一种基于NLP的涉密屏蔽方法与流程
本发明涉及电数字数据处理,具体涉及一种基于nlp的涉密屏蔽方法。
背景技术:
1、随着网络的迅速发展,个人言论可借助互联网的平台进行发布,使得企业的涉密信息容易遭到泄露,对于企业造成不可挽回的损失。因此,为了限制个人在网络上发表不利于他人的言论,现有自然语言处理nlp可用于自动屏蔽不当言论。
2、现有自然语言屏蔽方法通过标注敏感词的方式,构建训练样本集,再用训练样本集训练神经网络,采用训练后的神经网络进行分类,从而区分该自然语言是否包含敏感词或者非敏感词。现有自然语言屏蔽方法的分类精度取决于敏感词,在存在敏感词时其屏蔽精度较高,但对于语句屏蔽精度较低。
技术实现思路
1、针对现有技术中的上述不足,本发明提供的一种基于nlp的涉密屏蔽方法解决了现有自然语言屏蔽方法存在语句屏蔽精度较低的问题。
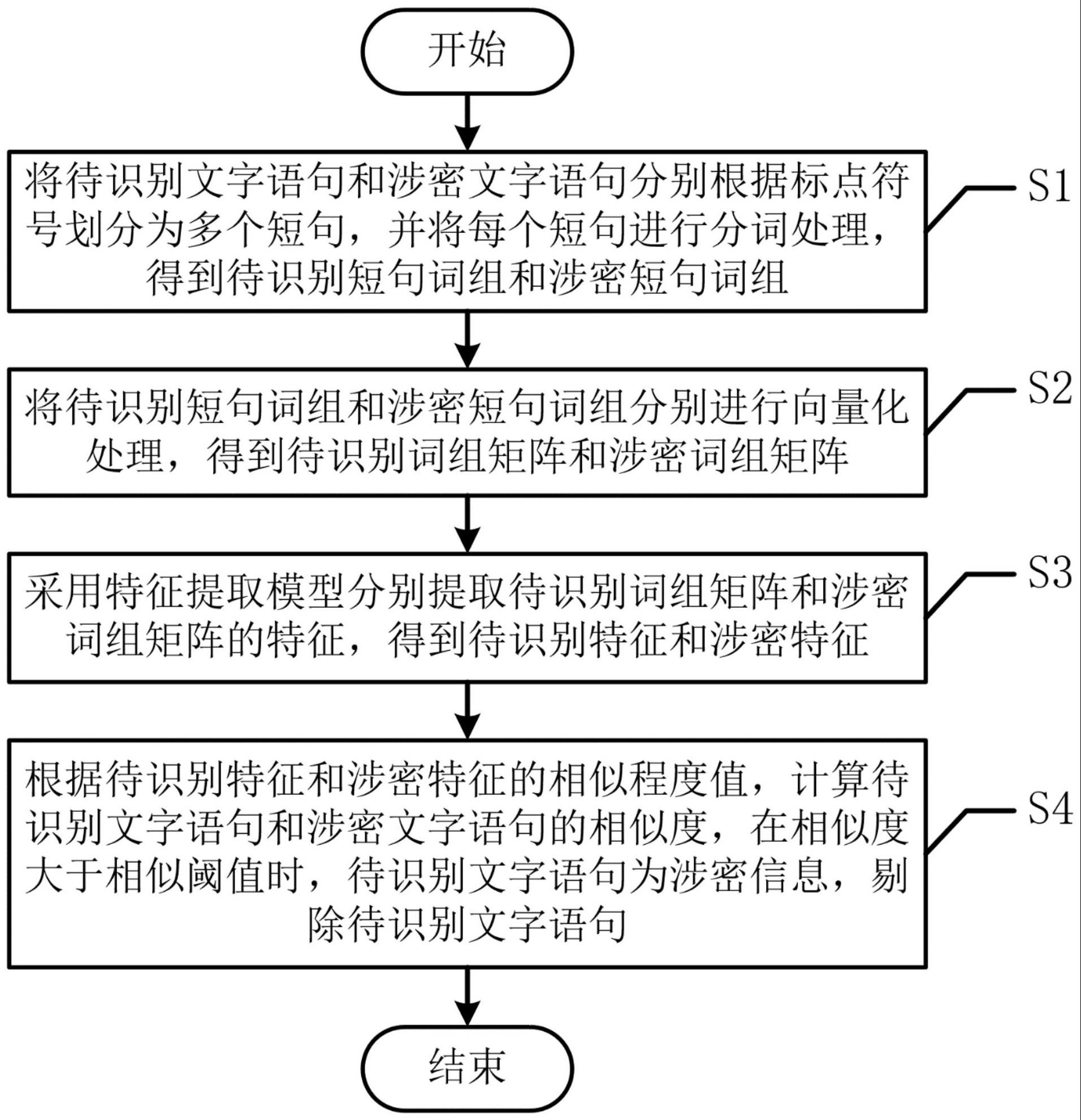
2、为了达到上述发明目的,本发明采用的技术方案为:一种基于nlp的涉密屏蔽方法,包括以下步骤:
3、s1、将待识别文字语句和涉密文字语句分别根据标点符号划分为多个短句,并将每个短句进行分词处理,得到待识别短句词组和涉密短句词组;
4、s2、将待识别短句词组和涉密短句词组分别进行向量化处理,得到待识别词组矩阵和涉密词组矩阵;
5、s3、采用特征提取模型分别提取待识别词组矩阵和涉密词组矩阵的特征,得到待识别特征和涉密特征;
6、s4、根据待识别特征和涉密特征的相似程度值,计算待识别文字语句和涉密文字语句的相似度,在相似度大于相似阈值时,待识别文字语句为涉密信息,剔除待识别文字语句。
7、进一步地,所述s3中特征提取模型包括:第一卷积特征提取网络、第二卷积特征提取网络、第三卷积特征提取网络、特征融合单元、第一时间递归网络和第二时间递归网络;
8、所述第一卷积特征提取网络的输入端分别与第二卷积特征提取网络的输入端、第三卷积特征提取网络的输入端和特征融合单元的第四输入端连接,并作为特征提取模型的输入端,用于输入待识别词组矩阵或涉密词组矩阵;所述特征融合单元的第一输入端与第一卷积特征提取网络的输出端连接,其第二输入端与第二卷积特征提取网络的输出端连接,其第三输入端与第三卷积特征提取网络的输出端连接,其输出端与第一时间递归网络的输入端连接;所述第一时间递归网络的输出端与第二时间递归网络的输入端连接;所述第二时间递归网络的输出端作为特征提取模型的输出端。
9、进一步地,每个所述卷积特征提取网络均包括:卷积层、全局平均池化层、全局最大池化层和concat层;
10、所述卷积层的输入端作为卷积特征提取网络的输入端,其输出端分别与全局平均池化层的输入端和全局最大池化层的输入端连接;所述concat层的输入端分别与全局平均池化层的输出端和全局最大池化层的输出端连接,其输出端作为卷积特征提取网络的输出端。
11、上述进一步地方案的有益效果为:本发明中设置四条路径用于特征在空间位置的融合,通过三个卷积层分别提取不同特征,再设置全局最大池化层提取显著特征,设置平均池化层提取整体特征,这三条路径实现对不同特征进行提取,concat层将提取后的特征进行拼接,在第一个乘法器处,实现两条路径上的特征在空间位置的融合,为了避免信息丢失和损耗的问题,第四条路径直接将输入连接到第二转置层,保护信息的完整性,解决网络过深所引起的梯度消失问题和退化问题。
12、进一步地,所述特征融合单元包括:第一转置层、第二转置层、第一乘法器、第二乘法器和加法器;
13、所述第一转置层的输入端作为特征融合单元的第一输入端,其输出端与第一乘法器的第一输入端连接;所述第一乘法器的第二输入端作为特征融合单元的第二输入端,其输出端与加法器的第一输入端连接;所述第二转置层的输入端作为特征融合单元的第四输入端;所述第二乘法器的第一输入端作为特征融合单元的第三输入端,其第二输入端与第二转置层的输出端连接,其输出端与加法器的第二输入端连接;所述加法器的输出端作为特征融合单元的输出端。
14、进一步地,所述时间递归网络的表达式为:
15、
16、
17、其中,为时间递归网络第时刻的输出,为双曲正切激活函数,为中间变量,为时间递归网络第时刻的输入,为哈达玛积,为时间递归网络第时刻的输出,为输入权重,为输入偏置,为输出权重,为输出偏置,为传输权重,为传输偏置,为s形激活函数。
18、上述进一步地方案的有益效果为:本发明利用时间递归网络的记忆性更好的提取用户语义,本发明的时间递归网络的输入包括:和,对和分别赋予权重和偏置,从而实现对和分别进行控制,再采用激活函数选择和提取的部分,在输出时,建立、和与输出的模型关系,使得输出充分考虑和,提高特征提取的精度。
19、进一步地,所述s3中特征提取模型的损失函数为:
20、
21、
22、其中,为特征提取模型第次训练时损失函数的输出,为特征提取模型第次训练时的输出,为特征提取模型第次训练时的标签,为自然对数,为指数系数。
23、上述进一步地方案的有益效果为:本发明中采用标签的平方和输出的平方减去二倍标签和输出的乘积,从而体现出标签与输出的差距,同时为了使得训练时,模型训练速度快,模型快速收敛,本发明还设置了指数系数,在指数系数中通过比值来体现两者的差距,在比值越大时,两者差距越大,在比值等于1时,输出与标签相等,即本发明通过输出与标签在数据上差距体现两者差距,再通过比值反应差距的程度,将比值通过指数函数放大后作用于差距上,进一步地使得损失值增加,从而达到快速训练特征提取模型的目的。
24、进一步地,所述s4中计算相似度的公式为:
25、
26、其中,为待识别文字语句和涉密文字语句的相似度,为第个待识别特征的相似程度值,为待识别文字语句对应的待识别特征的数量,为待识别文字语句对应的待识别特征中相似程度值大于等于0.5的待识别特征的数量,为待识别文字语句对应的待识别特征中相似程度值小于0.5的待识别特征的数量。
27、上述进一步地方案的有益效果为:本发明中将待识别文字语句中每个待识别特征的相似程度值进行叠加,体现整个文字语句与涉密文字语句的相似情况,同时,统计相似程度值大于等于0.5的待识别特征的数量和相似程度值小于0.5的待识别特征的数量,将两者数量的差距作为相似情况的指数,使得各个文字语句的相似度区别明显,更容易判断出文字语句是否为涉密信息,在大于等于时,即相似的短句占比更多,因此,该文字语句更容易被判定为涉密信息,在小于,即不相似的短句占比更多,该文字语句更容易被判定为非涉密信息,在越小于时,该文字语句的相似度越低。
28、进一步地,所述待识别特征的相似程度值的计算公式为:
29、
30、其中,为取序列的最大值,为第个待识别特征,为第1个涉密特征,为第个涉密特征,为第个涉密特征,为涉密文字语句中对应的涉密特征的数量。
31、上述进一步地方案的有益效果为:本发明中将每个待识别特征分别与涉密文字语句的多个涉密特征依次进行比对,计算相似程度值,挑选出最大相似程度值,实现全面的比对,提高语句屏蔽精度。
32、综上,本发明的有益效果为:本发明中先根据标点符号将待识别文字语句划分为多个短句,并将每个短句进行分词处理,得到短句词组,再将得到的短句词组进行向量化处理,得到词组矩阵,采用特征提取模型提取词组矩阵的特征,减少数据量,依次计算每个待识别特征和涉密文字语句中所有涉密特征的相似程度值,从而得到待识别文字语句和涉密文字语句的相似度,实现文字语句的全面对比,提高语句屏蔽精度。
- 还没有人留言评论。精彩留言会获得点赞!