一种基于内存特征的恶意软件检测系统及方法与流程
本发明属于计算机主机安全,尤其涉及一种基于内存特征的恶意软件检测系统及方法。
背景技术:
1、随着计算机相关产业的快速发展,各种为了谋取非法利益的恶意软件也在不断迭代更新。虽然不同类型的防护措施包括防火墙、安全检测、杀毒软件等为网络主机的安全保驾护航,但仍有恶意软件通过不同的技术手段实现藏匿、绕过并最终发动对主机的攻击。
2、虽然恶意软件能够躲过其他检测软件的检测,但如果它要在主机上运行,那么必然会在主机的内存上留下运行的痕迹,因此对于内存特征的研究可以帮助发现、检测恶意软件的运行。
3、但恶意软件种类繁多,通过人工总结规则的方式工作量过大,而随着人工智能技术的发展,本发明将获取恶意软件运行时,在内存上留下的行为数据特征,通过使用机器学习模型进行有监督的机器学习,训练好模型后,对系统内存特征进行推理,从而检测主机系统中是否有恶意软件运行。本发明的系统可以从内存特征的角度去发现恶意软件的运行,进一步保障主机的安全。
4、中国专利cn101989322b公开了一种自动提取恶意代码的内存特征的方法和系统。包括:运行恶意代码对新产生的线程信息进行内存转储,生成转储文件;对转储文件进行关联分析并分组;对分组的转储文件提取特征并进行测试处理;系统包括:内存转储模块,用于运行恶意代码对新产生的线程信息进行内存转储,生成转储文件;关联分析模块,用于对转储文件进行关联分析并分组;特征提取与测试模块,用于对分组的转储文件提取特征并进行测试处理。本发明整个方案都是自动化的流程,无需人工参与,以线程为基本处理对象,实现了细粒度的更精确和全面的内存特征提取,不再依赖于分析人员的经验,最终获得的内存特征具有较低的误报率和极低的漏报率。
5、该发明通过运行恶意代码后,转存新产生的线程,对这些线程进行相似性的分析分组后,提取其内存特征。虽然该发明的过程是自动化的,但其提取具有超过一定相似性的内存特征时,相似性的程度判定会产生一定的误差,且以线程为内存提取单位粒度细,特征数量多,进而导致在进行特征的相似性判定时需要大量的人工规则介入,工作量较大且不易管理。
6、中国专利cn114692156b公开了一种对内存片段进行恶意代码检测的方法和系统。包括:获取待检测内存文件;对待检测内存文件依次进行二进制转化和分词预处理后,基于最优的片段位置和长度组合进行片段截取,得到预测片段;将预测片段输入最优的神经网络模型,对预测片段进行检测,得到待检测内存文件是否被植入恶意代码的结果;其中,神经网络模型采用嵌入层对输入预测片段进行升维后,通过卷积核大小不同的卷积层卷积后进行池化,最后通过展平层和全连接层转化后输入分类器。通过学习恶意代码的潜在的规则和特征,从而检测出尚未发现的病毒以及对现有的病毒进行检测。
7、该发明对获取的内存代码片段进行二进制转化和分词处理,将内存内容作为自然语言数据进行建模和预测。但其缺点是需要寻找最优的内存片段,转化为自然语言序列数据后的建模,数据量较大,使用深度学习模型建模,模型复杂且训练时间较长,并且模型也缺乏特征解释性。
技术实现思路
1、本发明的目的在于提供一种基于内存特征的恶意软件检测系统及方法,通过采集恶意软件运行时和正常运行时计算机主机的内存数据,分别提取内存特征后建立有监督的二层堆叠二分类机器学习模型,对日常监控中的内存数据片段进行是否存在恶意软件运行的二分类预测和风险告警,从而实现从内存特征的角度进行恶意软件运行的检测。
2、本发明的目的可以通过以下技术方案实现:
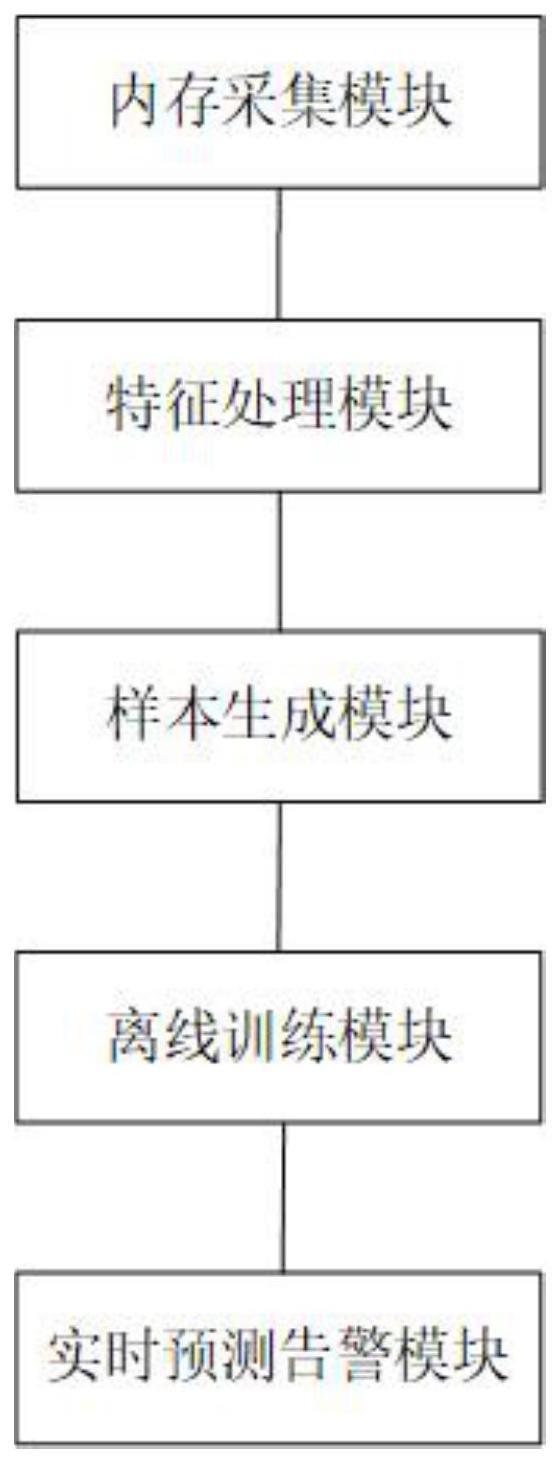
3、第一方面,本技术实施例提供了一种基于内存特征的恶意软件检测系统,包括依次通信连接的内存采集模块、特征处理模块、样本生成模块、离线训练模块和实时预测告警模块;
4、所述内存采集模块,用于采集主机运行时的内存数据;
5、所述特征处理模块,用于对采集到的所述内存数据进行特征工程处理,获得相应的内存特征;
6、所述样本生成模块,用于获取多种恶意软件,在所述主机中运行所述恶意软件和正常软件,通过所述内存采集模块采集第一内存数据并通过所述特征处理模块获取第一内存特征;在所述主机中运行所述正常软件,通过所述内存采集模块采集第二内存数据并通过所述特征处理模块获取第二内存特征;
7、所述离线训练模块,用于划分样本数据集,采用f1得分作为评估指标,训练并生成二分类机器学习模型;
8、所述实时预测告警模块,用于将训练好的所述二分类机器学习模型应用于判断监控中的所述主机是否有所述恶意软件正在运行,根据所述二分类机器学习模型判断的概率值,划分不同的告警等级;
9、其中,所述系统采用有监督机器学习算法进行二分类学习任务,将所述在所述主机中运行所述恶意软件和正常软件作为第一类标签,将所述在所述主机中运行所述正常软件作为第二类标签;
10、其中,所述特征工程处理包括:提取基础特征和对部分所述基础特征进行统计处理;
11、其中,将所述第一内存特征和所述第二内存特征作为所述离线训练模块的内存样本数据。
12、优选的,所述二分类机器学习模型采用模型堆叠技术,使用两层模型堆叠方案,生成二层堆叠二分类机器学习模型;其中,单个模型包括:逻辑回归、朴素贝叶斯、支持向量机、随机森林、gbdt、xgboost和lightbm。
13、优选的,在所述二层堆叠二分类机器学习模型中,第一层模型选择多个所述单个模型进行组合,第二层模型选择一个所述单个模型;其中,将所述第一层模型输出的预测概率值作为所述第二层模型的输入特征。
14、优选的,所述二层堆叠二分类机器学习模型的第一层单模型组合采用:xgboost、支持向量机、随机森林、lightgbm和朴素贝叶斯;所述二层堆叠二分类机器学习模型的第二层单模型采用逻辑回归。
15、优选的,所述内存采集模块采用lime软件对所述内存数据进行采集;所述特征处理模块对所述内存数据基于volatility软件进行所述特征工程处理;所述统计处理包括:统计求和、统计求商以及统计求平均。
16、优选的,所述内存特征包括:恶意软件发现类特征、模块注入类特征、句柄类特征、进程类特征和接口挂钩类特征;所述恶意软件包括:木马软件、病毒软件和勒索软件。
17、优选的,所述离线训练模块包括依次通信连接的数据集划分单元、模型评估单元、模型选择单元和模型保存单元;
18、所述数据集划分单元,用于将所述内存样本数据划分为训练数据集和测试数据集;其中,训练数据集:测试数据集=4:1;
19、所述模型评估单元,用于采用所述f1得分作为二分类任务的评估指标;
20、所述模型选择单元,用于采用多个不同模型进行所述二分类机器学习任务,观察所述不同模型之间所述f1得分的高低差异,并根据测试数据选择模型;
21、所述模型保存单元,用于将训练好的所述二分类机器学习模型保存为二进制文件;
22、其中,将所述恶意软件运行的所述内存样本数据作为正类,标注为0;将所述正常软件运行的所述内存样本数据作为负类,标注为1;
23、其中,所述f1得分用公式表示为:f1-score=2*精确率*召回率/(精确率+召回率);
24、其中,精确率=预测为正类且预测正确的样本数/所有预测为正类的样本数;召回率=预测为正类且预测正确的样本数/所有正类的样本数。
25、优选的,在所述f1得分的公式中加入调和系数b,调整召回率权重和精确率权重,将所述f1得分的公式调整为:f1-scoreb=(1+b*b)*精确率*召回率/(b*b*精确率+召回率)。
26、优选的,所述实时预测告警模块包括依次通信连接的实时内存采集单元、实时特征处理单元、模型实时分析单元和分级告警单元;
27、所述实时内存采集单元,用于通过所述内存采集模块实时采集并保存实时内存数据;其中,采集所述实时内存数据的采集间隔为一分钟;
28、所述实时特征处理单元,用于通过所述特征处理模块将采集的所述实时内存数据进行特征提取并进行统计处理,获取相应的实时内存特征;
29、所述模型实时分析单元,用于调用所述二层堆叠二分类机器学习模型,输入所述实时内存特征作为模型样本,输出概率值;其中,所述概率值位于0-1之间;
30、所述分级告警单元,用于根据所述概率值的大小区分不同的风险级别并进行告警;
31、其中,若所述概率值小于0.3,则为最高级风险;若所述概率值大于0.3且小于0.6,则为中级风险;若所述概率值大于0.6,则为低级/无风险。
32、第二方面,本技术实施例提供了一种基于内存特征的恶意软件检测方法,包括以下步骤:
33、s1,采集主机运行时的内存数据;
34、s2,对采集到的所述内存数据进行特征工程处理,获得相应的内存特征;
35、s3,获取多种恶意软件,在所述主机中运行所述恶意软件和正常软件,通过所述步骤s1采集第一内存数据并通过所述步骤s2提取第一内存特征;在所述主机中运行所述正常软件,通过所述步骤s1采集第二内存数据并通过所述步骤s2提取第二内存特征;
36、其中,将所述第一内存特征和所述第二内存特征作为模型的样本数据;
37、s4,将所述样本数据进行样本数据集划分,获取训练数据集和测试数据集;
38、其中,训练数据集:测试数据集=4:1;
39、s5,采用调和的f1得分作为评估指标,训练并测试生成二分类机器学习模型;
40、其中,所述调和的f1得分为:在f1得分中加入调和系数;
41、其中,所述二分类机器学习模型采用模型堆叠技术,生成二层堆叠二分类机器学习模型;
42、s6,通过所述步骤1采集实时内存数据并通过所述步骤s2获取实时内存特征;将所述实时内存特征作为实时样本数据输入所述二层堆叠二分类机器学习模型;
43、其中,所述二层堆叠二分类机器学习模型应用于判断所述主机是否正在运行所述恶意软件;
44、s7,根据所述二层堆叠二分类机器学习模型判断后输出的概率值,划分不同的风险等级并进行告警;
45、其中,若所述概率值小于0.3,则为最高级风险;若所述概率值大于0.3且小于0.6,则为中级风险;若所述概率值大于0.6,则为低级/无风险。
46、本发明的有益效果为:
47、(1)本发明主要使用linux系统中是否存在恶意软件运行时,不同的内存特征作为本发明模型的特征样本数据,由于软件在运行时必定会加载数据到系统内存上,因此从内存特征数据的角度,可以有效识别恶意软件的运行情况。
48、(2)本发明使用内存特征数据以及基于volatility软件生成的衍生的统计特征数据作为二分类机器学习模型的输入数据。这些特征数据使用lime内存采集软件进行采集,并通过统计处理的方式生成有区分度的内存特征,供后续的二分类机器学习模型使用,上述统计处理包括:统计求和、统计求商和统计求平均等。
49、(3)本发明通过收集多种恶意软件样本,并在实验系统上运行这些恶意软件样本后,采集相应的内存数据并提取对应的内存特征,将内存特征作为二分类机器学习模型的学习样本,进行离线训练和测试。在离线训练模块中会对这些学习样本进行标注(将恶意软件的内存样本作为正类,标注为0;将无恶意软件运行的内存样本作为负类,标注为1),这些有明确标注的样本可以大大提高分类模型的性能指标。
50、(4)本发明的二分类机器学习模型,使用两层模型堆叠的方案,从而形成了二层堆叠二分类机器学习模型。其第一层模型使用xgboost、支持向量机、随机森林、lightgbm和朴素贝叶斯,共五个单独的模型组合;第二层模型使用逻辑回归;第一层模型对每一条样本数据的输出结果用0到1之间的概率值来表示,然后将这些样本输出的概率值作为第二层模型的输入特征,最后再输出二分类的概率值大小作为模型的输出。本发明采用这样的模型结构可以大大提高模型的评估指标。
51、(5)由于恶意软件危害大,所以二分类机器学习模型应优先保障高召回率,尽量找到所有的恶意软件内存样本,因此考虑在f1得分的公式中加入调和系数b来调整召回率和精确率的权重,进而增加召回率的权重,获得更好的召回效果。本发明使用参数调和的f1得分对模型进行评估,使得恶意软件的召回效果更好,并且能够尽可能多地找出所有恶意软件的内存样本。
52、(6)本发明的实时预测告警模块,使用离线训练好的二层堆叠二分类机器学习模型,对实时采集的内存数据进行特征处理,并将获得的实时内存特征作为该模型的样本数据进行后续的样本预测;根据预测结果的概率值划分范围,设定不同的告警风险等级,方便技术人员进行监控和问题排查。
- 还没有人留言评论。精彩留言会获得点赞!