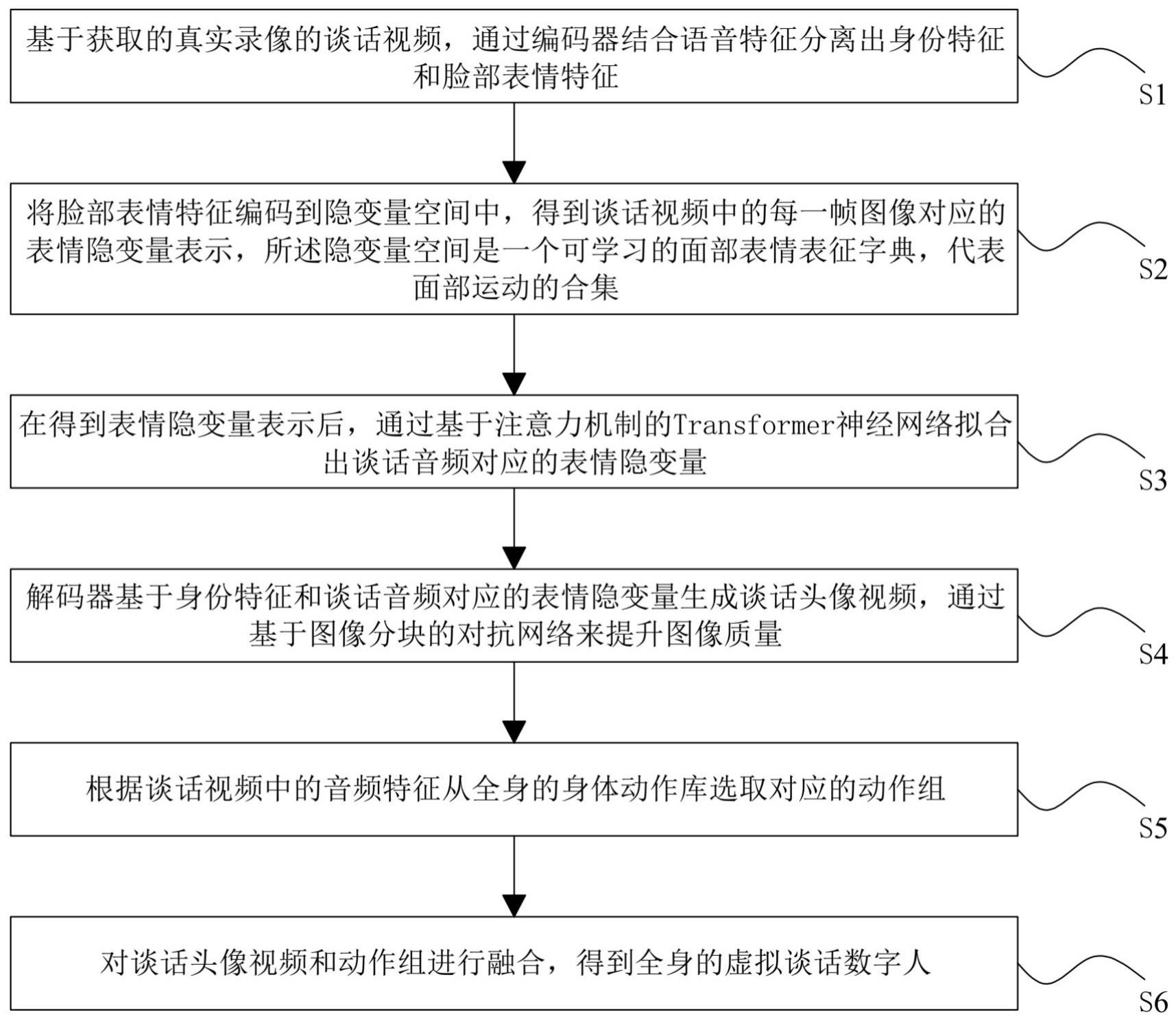
2、一种虚拟谈话数字人生成方法,包括以下步骤:
3、s1,基于获取的真实录像的谈话视频,通过编码器结合语音特征分离出身份特征和脸部表情特征;
4、s2,将脸部表情特征编码到隐变量空间中,得到谈话视频中的每一帧图像对应的表情隐变量表示,所述隐变量空间是一个可学习的面部表情表征字典,代表面部运动的合集;
5、s3,在得到表情隐变量表示后,通过基于注意力机制的transformer神经网络拟合出谈话音频对应的表情隐变量;
6、s4,解码器基于身份特征和谈话音频对应的表情隐变量生成谈话头像视频,通过基于图像分块的对抗网络来提升图像质量;
7、s5,根据谈话视频中的音频特征从全身的身体动作库选取对应的动作组;
8、s6,对谈话头像视频和动作组进行融合,得到全身的虚拟谈话数字人。
9、根据本发明提供的虚拟谈话数字人生成方法,利用编码器自适应分离出身份特征与脸部表情特征,相对于人工标注的特征点表情或脸部运动肌肉特征,具有更丰富的语义表达能力;本发明将高维的脸部表情特征编码到低维的隐变量空间中,能够在最少地牺牲表示精度的情况下,压缩表情特征维度,为利用谈话音频拟合出表情隐变量提供了更好的条件;然后解码器基于身份特征和谈话音频对应的表情隐变量生成谈话头像视频,再根据谈话视频中的音频特征从动作库选取对应的动作组,并对谈话头像视频和动作组进行融合,得到虚拟谈话数字人,使得本发明能够得到形象更加逼真、更接近现实生活中人物的谈话虚拟数字人,具有实时性,形象逼真,音唇同步率高的特点。
10、此外,上述的虚拟谈话数字人生成方法,还具有以下技术特征:
11、进一步的,步骤s1具体包括:
12、s11,将获取的真实录像的谈话视频分离出每一帧图像,将每一帧图像中的人像根据眼部位置及嘴部位置裁剪并对齐头像位置,以得到多个谈话头像图片;
13、s12,对得到的谈话头像图片提取对应的音频信号特征,根据音频信号特征和对应身份的无表情头像图片获取表情掩码特征;
14、s13,编码器根据获取的表情掩码特征分离谈话头像图片的身份特征和脸部表情特征。
15、进一步的,步骤s2具体包括:
16、s21,设计一个可学习的面部表情表征字典,将获取到的脸部表情特征投影到该面部表情表征字典的线性组合空间中;
17、s22,联合优化面部表情表征字典及其线性组合系数,使面部表情表征字典能最大程度表示脸部表情特征,从而得到谈话视频中的每一帧图像对应的表情隐变量表示,进而得到包含了所有面部表情的动作合集。
18、进一步的,步骤s3具体包括:
19、s31,根据步骤s2获取到的每一帧图像对应的表情隐变量表示,将其聚合到谈话视频的面部表情表征字典空间中作为训练时的监督;
20、s32,获取谈话视频中的每一帧图像的对应的音频信号特征,设计一个基于注意力机制的transformer神经网络,其输入为每一帧和其前面所有的图像对齐的音频信号特征,输出为这一帧图像的面部表情表征字典空间的拟合结果,迭代训练该神经网络,使拟合结果与步骤s31中的结果误差达到最小;
21、s33,将谈话视频中的谈话音频输入到循环神经网络中,获取到谈话音频的表情隐变量,在测试时,将任意一段音频输入到神经网络中,获取到该音频未在面部表情表征字典空间中的表情隐变量。
22、进一步的,步骤s4具体包括:
23、s41,根据步骤s3的谈话音频对应的表情隐变量,结合步骤s2的面部表情表征字典重建高维表情特征;
24、s42,解码器将步骤s41得到的高维表情特征结合步骤s1获取到的身份特征,生成出说话者在一段谈话音频下的对应视频;
25、s43,采用基于图像块的对抗网络,提升说话人图像的图像质量,并基于提升图像质量后的说话人图像生成谈话头像视频。
26、进一步的,步骤s5具体包括:
27、s51,拍摄人体躯干运动视频,将运动视频分离出每一帧运动图像,并从每一帧运动图像中分离出头部与躯干,建立人体驱干运动动作库;
28、s52,分析谈话视频中的每一帧图像的对应的音频信号特征,根据音频信号特征中的时长特征、说话的语气情绪特征,从人体驱干运动动作库中选取对应的动作组。
29、进一步的,步骤s6具体包括:
30、s61,将步骤s4获取到的谈话头像视频和步骤s5获取到的动作组对齐头部位置和躯干位置,将谈话头像视频对应的图片和动作组对应的图片进行融合,得到拼接图片;
31、s62,对拼接图片做拼接后处理,利用图像混合技术对拼接位置的色差和位置偏差进行消除,从而得到全身的虚拟谈话数字人。
技术特征:
1.一种虚拟谈话数字人生成方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的虚拟谈话数字人生成方法,其特征在于,步骤s1具体包括:
3.根据权利要求2所述的虚拟谈话数字人生成方法,其特征在于,步骤s2具体包括:
4.根据权利要求3所述的虚拟谈话数字人生成方法,其特征在于,步骤s3具体包括:
5.根据权利要求4所述的虚拟谈话数字人生成方法,其特征在于,步骤s4具体包括:
6.根据权利要求5所述的虚拟谈话数字人生成方法,其特征在于,步骤s5具体包括:
7.根据权利要求6所述的虚拟谈话数字人生成方法,其特征在于,步骤s6具体包括:
技术总结
一种虚拟谈话数字人生成方法,包括:S1,基于获取的真实录像的谈话视频,通过编码器结合语音特征分离出身份特征和脸部表情特征;S2,将脸部表情特征编码到隐变量空间中,得到谈话视频中的每一帧图像对应的表情隐变量表示;S3,在得到表情隐变量表示后,通过基于注意力机制的Transformer神经网络拟合出谈话音频对应的表情隐变量;S4,解码器基于身份特征和谈话音频对应的表情隐变量生成谈话头像视频;S5,根据谈话视频中的音频特征从全身的身体动作库选取对应的动作组;S6,对谈话头像视频和动作组进行融合,得到全身的虚拟谈话数字人。本发明能够得到形象更加逼真、更接近现实生活中人物的谈话虚拟数字人。
技术研发人员:李波,魏啸林,刘彬,陈伟峰,熊小环,赵旭
受保护的技术使用者:南昌航空大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!