一种基于深度强化学习的智能兵棋推演决策方法
本发明属于深度强化学习领域,特别是涉及一种基于深度强化学习的智能兵棋推演决策方法。
背景技术:
1、随着高新技术在军事领域的不断发展运用,武器装备的性能参数越来越多、造价越来越高,现代作战体系越来越复杂,作战训练成本也同步激增。为控制训练成本,节约人力物力资源,各国使用仿真技术模拟作战训练。近年来,以深度强化学习为代表的人工智能技术快速发展,使得直接从模拟战场原始数据中快速提取特征,从而对战场态势进行描述、感知并进一步自主决策成为可能。兵棋推演可以模拟对抗的流程和结果,其结果对实际对抗具有借鉴意义。将人工智能技术应用于兵棋推演,形成战术兵棋智能体,对培养智能化作战指挥员打赢未来战争具有深远意义。
2、兵棋推演中最常见的形式是双方博弈,在该形式下,通常推演双方分别控制甲方和乙方,在指定的任务想定下,对己方资源进行规划和调度,从而完成既定对抗意图。目前,深度强化学习的研究主要应用于博弈方向以及人机对抗上,其中深度q学习网络(deep q-learning network,dqn)能很好的完成对环境状态的态势理解与决策构建的准确性;同时记忆函数的引入将在可自我博弈的基础上完成对模型的快速训练和较好的准确性。但是在兵棋推演系统中智能体设计上,面对瞬息万变的战场环境与错综复杂的作战场景,智能体在数据学习上周期漫长,策略产出与模型训练收敛时都需要较长时间,尤其是基于深度强化学习的思想和方式实现智能算法,虽然提高了ai在兵棋系统的对抗推演水准,但是较长周期的策略产出是其最大的弊端。
3、现有技术1cn114722998a中,公开了一种基于cnn-ppo的兵棋推演智能体构建方法。该现有技术采集兵棋推演平台的初始态势数据,并对初始态势数据进行预处理,获得目标态势数据;构建影响力地图模块,将目标态势数据输入影响力地图模块,输出获得影响力特征;基于卷积神经网络和近端策略优化构建混合神经网络模型,将目标态势数据和影响力特征拼接后,输入混合神经网络模型进行模型迭代训练,直到目标函数最小、网络收敛,实现cnn-ppo智能体的构建。该现有技术用于改进在兵棋推演这一复杂场景中智能体计算决策的效率,加快智能体训练过程的收敛速度,但是缺乏有效方法对实际作战场景下智能体策略进行评估,导致其策略的准确性可能不高。
4、现有技术2cn113723013a中,公开了一种用于连续空间兵棋推演的多智能体决策方法。该方法构建连续空间兵棋推演场景,得到用于兵棋推演的战场环境数据,多智能体进行初始化;构建经验重访数据集;多个智能体进行本地观测;基于cnn提取推演多智能体的多实体特征;多实体特征与多智能体的本地观测数据共同作为多智能体学习的输入,利用基于课程学习奖赏的q学习训练多智能体;利用训练完成的多智能体进行对战决策。但是,该方法适配于兵棋推演中离散空间性能较差,这种离散空间是指智能体是在有限动作下,战场状态是随每一回合的推演而有限变化的;同时,缺乏有效评估方法对智能体策略进行合理评估。
技术实现思路
1、本发明主要解决的技术问题是提供一种基于深度强化学习的智能兵棋推演决策方法,旨在帮助战术兵棋智能体加快产出作战决策。
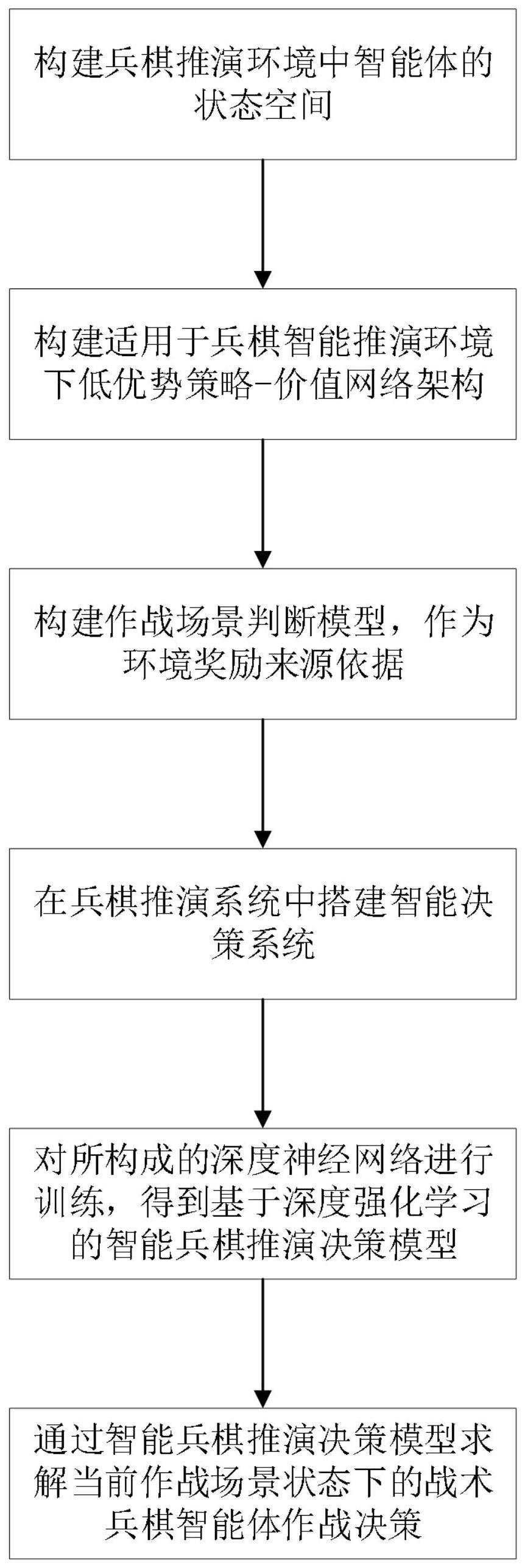
2、为解决上述技术问题,本发明提供一种基于深度强化学习的智能兵棋推演决策方法,所述方法包括:
3、步骤1:构建兵棋推演环境中智能体的状态空间;
4、步骤2:构建适用于兵棋智能推演环境下低优势策略-价值网络架构;
5、步骤3:构建作战场景判断模型,作为环境奖励来源依据;
6、步骤4:在兵棋推演系统中搭建智能决策系统;
7、步骤5:对所述步骤1至4得到的智能体状态空间、低优势策略-价值网络架构、作战场景判断模型和智能决策系统所构成的深度神经网络进行训练,得到基于深度强化学习的智能兵棋推演决策模型;
8、步骤6:在所述智能兵棋推演决策模型中,对当前作战场景状态下的战术兵棋智能体作战决策进行求解。
9、进一步地,所述步骤1的具体实现步骤为:
10、步骤1.1:构建适用于兵棋推演环境中的战场态势实体分类模型;
11、所述实体分类模型基于卷积神经网络,结合战场态势图信息,将仿真数据划分为敌情,我情,战场环境三类;
12、步骤1.2:接收兵棋推演系统中仿真数据,输入至战场态势实体分类模型,得到模型分类结果;
13、步骤1.3:根据分类结果,构建包含地形矩阵,兵棋位置矩阵,上一步矩阵和是否为先手矩阵的n维战场态势信息矩阵。
14、进一步地,所述步骤2的具体实施步骤为:
15、步骤2.1:构建初步的传统策略网络架构,策略网络π(a|s;θ)用于近似策略函数π,给出当前状态s下的动作a,通过策略梯度算法中梯度上升方式更新网络参数θ;
16、步骤2.2:对传统策略网络架构的策略梯度引入基准线(baseline)进行改进,构建基准线为状态-价值函数vπ(st)的低优势策略网络;
17、步骤2.3:构建价值网络v(s;w)架构,其中w为价值网络的神经网络参数;s表示战场状态;v为状态-价值函数,输入为战场状态s,输出为数值。价值网络v(s;w)用于近似状态-价值函数,其输出数值用于评判当前状态对于智能体的好坏程度,以改进策略网络,梯度下降方式更新网络参数w;
18、由于动作-价值函数qπ是对回报ut的期望,因此可用强化(reinforce)方法中观测到的折扣回报ut拟合qπ,则可得到预测误差为:
19、δt=v(st;ω)-ut,
20、得到梯度:
21、
22、梯度下降更新状态-价值网络中参数ω,其中γ为学习率:
23、
24、步骤2.4:构建经验回放池。
25、步骤2.2具体按以下步骤实施:
26、步骤2.2.1:在策略梯度中引入基准线进行改进,所述基准线定义为一个不依赖于动作a的函数b,此时策略梯度为:
27、
28、由于策略函数π为概率密度函数,因此关于a求和后结果为1,因此结果为0,故引入基准线的策略梯度能保证期望不变,即:
29、
30、由于直接求策略梯度中的期望代价较高,使用蒙特卡洛对期望求近似,在t时刻战术兵棋智能体通过随机抽样采取的动作为at~π(·|st;θ),令:
31、
32、g(at)是策略梯度的无偏估计,由于at是随机抽样得到的,因此可得随机梯度:
33、
34、若b的选择越接近于qπ,则随机策略梯度g(at)的方差会越小,策略网络在训练时收敛速度会加快;
35、步骤2.2.2:选择状态-价值函数vπ(st)作为策略梯度中基准线;
36、其中,状态-价值函数vπ(st)定义为:
37、
38、基准线的引入加快策略网络的收敛速度,则此时的随机梯度为:
39、
40、其中,动作-价值函数qπ由强化方法近似,再通过经验回放池中数据可计算得到qπ的近似值ut,状态-价值函数vπ(s)使用卷积神经网络v(s;w)近似,即随机梯度可近似为:
41、
42、步骤2.2.3:构建低优势策略网络;
43、对初步构建的策略网络引入状态-价值网络v(s;w)作为基准线,采用梯度上升更新策略网络π(a|s;θ)中网络参数:
44、
45、低优势策略网络中低优势来源于优势函数,优势函数定义为:
46、a(s,a)=q(s,a)-v(s),
47、a(s,a)表示在状态s下,某动作a相对于平均而言的优势性,在其恰好存在于步骤2.2.2随机梯度g(at;θ)展开式中;若a(s,a)的值越小,说明该动作具有平均性,在策略网络中表现为的随机梯度的方差越小,这种低优势性将加快模型训练速度。
48、进一步的,步骤2.4具体按以下步骤实施:
49、步骤2.4.1:将兵器推演过程中,在t+1回合推演前t回合的战场状态st,战术兵棋智能体采取的指挥决策at,战术兵棋智能体评估值qt,获得的作战成果效益值rt以及t+1回合新的战场状态st+1作为一个张量[st,at,qt,rt,st+1]存入经验池中;
50、步骤2.4.2:每次训练将从经验回放池中随机抽去最小-批个张量,进行低优势策略-价值网络的训练。
51、进一步的,所述步骤3中的具体按以下步骤实施:
52、步骤3.1:通过军事规则先验知识得到作战效能数值库;
53、其中,作战效能数值库中某一数值来源于某军事规则中规则描述和数值指标,包含毁伤能力值,补给能力值等;
54、步骤3.2:构建评价网络,输入为当前战场态势,具体为步骤1.3中n维战场态势矩阵,输出为作战效益组合的内部权重,{α,β,ε,...,μ};
55、步骤3.3:评价网络输出权重集结合作战效能数值库中指标组合,用于计算在当前状态下,战术兵棋智能体的指挥决策产生的作战成果效益。
56、进一步的,所述步骤4中的具体按以下步骤实施:
57、步骤4.1:接收兵棋推演系统每回合战场信息,通过步骤1将战场信息构建为战术兵棋智能体状态空间;
58、步骤4.2:适配兵棋推演系统决策指令接口,将可行动作概率集中动作映射为战术兵棋智能体决策指令;
59、步骤4.3:接收兵棋推演系统推演结果,更新决策执行结果。决策执行结果主要包括决策是否执行与决策实际执行效果,其中决策实际执行效果是预设决策值与实际执行值的差异。
60、进一步的,所述步骤5中的具体按以下步骤实施:
61、步骤5.1:初始化当前经验回放池;
62、步骤5.2:初始设置步骤2中两个结构相同的低优势策略-价值网络,且支持自博弈的战术兵棋智能体,其中训练方将一直采用训练过程中最新的神经网络参数,陪训方从过去所保存的神经网络参数集中随机抽样作为自身参数;
63、步骤5.3:通过步骤1,获取当前战场态势信息,输入至步骤2中低优势策略-价值网络,得到战术兵棋智能体指挥决策与作战评估值,并将战术兵棋智能体指挥决策下达至兵棋推演系统中,结束当前回合,等待对方决策下达;
64、步骤5.4:兵棋推演系统接收训练方与陪训方的指挥决策进行推演,返回新的战场状态信息,进入下一回合;
65、步骤5.5:作战场景判断模型分析战场态势信息,计算训练方的作战成功效益值;
66、步骤5.6:经验回放池收集训练数据并存储;
67、步骤5.7:当一场兵棋推演结束后,根据经验回放池数据进行网络训练;
68、步骤5.8:每经过15epoch后,计算策略损失,价值损失,平均奖励;
69、步骤5.9:训练完成,保存智能兵棋推演决策模型。
70、进一步的,所述步骤6中的具体按以下步骤实施:
71、步骤6.1:根据步骤1所构建的智能体状态空间,结合当前作战场景的态势信息,构造智能兵棋推演决策模型的输入矩阵,包括我方兵棋位置矩阵、敌方兵棋位置矩阵、敌方上一步矩阵、是否为先手矩阵和地形矩阵;
72、步骤6.2:将描述战场态势信息的矩阵输入智能兵棋推演决策模型中,由智能兵棋推演决策模型中的策略网络解得到当前战术兵棋智能体指挥决策。
73、本发明的有益效果是:本发明聚焦于智能体在兵旗推演系统中自主决策产出过程的改进,构建了符合兵棋规则的战场态势感知方法,提高了策略的合理性;在传统策略-价值网络的基础上提出适用于兵棋推演的低优势策略-价值网络智能决策模型,帮助智能体加快产出作战决策;根据军事规则先验知识构建的作战场景判断模型,给予智能体动作行为的奖励;通过低优势策略-价值网络构建的智能兵棋推演决策模型,实现了在兵棋推演环境中帮助智能体较快学习到合理的策略。
- 还没有人留言评论。精彩留言会获得点赞!