强化学习数据采样方法、系统、设备和存储介质
本技术涉及强化学习的强化学习数据采样领域,特别是涉及一种强化学习数据采样方法、系统、设备和存储介质。
背景技术:
1、强化学习是机器学习领域的一类学习问题,它与常见的有监督学习、无监督学习等的主要区别在于,它是通过与环境之间的交互和反馈来学习的。强化学习比起有监督学习或无监督学习更加接近一个生命体的学习过程、更加具有智能性、更加接近“强人工智能”,因此近年来,强化学习在视频游戏、机器人控制、自然语言处理等很多领域都取得了瞩目的成果。在强化学习的训练过程中,往往需要海量的训练样本,因此,如何提高强化学习训练过程中的样本采集效率已成为当前强化学习系统研究的一个重要方向。
2、目前相关技术中,常用的强化学习框架包括google的seedrl、openai的five、ucb的rllib,然而这些现有框架对于普通研究者来说存在不同的问题。seedrl使用多个cpu(中央处理器)并行采样,并将采集的样本数据发送到高性能的中心服务器上进行训练。而中心服务器为了保证训练效率,使用了tpu(张量处理单元)进行前向推理和训练,对于普通研究者来说,该方法在使用时不可避免地会遇到性能的限制。openai five为了保证尽可能多的并行,将模型的前向推理和后向传播抽象到了不同的节点上,样本在采样节点、前向推理节点和后向传播节点(训练节点)之间传输。这种做法能够提高各部分计算资源的利用率,但是大大增加了网络传输成本和系统控制难度,在普通研究者计算资源有限的情况下对采样效率的提升有限。rllib是为了研究者快速实现强化学习算法所设计的通用强化学习库,不过其并没有针对并行采样进行效率上的优化,实验表明其采样效率相比于其他框架有一定的差距。另外,上述相关技术还存在共同的问题,即采样效率和训练效率的平衡通常需要通过人工设定来进行,这往往会导致各部分计算资源使用不均衡,从而造成了采样效率和训练效率的不平衡。
3、目前,针对相关技术中,强化学习在计算资源有限的情况下采样效率较低的问题,尚未提出有效的解决办法。
技术实现思路
1、本技术实施例提供了一种强化学习数据采样方法、系统、设备和存储介质,以至少解决相关技术中强化学习在计算资源有限的情况下采样效率较低的问题。
2、第一方面,本技术实施例提供了一种强化学习数据采样方法,其特征在于,包括:
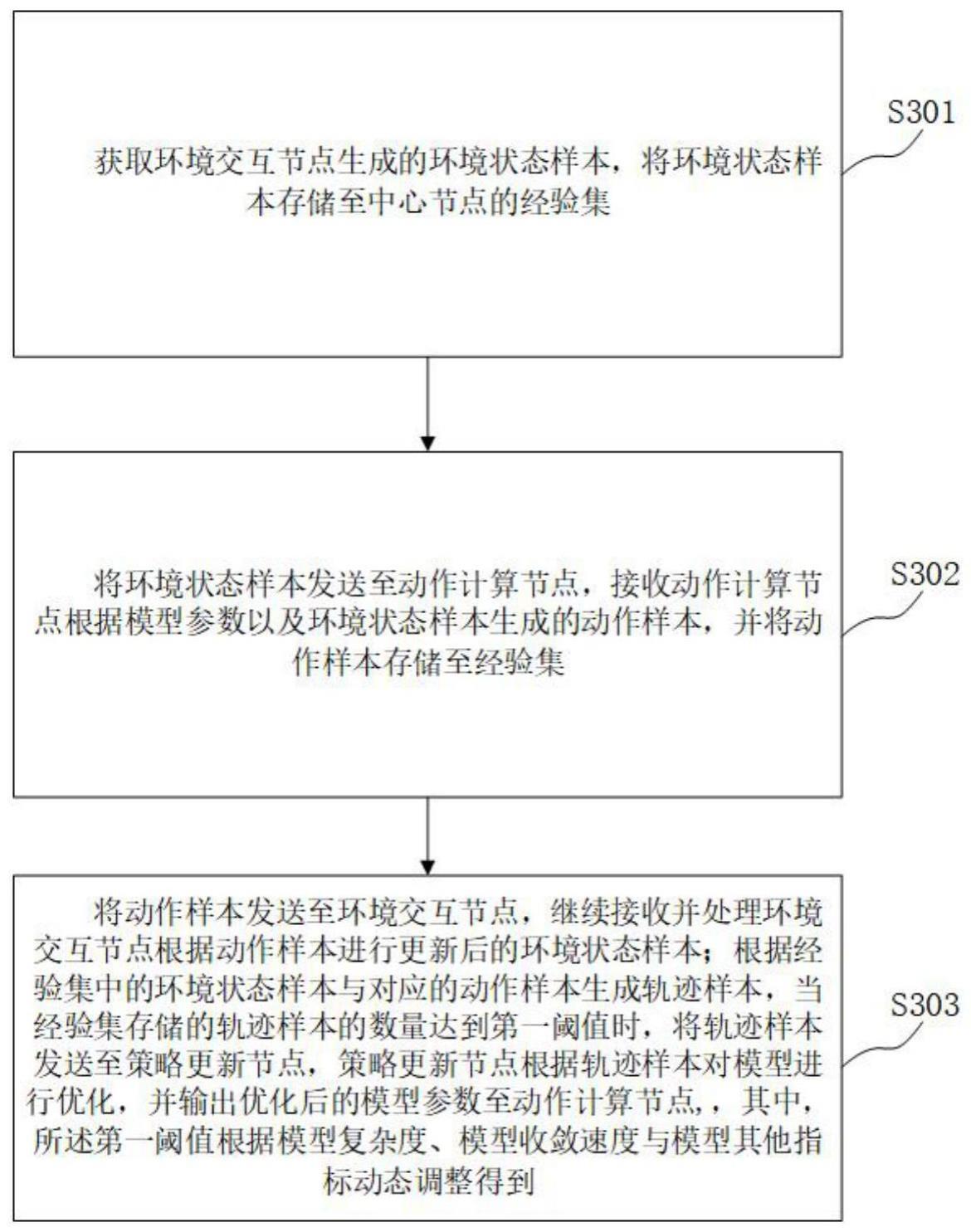
3、获取环境交互节点生成的环境状态样本,将所述环境状态样本存储至中心节点的经验集;
4、将所述环境状态样本发送至动作计算节点,接收所述动作计算节点根据模型参数以及所述环境状态样本生成的动作样本,并将所述动作样本存储至所述经验集;
5、将所述动作样本发送至所述环境交互节点,继续接收并处理所述环境交互节点根据所述动作样本进行更新后的所述环境状态样本;根据所述经验集中的所述环境状态样本与对应的所述动作样本生成轨迹样本,当所述经验集存储的所述轨迹样本的数量达到第一阈值时,将所述轨迹样本发送至策略更新节点,所述策略更新节点根据所述轨迹样本对模型进行优化,并输出优化后的所述模型参数至所述动作计算节点,其中,所述第一阈值根据模型复杂度、模型收敛速度与模型其他指标动态调整得到。
6、在其中一些实施例中,所述中心节点包括高速读写模块,所述高速读写模块用于创建所述中心节点与目标节点之间的会话,并基于所述会话对样本数据进行读写操作,其中,所述目标节点包括所述环境交互节点、所述动作计算节点或者所述策略更新节点,所述样本数据包括所述环境状态样本、所述动作样本或者所述轨迹样本。
7、在其中一些实施例中,所述方法还包括:
8、所述高速读写模块对所述经验集的存储空间进行分页封装,每一页所述存储空间对应不同的地址信息;
9、所述高速读写模块对不同页的所述存储空间进行并行读写。
10、在其中一些实施例中,所述高速读写模块还包括:页控制器,所述页控制器页控制器用于判断所述地址信息是否可用,并根据所述地址信息查找对应于所述地址信息的页存储信息。
11、在其中一些实施例中,当所述环境交互节点与所述中心节点进行连接时,所述方法包括:
12、所述高速读写模块在与所述环境交互节点首次连接时创建第一会话,基于所述第一会话处理所述环境交互节点与所述中心节点的连接任务,并用于保存第一地址信息;
13、所述页控制器接收并判断所述第一会话发送的所述第一地址信息是否可用,在所述第一地址信息可用的情况下,根据所述第一地址信息定位当前的第一样本记录,将当前的所述第一样本记录写入所述环境状态样本,更新所述第一地址信息,并将更新后的所述第一地址信息发送至所述环境交互节点。
14、在其中一些实施例中,当所述动作计算节点与所述中心节点进行连接时,所述方法包括:
15、所述高速读写模块在与所述动作计算节点首次连接时创建第二会话,基于所述第二会话处理所述动作计算节点与所述中心节点的连接任务,并保存第二地址信息与第三地址信息;
16、所述页控制器接收并判断所述第二会话发送的所述第二地址信息是否合法,在所述第二地址信息合法的情况下,根据所述第二地址信息定位当前的第二样本记录,将当前的所述第二样本记录写入所述动作样本;
17、所述高速读写模块通过所述第二会话发送所述第三地址信息至所述页控制器,所述页控制器根据所述第三地址信息定位第三样本记录,根据所述第三样本记录读取与所述动作样本对应的所述环境状态样本,并将所述环境状态样本发送至所述动作计算节点。
18、在其中一些实施例中,当所述策略更新节点与所述中心节点进行连接时,所述方法包括:
19、所述高速读写模块在与所述动作计算节点首次连接时创建第三会话,在当前页中所述环境状态样本与所述动作样本已经填满的情况下,获取所述页对应的第四地址信息;
20、所述页控制器接收并判断所述第三会话发送的所述第四地址信息是否合法,在所述第四地址信息合法的情况下,根据所述第四地址信息获取对应的所述页,并从对应的所述页中获取对应的轨迹样本;
21、所述高速读写模块通过所述第三会话将所述轨迹样本发送至所述策略更新节点。
22、在其中一些实施例中,将所述动作样本发送至所述环境交互节点,继续接收并处理所述环境交互节点根据所述动作样本进行更新后的所述环境状态样本包括:
23、接收所述环境交互节点发送的n个环境实例的初始状态与所述环境实例对应的实例编号,通过所述环境编号查找与所述环境实例对应的第五地址信息,其中,所述n个环境实例的初始状态由所述环境交互节点对所述n个环境实例初始化得到,n的数值根据所述环境交互节点与所述动作计算节点的等待时间进行动态调整,所述等待时间越长,n的数值越大;
24、接收所述动作样本,解析每个所述动作样本对应的所述实例编号,根据所述动作样本得到更新后的所述环境状态样本,将所述实例编号与更新后的所述环境状态样本发送至所述中心节点。
25、第二方面,本技术实施例提供了一种强化学习数据采样系统,用于存储和管理分布式环境中的经验集,其特征在于,包括:环境交互节点、动作计算节点、策略更新节点和中心节点;其中,
26、所述环境交互节点,用于生成环境状态样本,并将所述环境状态样本发送至所述中心节点;
27、所述动作计算节点,用于根据模型参数以及所述环境状态样本生成对应的动作样本并将所述动作样本发送至所述中心节点;
28、所述策略更新节点,用于根据轨迹样本对模型进行优化,并将优化后的所述模型参数发送至所述动作计算节点;
29、所述中心节点,用于接收并发送所述环境状态样本至所述动作计算节点,接收并发送所述动作样本至环境交互节点,并将所述环境状态样本、所述动作样本以及所述轨迹样本存储至所述经验集,当所述经验集存储的所述轨迹样本的数量达到第一阈值时,将所述轨迹样本发送至所述策略更新节点。
30、第三方面,本技术实施例提供了一种计算机设备,包括存储器、处理器以及存储在所述存储器上并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如上述第一方面中任一项所述的强化学习数据采样方法的步骤。
31、第四方面,本技术实施例提供了一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现如上述第一方面中任一项所述的强化学习数据采样方法的步骤。
32、相比于相关技术,本技术实施例提供的强化学习数据采样方法、系统、设备和存储介质,通过中心节点获取环境交互节点生成的环境状态样本,将环境状态样本存储至经验集,将环境状态样本发送至动作计算节点,接收并存储动作计算节点生成的动作样本,将动作样本发送至环境交互接单,继续接收并处理环境交互节点根据动作样本进行更新后的环境状态样本,并根据环境状态样本与动作样本生成轨迹样本,当经验集存储的轨迹样本的数量达到第一阈值时,将轨迹样本发送至策略更新节点,策略更新节点根据轨迹样本对模型进行优化,并将优化后的模型参数发送至动作计算节点,保证了各种节点信息的高效读写,解决了相关技术中强化学习在计算资源有限的情况下采样效率较低的问题。
33、本技术的一个或多个实施例的细节在以下附图和描述中提出,以使本技术的其他特征、目的和优点更加简明易懂。
- 还没有人留言评论。精彩留言会获得点赞!