动作数据生成方法、装置、电子设备及存储介质与流程
本技术涉及视觉动作捕捉,特别是涉及一种动作数据生成方法、装置、电子设备及存储介质。
背景技术:
1、动作捕捉是指对人的身体动作、手势以及表情进行捕捉采集,完整呈现出演员的表演。动作捕捉可以采用光学动作捕捉、惯性动作捕捉和无标记视觉动作捕捉几种方式实现。单摄像头视觉动作捕捉技术是指基于计算机视觉原理,分析由一个摄像机捕捉到的二维视频画面中人物的肢体动作和手势,生成具有三维空间信息的动作数据,并且此数据可以传递给制作好的三维模型,从而让三维模型做出与二维视频中的真人相似的动作。
2、目前,单摄像头视觉动作捕捉技术与基于marker(标记)点的光学动作捕捉系统和惯性传感器的动作捕捉技术相比,优势在于成本更低,且被算法分析其动作的真人无需穿戴任何设备,约束性较小,且动作捕捉精度较高。根据使用的摄像头类型不同,可以分为单个光学摄像头视觉动作捕捉技术和弱透视rgb摄像头视觉动作捕捉技术,后者的硬件成本会更低。其中,弱透视rgb摄像头视觉动作捕捉技术比较有代表性的分别为google(谷歌)开发的mediapipe(一种基于图形的跨平台框架)和facebook(脸书)研发的frankmocap(3d人体姿态和形状估计算法)。mediapipe的处理流程与frankmocap的处理流程相似,区别在于二者使用了不同的算法进行位置点的标记,以及最后绘制得到的视频算法不同。
3、mediapipe的单个rgb摄像头动捕技术所识别出来的肢体位置数据点和unityhumanoid(人形动画数字人模型)制作的骨骼需要的数据点的主要差别在于上半身数据点的位置,即mediapipe标记的是两侧的肩膀和两侧的大腿根部,而unity humanoid需要的是两侧肩膀的数据点、腰部中心的数据点、胯部中心的数据点和两侧大腿根部的数据点。对于按照unity humanoid标准制作出的3d模型,mediapipe生成的动作数据不能正确驱动模型,无法直接使用mediapipe技术实现单个rgb摄像头肢体动作捕捉,仍需要进行大量的位置点识别和换算,在一定程度上增加了cpu(服务器)的计算负担。
4、frankmocap的计算点位与unity humanoid要求的点位相似,但是frankmocap经过显示输出后会生成一个通用的3d人物模型覆盖在视频画面上,使得视频帧率只有11左右,不到30,因此frankmocap较难做到流畅地将动作捕捉数据结果传送至unity humanoid。
5、综上所述,传统的单个rgb摄像头视觉动作捕捉技术由于需要大量的位置点识别和换算以及数字人物模型的限制,导致传统的单个rgb摄像头视觉动作捕捉技术不仅增加了cpu的计算负担且实用性较差。
技术实现思路
1、基于此,有必要针对上述技术问题,提供一种实用性较好且降低cpu计算负担的动作数据生成方法、装置、电子设备及存储介质。
2、第一方面,本技术提供一种动作数据生成方法,所述方法包括:
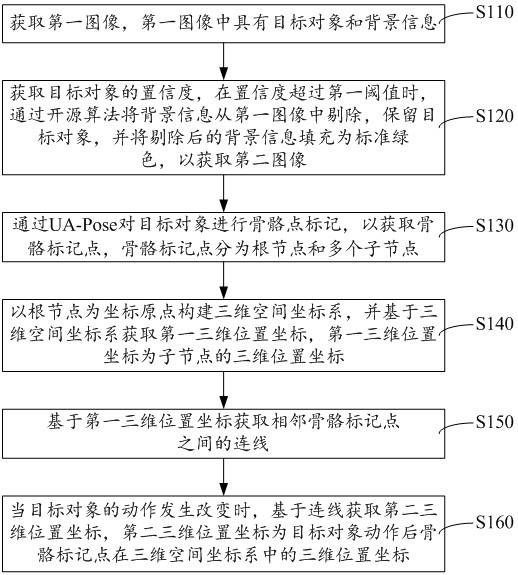
3、获取第一图像,所述第一图像中具有目标对象和背景信息;
4、获取所述目标对象的置信度,在所述置信度超过第一阈值时,通过开源算法将所述背景信息从所述第一图像中剔除,保留所述目标对象,并将剔除后的背景信息填充为标准绿色,以获取第二图像;
5、通过ua-pose对所述目标对象进行骨骼点标记,以获取骨骼标记点,所述骨骼标记点分为根节点和多个子节点;
6、以所述根节点为坐标原点构建三维空间坐标系,并基于所述三维空间坐标系获取第一三维位置坐标,所述第一三维位置坐标为所述子节点的三维位置坐标;
7、基于所述第一三维位置坐标获取相邻骨骼标记点之间的连线;
8、当所述目标对象的动作发生改变时,基于所述连线获取第二三维位置坐标,所述第二三维位置坐标为目标对象动作后骨骼标记点在所述三维空间坐标系中的三维位置坐标。
9、在其中一个实施例中,所述以所述根节点为坐标原点构建三维空间坐标系,并基于所述三维空间坐标系获取第一三维位置坐标,包括:
10、在所述第二图像中对所述目标对象进行骨骼点标记,以获取所述目标对象的二维骨骼标记点;
11、将所述二维骨骼标记点与人形动画数字人模型进行匹配,以生成所述二维骨骼标记点在三维空间中的空间信息;
12、基于所述空间信息,以所述根节点为原点构建三维空间坐标系。
13、在其中一个实施例中,所述以所述根节点为坐标原点构建三维空间坐标系,并基于所述三维空间坐标系获取第一三维位置坐标,之后包括:
14、将所述第二图像转化为特征矩阵,以获取与所述特征矩阵相对应的特征向量;
15、通过卷积神经网络对所述特征向量进行中心化处理,以获取与所述特征向量相对应的协方差矩阵。
16、在其中一个实施例中,所述通过卷积神经网络对所述特征向量进行中心化处理,以获取与所述特征向量相对应的协方差矩阵,之后包括:
17、对所述协方差矩阵进行特征分解,以获取多个对应的特征根;
18、通过对抗神经网络对所述多个特征根进行区分,以获取与待识别特征相对应的特征根以及所述待识别特征与所述特征根之间的映射矩阵。
19、在其中一个实施例中,所述基于所述第一三维位置坐标获取相邻骨骼标记点之间的连线,之前还包括:
20、获取图像采集设备参数,所述图像采集设备参数为rgb摄像头的内外参数;
21、根据所述图像采集设备参数以及所述根节点获取所述骨骼标记点的欧拉坐标。
22、在其中一个实施例中,所述方法还包括:
23、将所述骨骼标记点发送至数字人物模型进行匹配,使得所述数字人物模型具有与所述目标对象相对应的骨骼标记点;
24、基于所述第一三维位置坐标和第二三维位置坐标,获取所述目标对象的动作数据。
25、在其中一个实施例中,所述基于所述第一三维位置坐标和第二三维位置坐标,获取所述目标对象的动作数据,之后包括:
26、发送所述动作数据至所述数字人物模型,以控制所述数字人物模型执行与所述目标对象相同的动作。
27、第二方面,本技术提供一种动作数据生成装置,所述装置包括:
28、图像获取模块,用于获取第一图像,所述第一图像中具有目标对象和背景信息;
29、图像处理模块,用于获取所述目标对象的置信度,在所述置信度超过第一阈值时,通过开源算法将所述背景信息从所述第一图像中剔除,保留所述目标对象,并将剔除后的背景信息填充为标准绿色,以获取第二图像;
30、骨骼点标记模块,用于通过ua-pose对所述目标对象进行骨骼点标记,以获取骨骼标记点,所述骨骼标记点分为根节点和多个子节点;
31、坐标系模块,用于以所述根节点为坐标原点构建三维空间坐标系,并基于所述三维空间坐标系获取第一三维位置坐标,所述第一三维位置坐标为所述子节点的三维位置坐标;
32、连线获取模块,用于基于所述第一三维位置坐标获取相邻骨骼标记点之间的连线;
33、位置分析模块,用于当所述目标对象的动作发生改变时,基于所述连线获取第二三维位置坐标,所述第二三维位置坐标为目标对象动作后骨骼标记点在所述三维空间坐标系中的三维位置坐标。
34、第三方面,本技术提供一种电子设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现以下步骤:
35、获取第一图像,所述第一图像中具有目标对象和背景信息;
36、获取所述目标对象的置信度,在所述置信度超过第一阈值时,通过开源算法将所述背景信息从所述第一图像中剔除,保留所述目标对象,并将剔除后的背景信息填充为标准绿色,以获取第二图像;
37、通过ua-pose对所述目标对象进行骨骼点标记,以获取骨骼标记点,所述骨骼标记点分为根节点和多个子节点;
38、以所述根节点为坐标原点构建三维空间坐标系,并基于所述三维空间坐标系获取第一三维位置坐标,所述第一三维位置坐标为所述子节点的三维位置坐标;
39、基于所述第一三维位置坐标获取相邻骨骼标记点之间的连线;
40、当所述目标对象的动作发生改变时,基于所述连线获取第二三维位置坐标,所述第二三维位置坐标为目标对象动作后骨骼标记点在所述三维空间坐标系中的三维位置坐标。
41、第四方面,本技术提供一种计算机存储介质,存储有计算机程序,所述计算机程序被处理器执行时实现以下步骤:
42、获取第一图像,所述第一图像中具有目标对象和背景信息;
43、获取所述目标对象的置信度,在所述置信度超过第一阈值时,通过开源算法将所述背景信息从所述第一图像中剔除,保留所述目标对象,并将剔除后的背景信息填充为标准绿色,以获取第二图像;
44、通过ua-pose对所述目标对象进行骨骼点标记,以获取骨骼标记点,所述骨骼标记点分为根节点和多个子节点;
45、以所述根节点为坐标原点构建三维空间坐标系,并基于所述三维空间坐标系获取第一三维位置坐标,所述第一三维位置坐标为所述子节点的三维位置坐标;
46、基于所述第一三维位置坐标获取相邻骨骼标记点之间的连线;
47、当所述目标对象的动作发生改变时,基于所述连线获取第二三维位置坐标,所述第二三维位置坐标为目标对象动作后骨骼标记点在所述三维空间坐标系中的三维位置坐标。
48、上述动作数据生成方法、装置、电子设备及存储介质,通过获取具有目标对象及其背景信息的图像数据,并基于目标对象的置信度,在置信度超过设定值时通过开源算法将图像中的背景信息剔除,保留目标对象并将所保留的目标对象的背景填充为标准绿色,防止图像中其他对象的干扰,进而防止出现目标对象转移的情况,保证动作捕捉的数据源能够较稳定的传输,避免掉帧抖动。随后通过ua-pose对目标对象进行骨骼点标记来获取目标对象的根节点和多个子节点,并以根节点为原点构建三维空间坐标系。最后,根据该三维空间坐标系获取骨骼标记点的三维位置坐标,并根据骨骼标记点的三维位置坐标获取相邻骨骼标记点之间的连线,当目标对象的动作发生改变时,基于相邻骨骼标记点之间的连线即可在上述构建的三维空间坐标系中获取目标对象动作后对应骨骼标记点的三维位置坐标,即动作后对应骨骼标记点与坐标原点之间的相对位置。该方法根据目标对象的骨骼标记点之间的连线识别目标对象动作前后骨骼标记点的三维位置坐标,通过较简单的方式实现对目标对象的动作捕捉,减少了位置点的识别和换算,进而降低了cpu的计算负担,具有较好的实用性。
- 还没有人留言评论。精彩留言会获得点赞!