基于图像识别的施工安全检测方法及系统与流程
本发明涉及施工安全,具体而言,涉及一种基于图像识别的施工安全检测方法及系统。
背景技术:
1、在光伏电站施工现场,由于山地陡峭、设备重大,经常采用挖机等设备进行搬运,容易导致视野盲区引起的人身伤亡事故;再由于施工人员不注意自身安全,例如在施工区域内不戴安全帽、吸烟均容易导致安全事故发生;因此,通过终端采集设备,实时采集施工现场的图像,并基于图像识别算法,能够提前分析施工现场隐患,提前预警,避免造成损失;
2、现有技术大多数采用人工现场监督或利用人工值守视频监控系统来检测施工现场,由于施工现场山地陡峭,人工监督的方式无法做到时刻针对施工区域内的全局掌控;人工值守的视频监控系统同样需要时刻注意监控图像,导致消耗大量的人力、财力;为此,我们提出一种基于图像识别的施工安全检测方法及系统。
技术实现思路
1、本发明的目的在于提供一种基于图像识别的施工安全检测方法及系统,用以解决现有通过人工监督施工区域,存在成本高、检测不全面的问题,实现适用于施工现场人机碰撞预测、安全帽检测以及抽烟检测的方法。
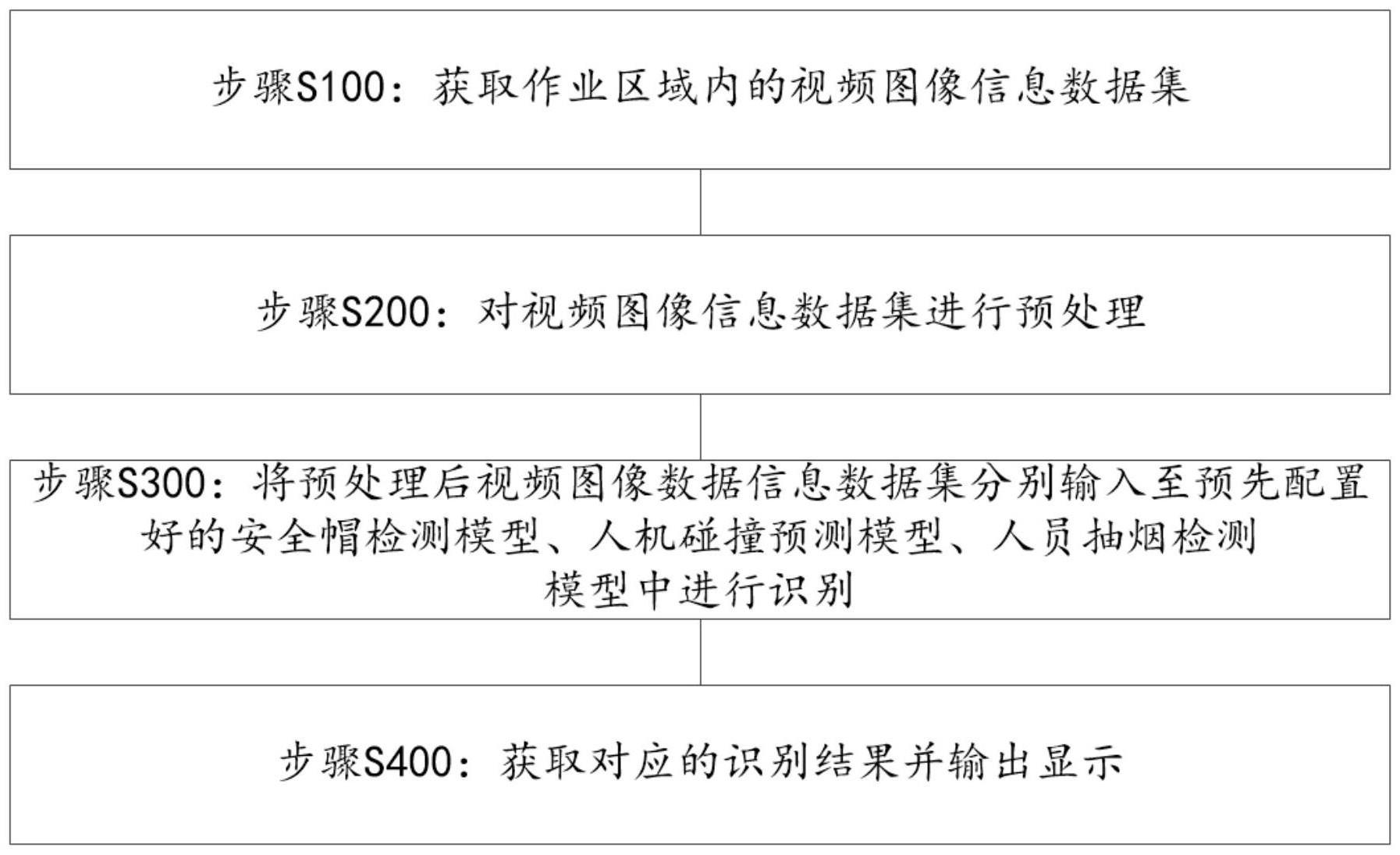
2、本发明第一方面的技术方案提供了一种基于图像识别的施工安全检测方法,包括:
3、获取作业区域内的视频图像信息数据集;
4、对视频图像信息数据集进行预处理;
5、经预处理后的视频图像数据信息数据集分别输入至预先配置的安全帽检测模型、人机碰撞预测模型、人员抽烟检测模型中进行识别;
6、获取对应的识别结果并输出显示。
7、进一步地,经预处理后的视频图像数据信息输入安全帽检测模型中的识别方法具体包括:
8、将视频图像信息数据集输入改进后的yolov5网络模型中进行特征提取,获取采样特征图;
9、基于yolov5网络模型中的neck模块对采样特征图进行特征融合;
10、将融合后的采样特征图输入卷积注意力机制cbam模块中的通道注意力模块中计算通道注意力特征,其计算公式为:
11、mc(f1)=σ(mlp(avgpool(f1))+mlp(maxpool(f1)));
12、其中,mc为通道注意力特征,f1为输入的采样特征图,σ为sigmoid激活函数,mlp为神经网络,avgpool为全局平均池化,maxpool为全局最大池化。
13、上述进一步地方案的有益效果至少包括:通过neck模块对采样特征图进行特征融合,可使所有特征采样图的尺寸保持一致,将来自不同层次的特征信息有效融合,以此提高安全帽检测模型的性能;
14、进一步地,计算通道注意力特征后还包括:
15、将通道注意力特征输入卷积注意力机制cbam模块中的空间注意力模块中计算空间注意力特征,其计算公式为:
16、ms(f)=σ(f7×7([avgpool(f);maxpool(f)]));
17、其中,ms为空间注意力特征,f为通道注意力模块输出的通道特征图,f7×7为7×7的卷积函数。
18、上述进一步地方案的有益效果至少包括:通过引入卷积注意力机制,使得安全帽检测模型在识别过程中更加关注小目标特征信息,改善了现有安全帽检测模型易丢失小目标特征信息的问题,进而有效从图像信息中识别出是否佩戴安全帽;
19、进一步地,经预处理后的视频图像信息输入人机碰撞预测模型中的预测方法具体包括:
20、获取作业区域内双视角下的视频图像信息,将双视角下的视频图像信息分别输入预先配置的人机碰撞预测模型中;
21、其中,人机碰撞预测模型的预测方法包括:
22、基于混合高斯背景模型对视频图像信息进行前景区域检测,获取去除阴影特征后的前景目标;
23、基于卡尔曼滤波器对前景目标进行抗遮挡预测跟踪,获取碰撞预测结果;
24、基于双视角视频图像信息的碰撞预测结果,判断前景区域内是否存在碰撞事故。
25、上述进一步地方案的有益效果至少包括:通过获取双视角的视频图像信息,基于卡尔曼滤波器对前景目标进行抗遮挡预测跟踪,进而实现人机碰撞预测模型判断作业区域内是否发生碰撞;
26、进一步地,获取去除阴影特征后的前景目标具体包括:
27、预设一个代表背景的样本区域;
28、基于前景目标阴影特征在his色彩空间中的特征属性,将前景目标中像素点的h、s、i三个分量分别与样本区域中对应像素点的h、s、i分量进行比较,检测出前景目标的第一阴影区域;
29、对前景目标进行纹理检测和边缘提取,提取出前景目标的内部区域和边缘信息;
30、将内部区域和边缘信息结合后获取真实前景目标;
31、将真实前景目标与第一阴影区域结合,剔除非阴影的真实前景目标。
32、上述进一步地方案的有益效果至少包括:由于前景目标的阴影特征可能导致人机碰撞预测模型在预测过程中产生误判和漏判的问题,上述方案通过去除前景目标的阴影特征,获取真实的前景目标,使得人机碰撞预测模型在目标检测过程中减少误判和漏判,在图像信息中保留利于更准确检测和识别的目标。
33、进一步地,基于卡尔曼滤波器对前景目标进行抗遮挡预测跟踪,获取碰撞预测结果具体包括:
34、获取真实前景目标的运动信息以及位置,并实时标记真实前景目标;
35、利用卡尔曼滤波算法和粒子滤波器对真实前景目标进行预测跟踪,具体包括:
36、基于卡尔曼滤波算法,根据真实前景目标的当前位置,预测出真实前景目标的期望位置;
37、将期望位置输入粒子滤波器中,在期望位置处进行搜索迭代后得到真实前景目标的真实位置;
38、根据真实前景目标的真实位置,利用卡尔曼滤波算法对真实位置进行修正,实时更新真实前景目标的位置信息。
39、上述进一步地方案的有益效果至少包括:通过采用卡尔曼滤波器与粒子滤波器结合的算法识别,当图形信息中的目标之间相互遮挡时,能够更好地跟踪目标,实现目标的抗遮挡跟踪。
40、进一步地,基于卡尔曼滤波器对前景目标进行抗遮挡预测跟踪,获取碰撞预测结果还包括:
41、基于真实前景目标建立有向包围盒,对前景运动目标进行有向包围框标记;
42、基于有向包围框碰撞检测算法判断单个视角视频中预测跟踪的前景运动目标的有向包围框是否发生碰撞。
43、上述进一步地方案的有益效果至少包括:利用有向包围盒和对真实前景目标进行有向包围框标记,使得人机碰撞预测模型在识别过程中更够更准确地获取目标的形态,从而提升碰撞检测的性能;
44、进一步地,所述人员抽烟检测模型的识别方法包括:
45、对视频图像信息数据集进行预处理,获取视频图像信息中的人脸区域坐标值;
46、利用现有数据集中预训练的vgg16模型;通过迁移学习,保留vgg16模型的特征提取层,删除vgg16的前两个全连接层,并加载现有数据集预训练vgg16模型的权重;
47、采用全局均池化层替换vgg16模型的前两个全连接层;
48、基于改进后的vgg16模型部署到视频图像信息中进行实时检测,获取吸烟目标区域,对目标区域的图像进行人脸识别并输出显示识别结果。
49、上述进一步地方案的有益效果至少包括:通过在预训练的vgg16模型进行改进的迁移学习模型,采用全局均池化层替换vgg16模型的前两个全连接层,相较于原有vgg16模型,改进后的vgg16模型在训练过程中能够获取更快的收敛速度读,在训练后期的损失值和准确率更加平稳,且训练时间缩短。
50、进一步地,改进后vgg16模型包括由13个卷积层和3个全连接层组成的参数训练层,其识别过程包括:
51、输入图像,利用连续2个3×3卷积核以及3个3×3卷积核实现图像卷积,每次图像卷积后执行1个修正线性单元;
52、连续卷积层后接1个不添加填充的最大池化层;
53、图像经最大池化层处理后由展平层转化为一维数据,输入全连接层进行分类处理。
54、上述进一步地方案的有益效果至少包括:,利用最大池化层使得连续卷积后的激活映射空间维度减半,优化了改进的迁移模型;
55、本发明第二方面的技术方案提供了一种基于图像识别的施工安全检测系统,该检测系统根据本发明第一方面的技术方案中任一项所述的基于图像识别的施工安全检测方法构建得到,该安全检测系统包括:
56、采集处理模块,配置为获取作业区域内的视频图像数据流并上传至服务器;
57、安全帽检测模块,配置为基于改进后添加了卷积注意力机制模块的yolov5网络模型进行模型训练,对作业区域内工作人员是否佩戴安全帽进行检测;
58、抽烟检测模块,配置为基于迁移学习改进后采用全局均池化层替换前两个全连接层的vgg16模型进行模型训练,对作业区域内工作人员是否抽烟进行检测;
59、人机碰撞预测模块,配置为基于前景区域检测和卡尔曼滤波器目标检测算法对作业区域内是否发生人机碰撞进行检测。
60、本发明的有益效果包括:
61、1.本发明通过采集作业区域内的视频图像信息数据集,将视频图像信息输入预先配置好的安全帽检测模型、人机碰撞预测模型、人员抽烟检测模型中进行识别,实现了作业区域内自动识别人机碰撞、安全帽佩戴以及抽烟的不安全行为,无需人工辅助检测,适用于施工现场,缩小检测成本且对施工现场的检测全面。
- 还没有人留言评论。精彩留言会获得点赞!