基于多语义空间的视频文本检索方法、系统、设备及介质
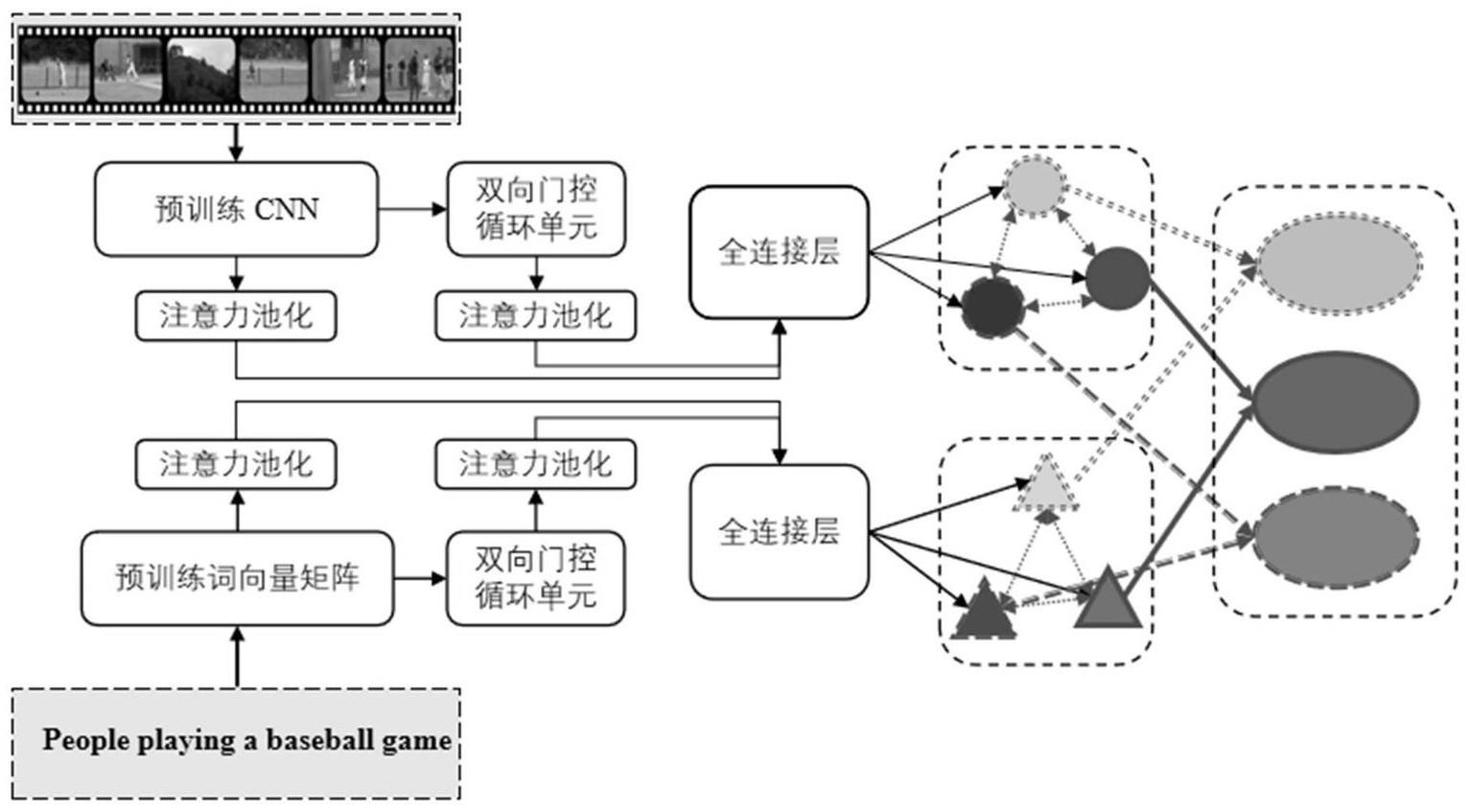
本发明属于计算机视觉和语言领域,主要涉及视频和文本之间的相互检索,更具体的说,是涉及一种基于多语义空间的视频文本检索方法、系统、设备及介质。
背景技术:
1、多媒体检索的研究已经发展了很长一段时间,但在过去的一段时间里学者们在研究单个模态数据的检索。在单模态数据检索场景下,用户通过输入文本内容来检索想要的其他文本内容或者输入一张图片去检索与这张图片相似的其他图片。但是,在互联网高速发展的今天,单模态数据检索很难满足用户日益增长的数据检索需求。所以,近年来多个模态之间的数据检索方法逐渐被研究人员关注。随着短视频的发展,文本与视频的检索在跨模态检索领域中成为了研究的焦点。
2、视频和文本之间的相互检索本质上是两个模态数据语义之间的检索。视频和文本数据的语义都非常丰富,比如视频中的背景、音乐、人物、动作等多种不同语义,文本中的动词、名词、多义词和语气词等多种不同的语义。因此,在文本检索视频的时候相当于多种不同的文本语义信息同时去匹配多种不同的视频语义信息。将视频和文本分别表示成单独的向量进行检索,等价于将视频和文本的多种语义都融合到一个公共向量空间中计算相似度来匹配。由于视频和文本语义的复杂性和多样性,所以通过单个向量检索的方式做精准的匹配是非常困难的。mee和hgr分别是从视频多语义和文本多语义出发,将视频和文本编码成指定语义上的公共空间进行匹配,这样可以一定程度上缓解在复杂、多样的语义场景下视频和文本相互检索问题。但是要想通过人工的方式找到合适的语义特征进行表示,是需要经验并花费不少时间的。此外,想要让视频和文本多语义空间进行匹配需要分别考虑视频的某个语义空间与文本的某个语义空间是否可以匹配,如果明显不能匹配的语义空间被我们强制进行匹配的话,最终的效果可能会变的更差。
技术实现思路
1、本发明的目的是为了克服现有技术中的不足,提出了一种基于多语义空间的视频文本检索方法、系统、设备及介质,不仅可以自适应的生成多个差异化的语义子空间,还可以通过多语义空间融合的方式来充分利用这些子空间提升视频和文本匹配的效果。语义子空间生成和匹配通过模型训练的过程来降低两个模态之间的语义鸿沟,进而保持跨模态空间的一致性。但是,对于同模态的语义空间需要保持差异。自适应生成的语义子空间的特点:同模态之间保持差异性,跨模态之间保持一致性。这种方式不需要人工去挖掘并表示视频或者文本不同的语义信息,并且可以根据实际的应用场景非常灵活的设置语义子空间的数量和子空间匹配的方法来提高检索性能。
2、本发明的目的是通过以下技术方案实现的。
3、一种基于多语义空间的视频文本检索方法,包括以下过程:
4、第一步:特征编码
5、①视频特征编码,得到视频特征vfeat和多个视频语义子空间
6、先对视频中的帧按照时间顺序进行采样,然后使用在imagenet数据集上预训练的cnn模型对采样出来的每一张图片都提取对应的特征向量,每个提取的特征向量都是2048维,然后将两个提取的特征向量拼接成一个4096维的特征向量,得到的视频帧级特征表示为一个特征序列{v1,v2,...,vn},其中vi表示n帧视频中第i帧视频的特征向量,然后使用注意力池化进一步得到视频帧级聚合特征vf;
7、将视频帧级特征序列{v1,v2,...,vn}通过双向门控循环单元提取视频的序列特征,双向门控循环单元输出的隐藏状态序列记为其中表示双向门控循环单元第j个时间步的隐藏状态,然后使用注意力池化进一步得到视频序列聚合特征vs;
8、将视频的帧级聚合特征vf与序列聚合特征vs拼接得到视频最终的特征表示vfeat;使用k个全连接层将视频特征映射成k个视频语义子空间,记为:
9、
10、②文本特征编码,得到文本特征tfeat和多个文本语义子空间
11、通过预训练现有的双编码模型得到预训练词向量矩阵,文本中的单词通过预训练词向量矩阵转换为词向量,文本就变成了词向量,记作:{t1,t2,...,tm};词向量通过双向门控循环单元得到词向量序列,两者分别通过注意力池化得到词向量聚合特征以及词向量序列聚合特征,将文本的词向量聚合特征与词向量序列聚合特征拼接得到文本特征的最终表示tfeat,接着使用k个全连接层映射成k个文本语义子空间,记为:
12、第二步:子空间学习
13、①跨模态子空间学习
14、余弦相似度函数计算不同模态向量之间的距离,使得相似的跨模态样本之间的距离更近,不相似的跨模态样本之间的距离更远,得出单个语义子空间跨模态匹配的损失函数,进而得到k个子空间跨模态匹配损失函数lcross,视频和文本跨模态子空间学习通过k个子空间跨模态匹配的损失函数挖掘正负样本;
15、②同模态子空间学习
16、将视频和文本的语义子空间分别转换成概率分布,对同模态的多个语义子空间分布,分别两两计算kl散度并令差异之和最大,得到视频最大化语义空间差异的损失函数和文本最大化语义空间差异的损失函数
17、视频和文本利用上述跨模态匹配损失函数lcross进行跨模态语义子空间一致性优化降低两个模态间的语义鸿沟,利用上述损失函数和进行同模态语义差异性优化,得到语义不同的子空间;同模态和跨模态两类损失同时作用于视频文本检索任务,得出加权损失函数l;
18、第三步:子空间融合匹配
19、通过加权融合多个语义子空间的相似度分数,来充分利用多个语义子空间实现视频和文本之间的互相检索。
20、第一步中所述视频帧级聚合特征vf
21、
22、
23、其中,vf是视频帧级聚合特征,γi表示第i帧视频帧级聚合权重,表示的是视频帧级注意力权重,relu是激活函数;
24、双向门控循环单元第j个时间步的隐藏状态表示为:
25、
26、
27、
28、其中,concat表示向量拼接;和分别表示正向和反向门控循环单元;和分别表示正向和反向gru在第j时间步的隐藏状态;
29、视频序列聚合特征vs表示为:
30、
31、
32、其中,vs是视频序列聚合特征,βi表示第i帧视频序列的聚合权重,表示的是视频序列注意力权重;
33、视频最终的特征表示vfeat如下:
34、vfeat=concat(vf,vs)
35、第二步中所述单个语义子空间跨模态匹配的损失函数:
36、
37、其中,表示的是第i个语义子空间匹配的损失函数,d表示的是语料库词典的大小;和分别表示与视频相关和不相关的文本,也分别称为是视频第i个语义子空间的正、负样本;和分别表示与文本相关和不相关的视频,也分别称为是文本第i个语义子空间的正、负样本;s表示的是余弦相似度函数;α表示距离常量;
38、第二步中所述k个子空间跨模态匹配损失函数表示为:
39、
40、第二步中视频的第i个语义子空间的概率分布表示为其中softmax函数将一个向量的各个值转换成概率分布,同理得到文本的第i个语义子空间的概率分布
41、第二步中所述视频最大化语义空间差异的损失函数为:
42、
43、第二步中所述文本最大化语义空间差异的损失函数为:
44、
45、第二步中所述加权损失函数l表示为:
46、
47、其中,wcross表示的是跨模态语义子空间一致性优化的权重,wsame表示的是同模态语义子空间差异性优化的权重。
48、第三步中相似度分数融合表示如下:
49、
50、其中,μo表示的是某个语义子空间相似度的权重,并且满足s表示余弦相似度函数;在对相似度矩阵求加权和之前将相似度矩阵执行归一化操作。
51、一种基于自适应多语义空间表示的视频文本检索系统,包括:
52、(1)特征编码模块,包括视频特征编码模块和文本特征编码模块;
53、所述视频特征编码模块用于获取每帧视频的特征向量,通过双向门控循环单元提取视频的序列特征,使用注意力池化分别得到视频的帧级聚合特征vf与序列聚合特征vs,拼接得到视频最终的特征表示vfeat,然后使用k个全连接层将视频特征映射成k个视频语义子空间,记为:
54、所述文本特征编码模块用于将文本变成词向量,通过双向门控循环单元得到词向量序列,两者分别通过注意力池化得到词向量聚合特征以及词向量序列聚合特征,拼接得到文本特征的最终表示tfeat,接着使用k个全连接;层映射成k个文本语义子空间,记为:
55、(2)子空间学习模块,包括跨模态子空间学习模块和同模态子空间学习模块;
56、所述跨模态子空间学习模块利用k个子空间的跨模态匹配损失函数lcross进行跨模态语义子空间一致性优化降低两个模态间的语义鸿沟;
57、所述同模态子空间学习模块利用视频最大化语义空间差异的损失函数和文本最大化语义空间差异的进行同模态语义差异性优化,得到语义不同的子空间;
58、同模态和跨模态两类损失同时作用于视频文本检索任务,得出加权损失函数l;
59、(3)子空间融合匹配模块通过加权融合多个语义空间的相似度分数,来充分利用多个语义子空间实现视频和文本之间的互相检索。
60、一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述的基于多语义空间的视频文本检索方法。
61、一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序被处理器执行时,实现上述的基于多语义空间的视频文本检索方法。
62、与现有技术相比,本发明的技术方案所带来的有益效果是:
63、视频文本检索本质上是视频和文本两个模态数据语义之间的相互检索。本发明为了对视频和文本的多种语义进行高效的表达,提出了一种基于自适应多语义空间表示的视频文本检索方法(adaptive semantic subspace representation,assr),共享多语义空间特征提取网络,通过同模态子空间之间保持差异性且跨模态子空间之间保持一致性的方式,来自适应地学习并表示不同模态数据的语义子空间。此外,本发明还通过多语义子空间融合匹配的方式来对视频和文本进行检索,从而提高检索性能。
- 还没有人留言评论。精彩留言会获得点赞!