一种求解多智能体路径规划问题的轻量化方法
本发明数据多智能体路径规划、多智能体强化学习领域,尤其涉及一种多智能体路径规划问题的轻量化方法。
背景技术:
1、近年来,随着科学技术的不断发展,自动化设施在各种场景的运用日渐频繁,其中部分场景需要自动化设施频繁来往于各种地区以执行不同的任务,如物流领域的物流机器人、仓储系统的货运小车以及自动化港口的运输车等,一般可以将此种自动化设施统称为自动运输车(automated guided vehicle,简称agv),若存在多个agv共同完成同一项任务可以称为agv群。agv群组成的系统一般具有数量众多、任务频次高且时效性要求高的特点。庞大的agv数量致使运作过程中,各个agv需要避免在行进路径上与其他agv相撞;高强度的调度频次需要一种保证agv群彼此不相撞的前提下,尽可能为每个agv规划较短的路径,以尽快完成任务;时效性要求所用方法能针对各种场景进行快速反应。针对上述三个要求,需要一种通用的算法模型完成agv群系统的路径规划问题,以求安全、高效的完成各种场景下的复杂任务。
2、其中一种现有技术为基于冲突检测的多智能体路径规划算法,该算法的底层以a*算法为每个智能体进行路径规划,顶层进行冲突检测,子在放生冲突的位置为对应智能体重新进行路径规划,直至完成目标或陷入循环。但是,该方案对环境的适应性较弱,处于稍复杂的环境则效果明显减弱:随智能体数量增多及障碍物分布变密,智能体最优路径相交逐渐频繁,需要耗费大量时间进行最优路径求解,且重新进行路径规划时经常陷入循环,导致无法求解。
3、另一种现有技术为结合强化学习与模仿学习求解多智能体路径规划,该算法采用强化学习算法,搭建以cnn为主的深度神经网络,运用训练后的神经网络模型对各个智能体进行动作选择指导,以其他算法进行多智能体路径规划所得结果作为专家数据,以此进行模仿学习。但是,该方案对数据需求量过大:需要耗费大量时间运行其他算法获取专家数据,且性能上很难超越该算法,深度神经网络自身训练同样需要大量数据,环境发生变化则需要重新进行数据获取。
4、现有技术中的局部观测状态获取方式一般以四个矩阵存储环境信息,分别为障碍物信息、智能体位置信息、其他智能体位置信息与各智能体目标信息,以0/1形式存储,实际过程中,四种矩阵中含有大量的0元素,而0元素在神经网络前向传播过程中会导致大量参数无效化,增大了达到拟合目的对应的神经网络规模。
5、现有技术中的一般均采用actor-critic模型作为算法基本框架,其中actor模型一般直接采用局部观测作为输入,有助于物理实现与快速反应;而critic模型用于指导actor模型训练,且仅在训练过程中起到重大作用,故而对critic模型进行改进既有利于提高模型的训练效果,而不影响实际操作时模型的快速反应能力。考虑多智能体系统的联合状态,其一般为多维度的、种类复杂的,若直接采用全局状态作为输入,则神经网络模型的训练时间复杂度随智能体数量增多而呈指数增长,其训练难度过大;若仅采用各个智能体状态的简单拼合,则会存在大量重复且无用的环境信息,且当智能体数量改变时,模型接口同样需要适当改变。
技术实现思路
1、本发明通过对现有以强化学习,或多智能体强化学习为基本算法原理的多智能体路径规划求解方法进行改进,包括简化其网络结构、改进局部信息存储方式、改进探索机制、降低其对专家数据的依赖程度。因此本发明提出以下技术方案:
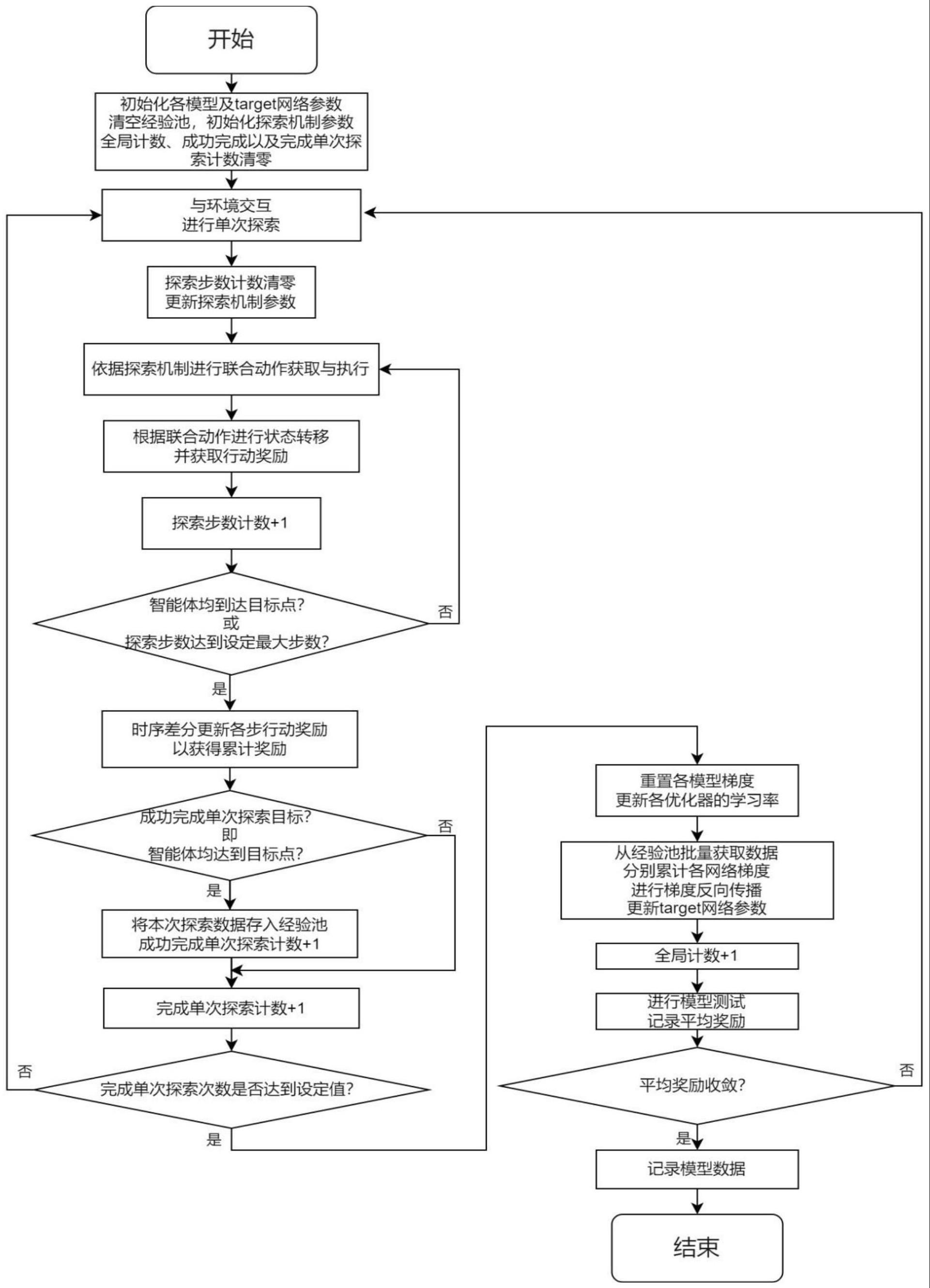
2、一种求解多智能体路径规划问题的轻量化方法,该方法具体包括以下步骤,
3、(1)初始化各模型以及target网络参数,清空经验池,初始化探索机制参数、全局计数清零、成功完成以及完成单次探索计数清零;各模型包括预处理模型、actor模型、critic模型;
4、(2)与环境交互,进行单次探索;
5、(3)探索步数计数清零,更新探索机制参数;
6、(4)依据探索机制进行联合动作获取与执行;
7、(5)根据联合动作进行状态转移,并获取行动奖励;
8、(6)探索步数计数增加一次;
9、(7)确定是否智能体均到达目标点或者探索步数计数达到设定最大步数;
10、(8)如果是,则时序差分更新各步动作行动奖励获得累计奖励,如果否,则回到步骤(4);时序差分更新各步动作行动奖励是用本步的即时行动奖励与后续预估行动奖励之和代替本步行动奖励,即为累加奖励;
11、(9)确定是否成功完成单次探索目标,也就是是否智能体均到达目标点;
12、(10)如果是,将本次探索数据存入经验池,且成功完成单次探索计数增加一次,如果否,则完成单次探索计数增加一次;所述探索数据包括各智能体各步的局部观测信息、探索过程中的动作与累加奖励记录、是否成功完成单次探索的标识;
13、(11)判断完成单次探索计数是否达到设定值;
14、(12)如果是,重置预处理模型、actor模型、critic模型梯度;如果否,回到步骤(2);
15、(13)从经验池批量获取数据分别累计各网络梯度进行梯度反向传播,更新target网络参数;
16、(14)全局计数增加一次;
17、(15)进行各模型测试;
18、(16)平均奖励是否收敛;平均奖励为各模型测试中所有智能体每一步动作获取的累加奖励之和除以智能体数量,再除以步数;
19、(17)如果是,则记录模型参数数据,如果否,则回到步骤(2);
20、(18)结束。
21、本发明具有以下有益技术效果:
22、1)简化神经网络规模,改进局部信息存储方式,用更少的参数求解问题;
23、2)改进探索机制,使模型训练不依赖专家数据,不参照其他算法;
24、3)对输入数据进行维度控制,避免随智能体数量增多导致维度灾难;
25、4)神经网络模型易于搭建,局部信息存储利用率高,且无需其他算法所得数据作为参考,训练易于实现,实际训练时耗时极低;
26、5)采用注意力机制对神经网络的输入数据进行维度控制,既做到综合考虑全局信息,又无需随智能体数量变化修改网络模型,提高了泛用性;
27、本发明通过对现有以强化学习,或多智能体强化学习为基本算法原理的多智能体路径规划求解方法进行改进,包括简化其网络结构、改进局部信息存储方式、改进探索机制、降低其对专家数据的依赖程度。
技术特征:
1.一种求解多智能体路径规划问题的轻量化方法,其特征在于,该方法具体包括以下步骤:
2.根据权利要求1所述的一种求解多智能体路径规划问题的轻量化方法,其特征在于,所述探索机制采用以下公式:
3.根据权利要求1所述的一种求解多智能体路径规划问题的轻量化方法,其特征在于,局部观测信息为两个矩阵,分别存储智能体及障碍物信息与目标点信息,存储智能体及障碍物信息的矩阵称为地图矩阵,其中本智能体信息记为1,对单个智能体而言,其行进过程中,其他智能体同样可以看作障碍物,将其他智能体与障碍物均记为-1,若智能体间种类存在明显区分也可以对其他智能体进行异种标记;存储目标点信息的矩阵称为目标点矩阵,对本智能体目标点位置记为1,其他智能体目标位置记为-1,其他无标识位置均为0。
4.根据权利要求1所述的一种求解多智能体路径规划问题的轻量化方法,其特征在于,步骤1中的critic模型采用结合注意力机制构建的价值评估模型,其建模方法具体包括以下步骤:
技术总结
本发明提出一种求解多智能体路径规划问题的轻量化方法,具体包括以下步骤:初始化,清零;依据探索机制获取并执行动作;获取行动奖励;判断是否完成单次探索,存储探索数据,成功单次探索计数,判断数据收敛,记录模型数据。通过对现有数据以强化学习,或多智能体强化学习为基本算法原理,对多智能体路径规划求解方法进行改进,包括简化其网络结构、改进局部信息存储方式、改进探索机制、降低其对专家数据的依赖程度。
技术研发人员:凌强,金靖昆
受保护的技术使用者:中国科学技术大学
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!