一种基于视听双模态的多目标三维定位方法与流程
本发明涉及三维定位,尤其涉及一种基于视听双模态的多目标三维定位方法。
背景技术:
1、近年来新一轮人工智能科技研发热潮持续高涨,作为其中的重要研究方向之一的人机交互技术——使用某种对话语言或交互方式实现了人与智能设备的信息交换,对于当前人机交互产品成本的降低,以及提升智能设备的用户体验度等方面发挥了十分显著的作用。目标定位是人机交互的核心技术,该技术是通过模拟现实场景中的人类视觉选择注意力功能,实现对多个目标的三维位置的定位,可用于目标检测与异常事件分析等;该技术是智能安防、健康监控、智能家居等应用领域的重要基础。
2、通过声源定位是常见目标定位方法,但在一般环境下,由于背景噪音与混响使得麦克风阵列对声音的处理效果并不理想,而且在多种声音的短暂重叠容易发生错检漏检等问题,从而破坏声源定位的准确性。其次传统的声学单模态定位算法,即声源定位算法需要依赖到达方向或者是到达时差估计,存在实时性和实用性较差的缺陷。在视觉定位方面,在光线变化快速和杂乱和昏暗的环境下,视觉识别的能力会降低。同时,视觉识别在摄像头数目缺乏的条件下会产生识别的死角。由上可得,单纯的声音定位算法和视觉识别定位算法都存在一定程度上的不足,视听结合能够克服单模态下目标定位的不足。在视听结合定位下,当跟踪对象被遮挡以及在摄像头之外时,用声音定位来代替视觉跟踪。但这个方法对音频有很高的要求,特别是当出现多个目标时,单纯的声音定位并不能解决多个目标的音频数据间的相互依赖关系。
技术实现思路
1、本发明的目的在于提出一种基于视听双模态的多目标三维定位方法,克服传统的声学多模态处理声音效果不佳和需要高精度设备等缺陷,解决多目标定位存在识别准确性不足的问题。
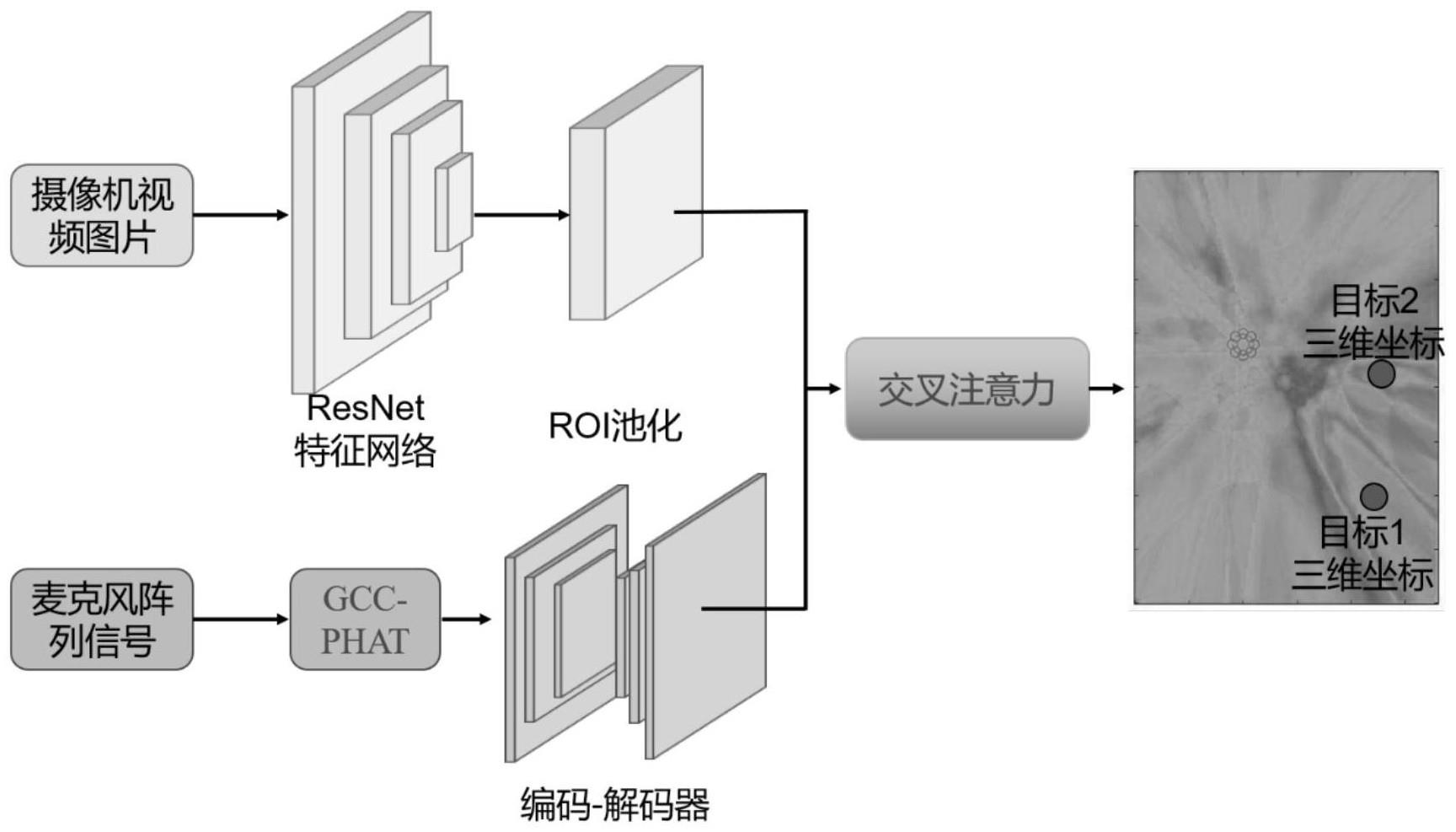
2、为达此目的,本发明采用以下技术方案:一种基于视听双模态的多目标三维定位方法,包括下述步骤:
3、获得第一空间特征:采集视频图像信号,并通过resnet主干特征网络提取目标特征,通过roi池化层从目标特征获得目标的第一空间特征fv;
4、获得第二空间特征:采集音频信号,通过广义互相关相位变换方法获得目标距离的二维特征图,通过编码解码器将目标距离的二维特征图映射为第二空间特征fa;
5、获得目标三维空间坐标:通过交叉注意力机制将第一空间特征fv和第二空间特征fa融合,获得多个目标的三维空间坐标。
6、优选的,在所述获得第一空间特征的步骤中,通过resnet主干特征网络提取目标特征具体为采用残差块对视频图像信号进行卷积运算并加入残差辅助网络以及relu激活函数,将主干网络自下而上连接分为五个阶段的第一特征图,将每个阶段的第一特征图经过卷积核后将各个阶段的通道数统一获得第二特征图,每个阶段输出的第二特征图采用自上而下的连接方式,对第二特征图进行上采样并进行相加融合操作后进行卷积核处理获得对应阶段的预测图,将五个阶段的预测图通过roi池化层获得目标的第一空间特征fv。
7、优选的,相邻两个阶段中,位于上阶段的第一特征图输出特征大小为位于下阶段的第一特征图输出特征大小的一半;每个阶段的第一特征图经过1*1卷积核后将各个阶段的通道数统一获得第二特征图;进行相加融合操作后进行3*3卷积核处理获得对应阶段的预测图。
8、优选的,在所述获得第二空间特征的步骤中,采集音频信号通过多对呈阵列分布的麦克风,通过广义互相关相位变换方法计算每对麦克风的广义互相关相位变换系数,公式为:
9、
10、其中和分别表示第m1和m2个麦克风接收到声音信号的傅里叶变换,*表示复共轭计算,τ为时延值,j为虚数;ω为角频率;e为自然对数;
11、通过广义互相关相位变换系数获得总样本数,采用补零方式展开成二维特征图,将二维特征图送入编码解码器获得第二空间特征fa。
12、优选的,所述编码解码器包括两个卷积模块和四个解卷积模块。
13、优选的,将第一空间特征fv和第二空间特征fa进行线性投影,根据下列公式计算获得查询qv,键kv和值va:
14、qv=fvwq;
15、ka=fawk;
16、va=fawv;
17、其中wq、wk和wv为训练矩阵;
18、将查询qv,键kv和值va代入下列公式,获得音频注意力特征fav:
19、
20、其中softmax()为软最大值函数,输出为每个类别可能性,t为矩阵转置,d为查询qv的维度;
21、将音频注意力特征fav与第一空间特征fv进行加权融合,经过极大值抑制后获得多个目标的三维空间坐标。
22、优选的,还包括预训练模型步骤,使用cav3d扫描数据集中的多段音视频作为训练集,选取两段音视频作为测试集,采用迁移学习策略,resnet主干特征网络使用ms-coco预训练模型,损失函数为:
23、
24、其中lcls为目标类别损失函数,t为输入视频总帧数,gi为第i帧视频目标真实三维坐标,pi为第i帧视频目标预测三维坐标。
25、本发明的一个技术方案的有益效果:通过resnet主干特征网络提取视频图像信号的目标特征,然后经过roi池化层得到目标的第一空间特征;通过广义互相关相位变换方法对音频信号进行处理,获得目标的第二空间特征;对第一空间特征和第二空间特征通过交叉注意力机制进行融合,得到多个目标的三维空间坐标。本发明克服传统的声学多模态处理声音效果不佳和需要高精度设备等缺陷,解决多目标定位存在识别准确性不足的问题。
技术特征:
1.一种基于视听双模态的多目标三维定位方法,其特征在于,包括下述步骤:
2.根据权利要求1所述的一种基于视听双模态的多目标三维定位方法,其特征在于,在所述获得第一空间特征的步骤中,通过resnet主干特征网络提取目标特征具体为采用残差块对视频图像信号进行卷积运算并加入残差辅助网络以及relu激活函数,将主干网络自下而上连接分为五个阶段的第一特征图,将每个阶段的第一特征图经过卷积核后将各个阶段的通道数统一获得第二特征图,每个阶段输出的第二特征图采用自上而下的连接方式,对第二特征图进行上采样并进行相加融合操作后进行卷积核处理获得对应阶段的预测图,将五个阶段的预测图通过roi池化层获得目标的第一空间特征fv。
3.根据权利要求2所述的一种基于视听双模态的多目标三维定位方法,其特征在于,相邻两个阶段中,位于上阶段的第一特征图输出特征大小为位于下阶段的第一特征图输出特征大小的一半;每个阶段的第一特征图经过1*1卷积核后将各个阶段的通道数统一获得第二特征图;进行相加融合操作后进行3*3卷积核处理获得对应阶段的预测图。
4.根据权利要求1所述的一种基于视听双模态的多目标三维定位方法,其特征在于,在所述获得第二空间特征的步骤中,采集音频信号通过多对呈阵列分布的麦克风,通过广义互相关相位变换方法计算每对麦克风的广义互相关相位变换系数,公式为:
5.根据权利要求4所述的一种基于视听双模态的多目标三维定位方法,其特征在于,所述编码解码器包括两个卷积模块和四个解卷积模块。
6.根据权利要求1所述的一种基于视听双模态的多目标三维定位方法,其特征在于,将第一空间特征fv和第二空间特征fa进行线性投影,根据下列公式计算获得查询qv,键kv和值va:
7.根据权利要求1所述的一种基于视听双模态的多目标三维定位方法,其特征在于,还包括预训练模型步骤,使用cav3d扫描数据集中的多段音视频作为训练集,选取两段音视频作为测试集,采用迁移学习策略,resnet主干特征网络使用ms-coco预训练模型,损失函数为:
技术总结
本发明公开了一种基于视听双模态的多目标三维定位方法,包括下述步骤:获得第一空间特征:采集视频图像信号,并通过ResNet主干特征网络提取目标特征,通过ROI池化层从目标特征获得目标的第一空间特征F<subgt;v</subgt;;获得第二空间特征:采集音频信号,通过广义互相关相位变换方法获得目标距离的二维特征图,通过编码解码器将目标距离的二维特征图映射为第二空间特征F<subgt;a</subgt;;获得目标三维空间坐标:通过交叉注意力机制将第一空间特征F<subgt;v</subgt;和第二空间特征F<subgt;a</subgt;融合,获得多个目标的三维空间坐标;本发明旨在提供一种基于视听双模态的多目标三维定位方法,克服传统的声学多模态处理声音效果不佳和需要高精度设备等缺陷,解决多目标定位存在识别准确性不足的问题。
技术研发人员:杨森泉,杨海东,李泽辉
受保护的技术使用者:佛山市南海区广工大数控装备协同创新研究院
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!