一种基于多模态预训练融合中文拼写纠正技术
本发明涉及一种中文拼写纠正技术,属于自然语言处理。
背景技术:
1、随着互联网、移动设备等技术的普及,中文的使用范围越来越广泛,中文拼写纠正技术也越来越受到重视。中文拼写纠正技术的意义在于能够自动检测和纠正中文拼写错误,提高中文文本的准确性和可读性。该技术可以帮助人们在使用中文输入法时自动纠正错误的字词,减少输入错误的概率,提高输入效率;同时,在编辑、写作等场景下,也能够及时发现和纠正拼写错误,保证文本的质量。特别是对于在线搜索、社交网络、电子邮件、电子商务等各种应用场景,中文拼写纠正技术更是不可或缺的重要技术。然而目前的中文文本纠错技术仍存在提升空间,本发明提出的多模态预训练融合的中文拼写纠正技术着重解决以下问题:
2、一、根据领域内统计,中文文本中的拼写错误有76%是使用了与正确字发音相似的字造成的;有46%是使用了与正确字相似字形的字造成的。本发明引入中文字的文本信息、字形信息、字音信息,并将三种信息更合理地融合;
3、二、目前中文文本纠正技术大多使用大规模预训练语言模型来获取语义信息,如bert、roberta等。但是这些模型的预训练数据并非全部与文本纠正领域有关,预训练任务也与中文文本纠正存在差距。因此本发明分别为文本编码、字音编码和字形编码三个预训练过程设置了与中文文本纠正相关的预训练任务,领域内相关的预训练数据,适合建模不同特征的模型结构。
技术实现思路
1、本发明为解决现有中文拼写错误纠正技术的准确度和发现速度难以满足实际需要的问题,进而提出一种基于多模态预训练融合中文拼写纠正技术。
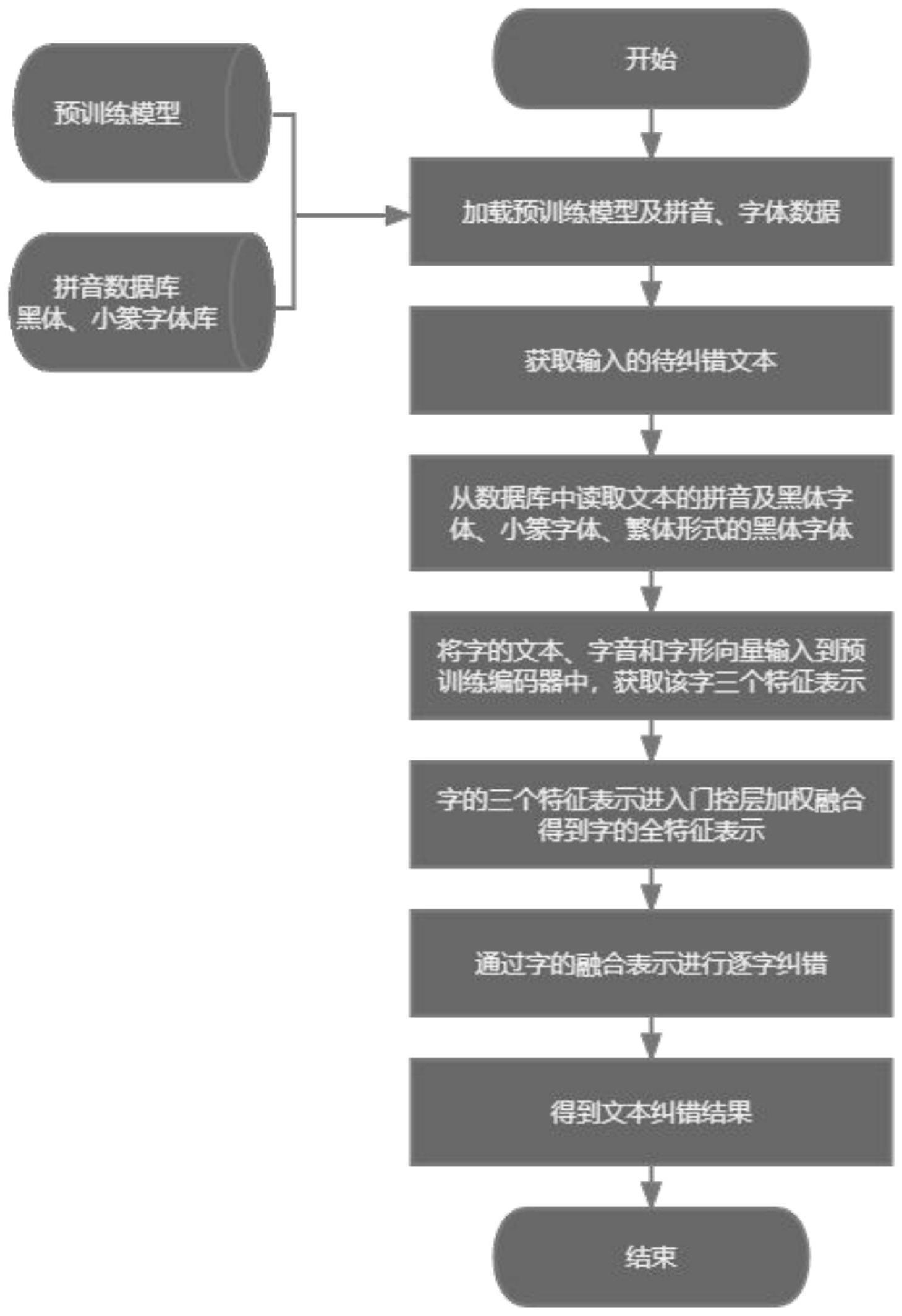
2、本发明为解决上述问题采取的技术方案是:本发明的步骤如下:
3、步骤1、对于输入的中文句子,从数据库中读取每个字的拼音和音调,并加载该字的黑体字体、小篆字体、该字繁体形式的黑体字体作为字音、字形信息;
4、步骤2、将句子及其对应字的拼音、字体分别映射为向量,再经过不同的编码器和bert获取同维度的编码表示;
5、步骤3、将字的字音字形编码表示和文本编码表示分别输入投影层,对特征做非线性变换和加权和,获取进一步表示;
6、步骤4、将字的字音字形编码表示和文本编码表示输入门控层,对三种特征表示做加权融合,进而获得中文字的表示;
7、步骤5、将字的三个模态融合的表示输入bert,使用词表大小的线性层做分类器,对从bert输出的表示进行分类,视最高得分的类别为系统最终的预测结果。
8、进一步的,步骤2中采用12层bert对中文字做编码,1层gru网络和4层的bert对中文字的拼音做编码,采用5层resnet和4层的bert对不同字体进行编码。具体过程包括以下步骤:
9、步骤2.1对于输入的每个中文字t,获取其拼音音调序列和黑体、黑体、小篆字体图;
10、步骤2.2将中文字根据bert的词嵌入映射为768维的向量,将字的拼音序列根据可训练嵌入层映射为768维向量,将三种字体转为位图形式的向量并拼接,即通道数为3;
11、步骤2.3使用12层bert对字向量做建模,并取最后三层的输出向量做平均,形成字的语义表示,使用gru的最后一个时间步的向量输入4层bert对拼音向量进行编码,使用5层resnet得到768维向量,并输入4层bert进一步编码,最终三个编码表示的维度都为768。
12、进一步的,步骤3中的投影层提供非线性变换,相当于对编码表示做self-attention,三个表示的投影层共享参数,
13、proj(rep)=(w2(tanh(w1*rep+b1))+b2)·rep (1),
14、公式(1)中rep表示步骤2中获取的各模态编码表示,w1和w2、b1和b2为可训练参数,h为rep的最后一维的维数,tanh为双曲正切函数,提供非线
15、性变换能力,由于投影层含两个线性层,对三个模态的投影头做权重共享可大幅降低参数的同时保证模型的纠错效果。
16、进一步的,步骤4中采用一种门控机制对步骤3获得的三个模态的表示做融合:
17、通过门控层学习如何对不同句子中字的词义、字形和字音信息学习权重,并做加权融合:
18、
19、
20、
21、hfuse=gt·ht+gp·hp+gv·hv(5),
22、公式(2)、(3)、(4)、(5)中,wt、wp、wv、bt、bp、bv均表示可训练参数,wt、wp、wv均为rh*3h,h表示隐藏层维度数,采用sigmoid形成阈值,该阈值随着训练调整,最终三个模态融合的表示为hfuse。
23、进一步的,步骤5中使用三层bert和词表大小的线性层做分类。
24、进一步的,步骤2中所使用的预训练模型,是采用适用于不同模态的不同数据和不同模型结构训练得到的。
25、本发明的有益效果是:本发明所涉及的基于多模态预训练融合的中文拼写纠正技术,通过对字的文本、字音和字形三个模态的编码器,使用针对性拼写纠正任务、领域内训练数据做预训练,并采用更合理的方式对三个模态的编码信息做融合,进一步整合中文字的三种信息,从而得到更好的融合中文文本字音字形信息的中文拼写纠正系统。由于多数中文文本拼写错误都是使用了与正确字字音字形上相近的混淆字导致的,本发明方法可以让使用者较快地找到文本中出现的拼写错误,提高校正效率。本发明也可以应用于搜索技术中,用以对用户输入的查询信息作校正,更好地帮助检索系统识别用户意图和查询目标,提升搜索质量并优化用户体验;或是用于文章校验系统中,对于一些准确以来较高的公文稿做校正,确保文章质量;或是用于对于图片转文字文本的校验中,进一步提高文本可读性、可用性;或是用于办公系统中,对基础文稿的拼写错误进行提示,提高文件质量及办公效率。
技术特征:
1.一种基于多模态预训练融合中文拼写纠正技术,其特征在于:所述一种基于多模态预训练融合中文拼写纠正技术是通过如下步骤实现的:
2.根据权利要求1所述的一种基于多模态预训练融合中文拼写纠正技术,其特征在于:步骤2中采用12层bert对中文字做编码,1层gru网络和4层的bert对中文字的拼音做编码,采用5层resnet和4层的bert对不同字体进行编码。具体过程包括以下步骤:
3.根据权利要求1所述的一种基于多模态预训练融合中文拼写纠正技术,其特征在于:步骤3中的投影层提供非线性变换,相当于对编码表示做self-attention,三个表示的投影层共享参数,
4.根据权利要求1所述的一种基于多模态预训练融合中文拼写纠正技术,其特征在于:步骤4中采用一种门控机制对步骤3获得的三个模态的表示做融合:
5.根据权利要求1所述的一种基于多模态预训练融合中文拼写纠正技术,其特征在于:步骤5中使用三层bert和词表大小的线性层做分类。
6.根据权利要求1所述的一种基于多模态预训练融合中文拼写纠正技术,其特征在于:步骤2中所使用的预训练模型,是采用适用于不同模态的不同数据和不同模型结构训练得到的。
技术总结
一种基于多模态预训练融合中文拼写纠正技术,它涉及一种中文拼写纠正技术。本发明为了解决现有中文拼写错误纠正技术的准确度和发现速度难以满足实际需要的问题。本发明的步骤为:对于输入的中文句子,从数据库中读取每个字的拼音和音调,并加载该字的黑体字体、小篆字体、该字繁体形式的黑体字体作为字音、字形信息;将句子及其对应字的拼音、字体分别映射为向量,再经过不同的编码器和BERT获取同维度的编码表示;对特征做非线性变换和加权和,获取进一步表示;将字的字音字形编码表示和文本编码表示输入门控层,对三种特征表示做加权融合,进而获得中文字的表示;将字的三个模态融合的表示输入BERT。本发明属于自然语言处理技术领域。
技术研发人员:赵铁军,朱聪慧,徐冰,刘梓航,曹海龙,杨沐昀
受保护的技术使用者:哈尔滨工业大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!