一种基于训练数据重划分的鲁棒视频文本跨模态检索方法和装置与流程
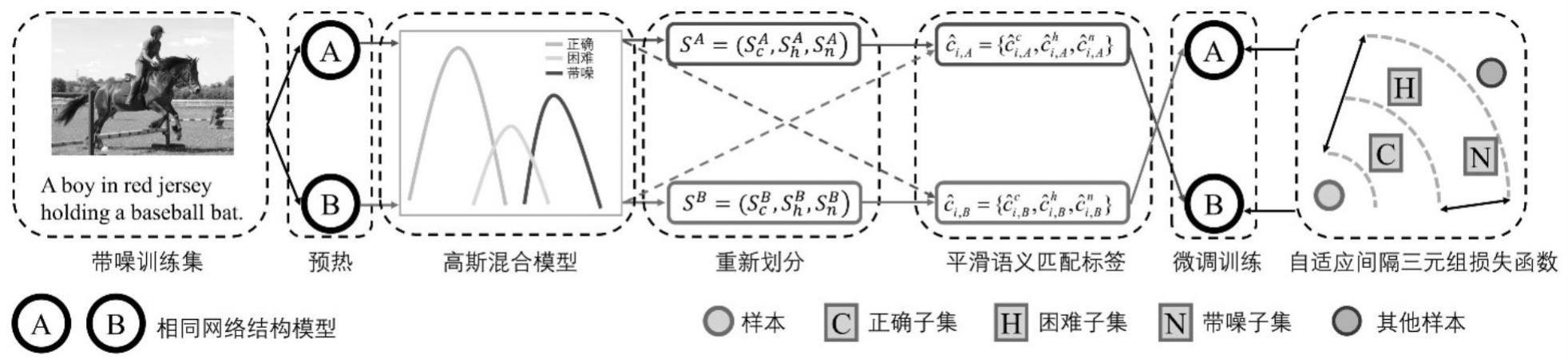
本技术涉及计算机视觉、自然语言处理和机器学习,具体涉及一种基于训练数据重划分的鲁棒视频文本跨模态检索方法和装置。
背景技术:
1、视频文本跨模态检索目的实现给定其中一种模态的查询输入,在多媒体数据集库中根据跨模态语义相似度得到另一种模态的检索返回。随着移动互联网的迅猛发展以及短视频平台的流量扩张,多媒体数据在短时间内快速激增,引发视频文本跨模态检索需求日益增加。然而,由于利用文本进行视频标注成本高昂,标注人员认知水平参差不齐,无法避免的将噪声数据引入模型训练集,导致视频文本跨模态检索模型性能大幅降低。
2、现有视频文本跨模态检索的训练方式核心思想可以总结为:最大化正样本对之间的相似度,同时最小化负样本对之间的相似度。然而,当训练数据存在噪声时,模型如果仍然按照错误的正负样本对标注信息进行训练,将会显著影响模型检索精度。
技术实现思路
1、针对现有视频文本跨模态检索方法无法在训练样本含有噪声的情况下保证检索性能稳定性的问题,本发明提出了一种基于训练数据重划分的鲁棒视频文本跨模态检索方法和装置,将训练数据按照是否含有噪声以及含有噪声类别进行重划分,然后分别设计鲁棒训练策略,保证模型性能稳定性。本技术所采用的技术方案如下:
2、一种基于训练数据重划分的鲁棒视频文本跨模态检索方法,该方法包括:
3、步骤s0,利用带噪数据集训练两个网络结构相同的模型a和模型b进行预热,得到两个预热后模型;
4、步骤s1,分别计算两个预热后模型中所有样本对的损失函数值;
5、步骤s2,根据所述损失函数值,分别拟合两个预热后模型的二元高斯混合模型;
6、步骤s3,利用拟合的所述二元高斯混合模型,根据对应均值较大高斯元的后验概率,重新划分训练集为三个子集;
7、步骤s4,利用重新划分得到的所述三个子集,分别平滑每个子集的语义匹配标签;
8、步骤s5,根据每个子集的所述语义匹配标签,构建三元组损失函数的自适应间隔值;
9、步骤s6,根据所述自适应间隔值,约束样本对之间的相似度关系,并对两个预热后模型分别进行微调训练;
10、步骤s7,利用微调后的模型实现视频文本跨模态检索。
11、进一步的,步骤s0具体包括:
12、步骤s000,选定带噪数据集,其中训练集d具体表示为:
13、
14、其中共有n个视频文本样本对(vi,ti),语义匹配标签ci∈{0,1}表示样本对是否被标注为具有相同的语义内容;
15、步骤s001,选取任意现有模型a将视频文本样本对(vi,ti)映射至d维公共空间中,根据原模型定义计算跨模态相似度sa(vi,ti);
16、步骤s002,构建与模型a具有相同网络结构但是初始化方式不同的模型b,将视频文本样本对(vi,ti)映射至d维公共空间中,根据原模型定义计算跨模态相似度sb(vi,ti);
17、步骤s003,选取三元组损失函数在数据集d上分别对a模型进行m个轮次的训练,得到模型a的预热模型:
18、
19、其中[x]+=max(x,0)表示函数计算结果仅取正值,其余情况函数值赋零,α表示固定间隔值;
20、步骤s004,选取三元组损失函数在数据集d上分别对b模型进行m个轮次的训练,得到模型b的预热模型:
21、
22、其中[x]+=max(x,0)表示函数计算结果仅取正值,其余情况函数值赋零,α表示固定间隔值。
23、进一步的,步骤s1具体包括:
24、步骤s100,关于训练集d中n个具有语义匹配标签ci=1的视频文本样本对利用模型a的预热模型计算所有样本对的损失函数值
25、
26、步骤s101,关于训练集d中n个具有语义匹配标签ci=1的视频文本样本对利用模型b的预热模型计算所有样本对的损失函数值
27、
28、进一步的,步骤s2具体包括:
29、步骤s200,将模型a的预热模型计算所得损失函数值拟合二元高斯混合模型,得到第i个视频文本样本对关于第k个高斯元的概率密度
30、
31、其中为关于模型a的预热模型的高斯混合系数;
32、步骤s201,将模型b的预热模型计算所得损失函数值拟合二元高斯混合模型,得到第i个视频文本样本对关于第k个高斯元的概率密度
33、
34、其中为关于模型b的预热模型的高斯混合系数。
35、进一步的,步骤s3具体包括:
36、步骤s300,计算模型a的预热模型输出的第i个视频文本样本对关于均值较小高斯元k′的后验概率
37、
38、步骤s301,计算模型b的预热模型输出的第i个视频文本样本对关于均值较小高斯元k′的后验概率
39、
40、步骤s302,联合后验概率和将训练集d重新划分为正确、困难和带噪三个子集用于模型a的预热模型后续微调训练:
41、
42、其中β表示后验概率门限值;
43、步骤s302,联合后验概率和将训练集d重新划分为正确、困难和带噪三个子集用于模型b的预热模型后续微调训练:
44、
45、其中β表示后验概率门限值。
46、进一步的,步骤s4具体包括:
47、步骤s400,针对视频文本样本对(vi,ti),在所属训练批次内利用模型a的预热模型计算预测得分pa(vi,ti):
48、
49、其中b表示每个训练批次中的样本对数量;
50、步骤s401,针对视频文本样本对(vi,ti),在所属训练批次内利用模型b的预热模型计算预测得分pb(vi,ti):
51、
52、其中b表示每个训练批次中的样本对数量;
53、步骤s402,针对模型a的预热模型所属三个训练子集,分别平滑语义匹配标签
54、
55、步骤s403,针对模型b的预热模型所属三个训练子集,分别平滑语义匹配标签
56、
57、进一步的,步骤s5具体包括:
58、步骤s500,针对视频文本样本对(vi,ti),在所属训练批次内定义关于模型a的预热模型视频困难样本vha:
59、
60、步骤s501,针对视频文本样本对(vi,ti),在所属训练批次内定义关于模型a的预热模型文本困难样本tha:
61、
62、步骤s502,针对视频文本样本对(vi,ti),在所属训练批次内定义关于模型b的预热模型视频困难样本vhb:
63、
64、步骤s503,针对视频文本样本对(vi,ti),在所属训练批次内定义关于模型b的预热模型文本困难样本thb:
65、
66、步骤s504,计算视频困难样本vha的语义匹配标签
67、
68、步骤s505,计算文本困难样本tha的语义匹配标签
69、
70、步骤s506,计算视频困难样本vhb的语义匹配标签
71、
72、步骤s507,计算文本困难样本thb的语义匹配标签
73、
74、步骤s508,构建关于模型a的预热模型视频部分三元组损失函数的自适应间隔值
75、
76、其中m为超参数;
77、步骤s509,构建关于模型a的预热模型文本部分三元组损失函数的自适应间隔值
78、
79、其中m为超参数;
80、步骤s510,构建关于模型b的预热模型视频部分三元组损失函数的自适应间隔值
81、
82、其中m为超参数;
83、步骤s511,构建关于模型b的预热模型文本部分三元组损失函数的自适应间隔值
84、
85、其中m为超参数。
86、进一步的,步骤s6具体包括:
87、步骤s600,将自适应间隔值和替换三元组损失函数中的间隔值α得到自适应间隔三元组损失函数用于模型a的预热模型后续微调训练m′个轮次,然后得到微调训练后的模型a,具体计算方式为:
88、
89、其中[x]+=max(x,0)表示函数计算结果仅取正值,其余情况函数值赋零;
90、步骤s601,将自适应间隔值和替换三元组损失函数中的间隔值α得到自适应间隔三元组损失函数用于模型b的预热模型后续微调训练m′个轮次,然后得到微调训练后的模型b,具体计算方式为:
91、
92、其中[x]+=max(x,0)表示函数计算结果仅取正值,其余情况函数值赋零。
93、进一步的,步骤s7具体包括:
94、步骤s700,利用微调训练后的模型a,对所有待检索的视频和文本进行特征提取;
95、步骤s701,利用微调训练后的模型b,对所有待检索的视频和文本进行特征提取;
96、步骤s702,选择一个文本作为查询输入,计算其关于微调训练后的模型a和模型b的特征与所有候选视频特征的相似度平均值,然后根据相似度平均值对所有候选视频进行降序排序,并将排序靠前的视频作为检索结果返回,以此实现文本到视频的跨模态检索。
97、步骤s703,选择一个视频作为查询输入,计算其关于微调训练后的模型a和模型b的特征与所有候选文本特征的相似度平均值,然后根据相似度平均值对所有候选文本进行降序排序,并将排序靠前的文本作为检索结果返回,以此实现视频到文本的跨模态检索。
98、一种基于训练数据重划分的鲁棒视频文本跨模态检索装置,包括处理器和存储有计算机程序的存储器,所述处理器执行所述计算机程序时实现上述方法。
99、通过本技术实施例,可以获得如下技术效果:本技术根据带噪数据的特性将其划分为正确、困难和带噪三个子集,并设计统一训练目标优化样本对之间在公共空间的距离关系,实现在任意带噪噪声比例条件下模型的鲁棒训练,保持视频文本跨模态检索的精度稳定性。
- 还没有人留言评论。精彩留言会获得点赞!