基于机器学习的代码敏感信息及硬编码检测方法及装置与流程
本发明涉及信息安全,具体而言,涉及一种基于机器学习的代码敏感信息及硬编码检测方法及装置。
背景技术:
1、金融监管系统是由金融监管机构使用的软件系统,用于对金融市场和金融机构进行监督管理,维护金融稳定和防范金融风险。这些系统涉及大量的敏感数据,如金融机构的资产负债、风险指标、违规行为、处罚措施等,如果这些数据被修改或删除,可能会造成金融监管的失效。现有的金融监管系统代码的敏感信息及硬编码主要通过人工审查的方式进行检测,具有效率低下的缺点。
2、针对现有技术的缺点,现亟需一种基于机器学习的代码敏感信息及硬编码检测方法。
技术实现思路
1、本发明的目的在于提供一种基于机器学习的代码敏感信息及硬编码检测方法及装置,以改善上述问题。为了实现上述目的,本发明采取的技术方案如下:
2、一方面,本申请提供了一种基于机器学习的代码敏感信息及硬编码检测方法,包括:
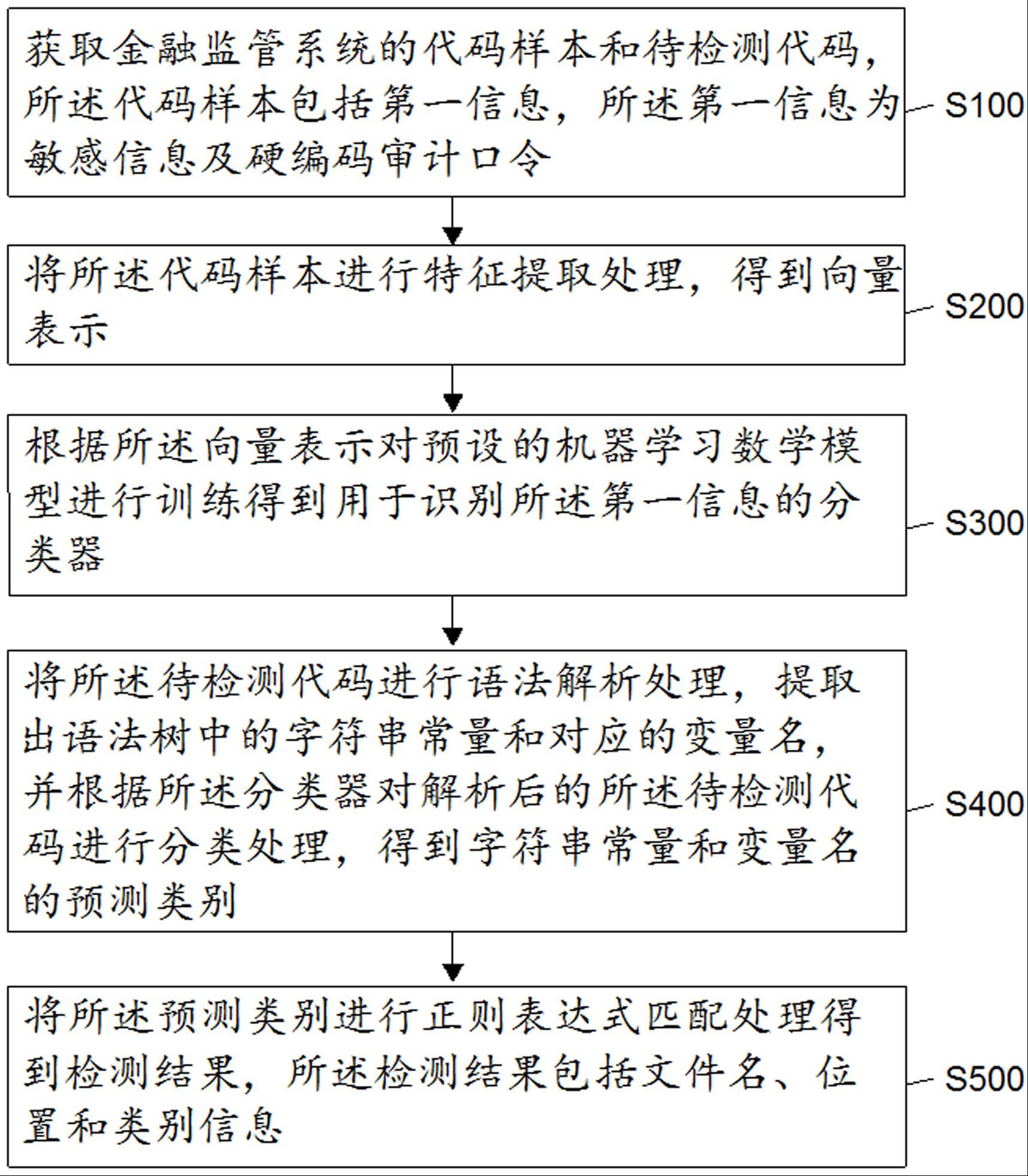
3、获取金融监管系统的代码样本和待检测代码,所述代码样本包括第一信息,所述第一信息为敏感信息及硬编码审计口令;
4、将所述代码样本进行特征提取处理,得到向量表示;
5、根据所述向量表示对预设的机器学习数学模型进行训练得到用于识别所述第一信息的分类器;
6、将所述待检测代码进行语法解析处理,提取出语法树中的字符串常量和对应的变量名,并根据所述分类器对解析后的所述待检测代码进行分类处理,得到字符串常量和变量名的预测类别;
7、将所述预测类别进行正则表达式匹配处理得到检测结果,所述检测结果包括文件名、位置和类别信息。
8、另一方面,本申请还提供了一种基于机器学习的代码敏感信息及硬编码检测装置,包括:
9、获取模块,用于获取金融监管系统的代码样本和待检测代码,所述代码样本包括第一信息,所述第一信息为敏感信息及硬编码审计口令;
10、提取模块,用于将所述代码样本进行特征提取处理,得到向量表示;
11、构建模块,用于根据所述向量表示对预设的机器学习数学模型进行训练得到用于识别所述第一信息的分类器;
12、分类模块,用于将所述待检测代码进行语法解析处理,提取出语法树中的字符串常量和对应的变量名,并根据所述分类器对解析后的所述待检测代码进行分类处理,得到字符串常量和变量名的预测类别;
13、匹配模块,用于将所述预测类别进行正则表达式匹配处理得到检测结果,所述检测结果包括文件名、位置和类别信息。
14、本发明的有益效果为:
15、本发明通过自动化地对待检测代码进行语法解析和特征提取处理,并使用机器学习模型对代码进行分类处理,能够大大提高检测的效率和自动化程度。
16、本发明的其他特征和优点将在随后的说明书阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明实施例了解。
技术特征:
1.一种基于机器学习的代码敏感信息及硬编码检测方法,其特征在于,包括:
2.根据权利要求1所述的基于机器学习的代码敏感信息及硬编码检测方法,其特征在于,将所述代码样本进行特征提取处理,得到向量表示,包括:
3.根据权利要求1所述的基于机器学习的代码敏感信息及硬编码检测方法,其特征在于,根据所述向量表示对预设的机器学习数学模型进行训练得到用于识别所述第一信息的分类器,包括:
4.根据权利要求1所述的基于机器学习的代码敏感信息及硬编码检测方法,其特征在于,将所述待检测代码进行语法解析处理,提取出语法树中的字符串常量和对应的变量名,并根据所述分类器对解析后的所述待检测代码进行分类处理,得到字符串常量和变量名的预测类别,包括:
5.根据权利要求4所述的基于机器学习的代码敏感信息及硬编码检测方法,其特征在于,将所述抽象语法树进行节点遍历处理得到代码元素,包括:
6.一种基于机器学习的代码敏感信息及硬编码检测装置,其特征在于,包括:
7.根据权利要求6所述的基于机器学习的代码敏感信息及硬编码检测装置,其特征在于,所述提取模块包括:
8.根据权利要求6所述的基于机器学习的代码敏感信息及硬编码检测装置,其特征在于,所述构建模块包括:
9.根据权利要求6所述的基于机器学习的代码敏感信息及硬编码检测装置,其特征在于,所述分类模块包括:
10.根据权利要求9所述的基于机器学习的代码敏感信息及硬编码检测装置,其特征在于,所述第七处理单元包括:
技术总结
本发明提供了一种基于机器学习的代码敏感信息及硬编码检测方法及装置,涉及信息安全技术领域,包括获取金融监管系统的代码样本和待检测代码;将代码样本进行特征提取处理,得到向量表示;根据向量表示对预设的机器学习数学模型进行训练得到用于识别第一信息的分类器;将待检测代码进行语法解析处理,提取出语法树中的字符串常量和对应的变量名,并根据分类器对解析后的待检测代码进行分类处理,得到字符串常量和变量名的预测类别;将预测类别进行正则表达式匹配处理得到检测结果。本发明通过自动化地对待检测代码进行语法解析和特征提取处理,并使用机器学习模型对代码进行分类处理,能够大大提高检测的效率和自动化程度。
技术研发人员:付杰,高鹏,靳岩
受保护的技术使用者:北京比瓴科技有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!