施工质量设计规范的事件自动抽取方法
本发明属于大数据处理,涉及一种施工质量设计规范的事件自动抽取方法。
背景技术:
1、建设工程施工质量的优劣直接影响工程建设的速度,也关系到建筑工程的耐久性、可靠性、实用性,关系到企业的经济效益以及社会效益,更关系到人民群众的生命财产安全等民生问题。
2、在建筑、工程和施工(aec)行业中,建筑环境的整个生命周期由各种法规、需求和标准管理,建筑项目必须根据许多建筑规范进行检查。而人工检查的方法耗费极多,自动化的规范检测一直是研究人员的重点。同时,自动检查需要一个有效的数据集来完成对规范的检测。
3、虽然现有建筑规范检查文件较多,但是仅有有数、数据量较小以及数据针对性明显的公开中国建筑数据集可以用于目前的自动规范检查研究,而且特定于施工质量的规范数据集极难查询到,公开数据集的缺乏致使研究需要大量前期工作,阻碍了研究的快速进行、降低研究的效果,甚至导致研究不能开展。
技术实现思路
1、本发明的目的是提供一种施工质量设计规范的事件自动抽取方法,该方法能够实现建筑领域施工质量设计规范事件化,从而生成事件数据集。
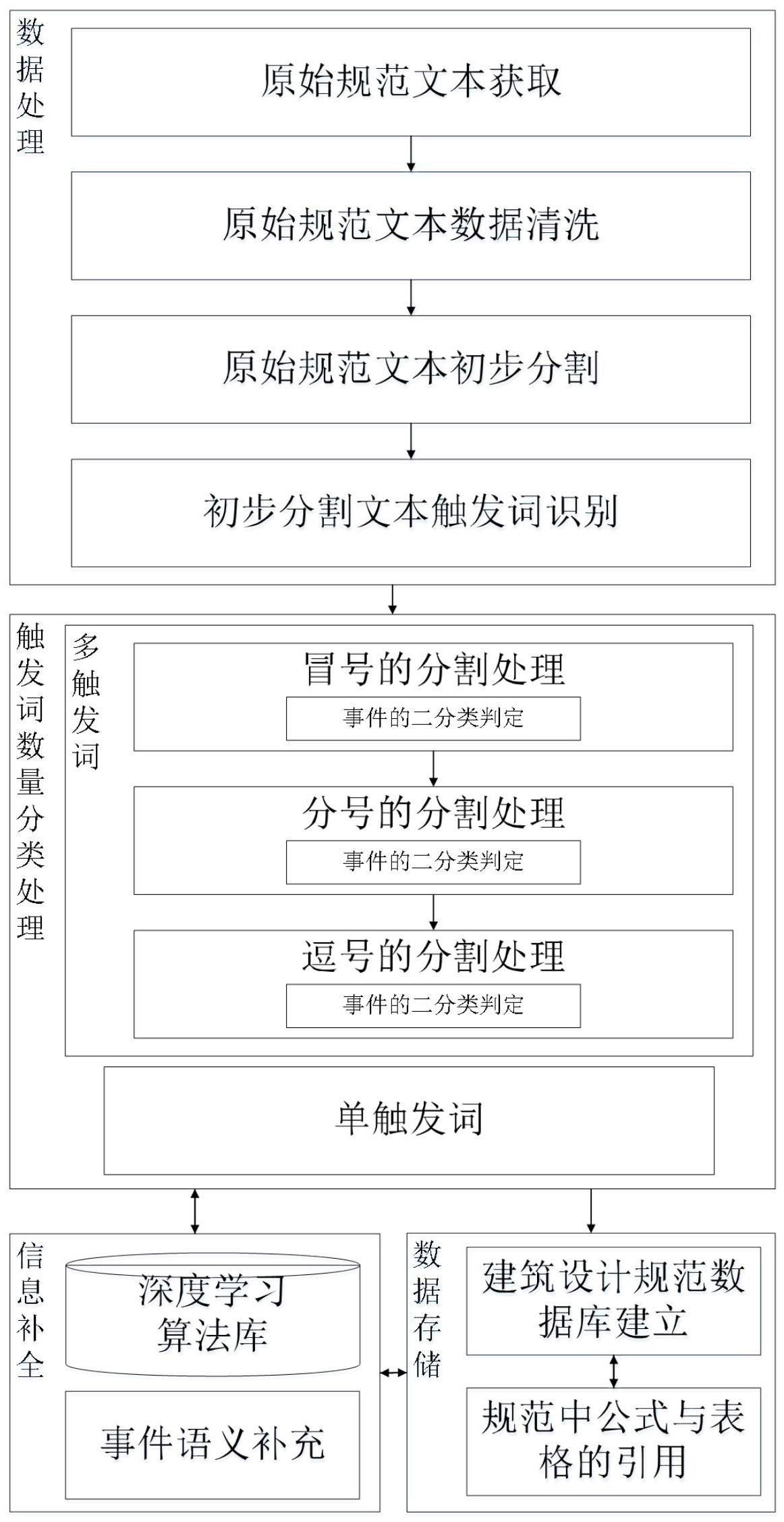
2、本发明所采用的技术方案是,施工质量设计规范的事件自动抽取方法,步骤如下:
3、步骤1,获取原始规范文本;
4、步骤2,对步骤1获取的文本进行数据清洗,去除无用句;
5、步骤3,利用句号对步骤2处理后的文本做初步分割,获得完整事件表达;
6、步骤4,使用深度学习模型完成对事件触发词的识别;
7、步骤5,针对事件存在单触发词和多触发词情况分别进行处理;
8、步骤6,基于步骤5的处理结果进行事件语义补充;
9、步骤7,基于步骤6所得结果建立数据库;
10、步骤8,在数据库中通过查询的方式对事件包含的公式与表格进行引用。
11、本发明的特点还在于:
12、步骤1中,从建标网上爬取、纸质建筑规范书籍上获取原始规范文本。
13、步骤4中,深度学习模型为bert+bilstm+crf模型,模型的输出为当前事件句以及句内字符的标签,存在当前事件句仅包含一个事件触发词即单触发词和当前事件句包含多个事件触发词即多触发词两种情况,事件触发词是事件存在的标志,主要以谓词形式存在。
14、步骤5中,针对单触发词,能够独立支撑完整的事件语义表达,将当前独立、完整事件直接输出即可;
15、针对多触发词,对其中包含的冒号、分号以及逗号依次进行识别并分割。
16、步骤5中对于多触发词中冒号、分号以及逗号的处理过程如下:
17、步骤a)对于冒号的分割处理,以冒号作为事件的分割线,判断冒号后的句子是否为完整事件;若冒号后的句子是完整事件,则直接分割得到结果;若冒号后的句子不是完整事件,则获取冒号前的句子主语,作为冒号后不完整事件的主语补充候选,由不完整事件从候选中择优补充完整,择优的标准为选择余弦相似度最高,具体如下公式(1)所示:
18、
19、其中,a和b代表句子向量a和句子向量b,a·b代表两个向量的点积,||a||和||b||分别表示两个向量的模长;
20、步骤b)对于分号的分割处理,以分号作为事件的分割线,判断每个分句是否能够独立成事件,当不能独立成为事件的分句出现,使用分句间余弦相似度最高判定方式以及步骤a)中主语补充方式完成事件语义补充,最终完成事件的分割抽取;
21、步骤c,对于逗号的分割处理,以逗号作为事件的分割线,识别分割后的每个单句中是否存在触发词,当分割后的单句中不存在触发词,则认为当前单句为下一单句或者事件的状态事件;若存在,则认为是一个单独的事件,
22、然后判断是否为完整事件,完整则查看下一单句,若不完整,则使用步骤b)中主语补充方式完成事件语义补充。
23、步骤6中,使用k-means++聚类算法挖掘计量单位表与计量词表,将包含计量单位的事件句匹配出来,并使用jieba分词器分词获得计量词与计量单位,使用k-means++聚类算法对计量词与计量单位聚类,得到聚类结果,根据存在计量单位与计量词的事件,做计量词与计量单位存在联系的数量统计,将计量词和计量单位聚类结果做一对一关联,在存在计量单位事件的名词之后和动词之前、名词之后和停用词之前,根据聚类与关联结果补充计量词,最后用皮尔逊相关系数计算补充计量词后事件句与补充前事件句相似度,皮尔逊相关系数计算公式如下:
24、
25、其中,x和y分别是补充计量词前的事件句与补充计量词后的事件句的向量,σxσy为x和y的标准差乘积,μx和μy分别为x和y的期望值,e[(x-μx)(y-μy)]为变量x和变量y的协方差。
26、本发明的有益效果是,本发明通过对建筑领域施工质量设计规范进行事件自动抽取,获取规范的事件数据集与事件中提到的公式、表格,从而建立数据库,以用于后续的事理图谱生成、可视化呈现、事件预测、问答系统构建、建筑现场媒体监测等工作。
技术特征:
1.施工质量设计规范的事件自动抽取方法,其特征在于:步骤如下:
2.根据权利要求1所述的施工质量设计规范的事件自动抽取方法,其特征在于:所述步骤1中,从建标网上爬取、纸质建筑规范书籍上获取原始规范文本。
3.根据权利要求1所述的施工质量设计规范的事件自动抽取方法,其特征在于:所述步骤4中,深度学习模型为bert+bilstm+crf模型,模型的输出为当前事件句以及句内字符的标签,存在当前事件句仅包含一个事件触发词即单触发词和当前事件句包含多个事件触发词即多触发词两种情况,事件触发词是事件存在的标志,主要以谓词形式存在。
4.根据权利要求3所述的施工质量设计规范的事件自动抽取方法,其特征在于:所述步骤5中,针对单触发词,能够独立支撑完整的事件语义表达,将当前独立、完整事件直接输出即可;
5.根据权利要求4所述的施工质量设计规范的事件自动抽取方法,其特征在于:所述步骤5中对于多触发词中冒号、分号以及逗号的处理过程如下:
6.根据权利要求1所述的施工质量设计规范的事件自动抽取方法,其特征在于:所述步骤6中,使用k-means++聚类算法挖掘计量单位表与计量词表,将包含计量单位的事件句匹配出来,并使用jieba分词器分词获得计量词与计量单位,使用k-means++聚类算法对计量词与计量单位聚类,得到聚类结果,根据存在计量单位与计量词的事件,做计量词与计量单位存在联系的数量统计,将计量词和计量单位聚类结果做一对一关联,在存在计量单位事件的名词之后和动词之前、名词之后和停用词之前,根据聚类与关联结果补充计量词,最后用皮尔逊相关系数计算补充计量词后事件句与补充前事件句相似度,皮尔逊相关系数计算公式如下:
技术总结
本发明公开了一种施工质量设计规范的事件自动抽取方法,包括:获取并预处理原始规范数据集;输入至预训练的语言模型中进行处理,得到预处理数据集的事件触发词识别结果;采用单触发词与多触发词分类处理方式,利用规则匹配方法和深度学习模型联合处理多触发词情况,对预处理数据集多触发词识别结果按冒号、分号、逗号顺序依次处理,并利用深度学习方法和相似度方法得到完整元事件数据集;根据聚类方法挖掘计量单位与计量词关联关系,并使用相似度方法进一步补充事件语义,提高事件表达能力。本发明通过语法匹配和深度学习结合的方法,完成规范检查数据生成,有助于增加公开的中国建筑数据集数量。
技术研发人员:黑新宏,鲍一豪,朱磊,赵钦,杨明松,何敏,孟海宁,姬文江,王一川
受保护的技术使用者:西安理工大学
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!