一种基于域适应图网络的发酵过程软测量建模方法
本发明涉及发酵过程的产品质量预测领域,特别涉及一种基于域适应图网络的发酵过程软测量建模方法。
背景技术:
1、青霉素发酵过程是一种典型的生化反应过程,主要指青霉素菌体在不同环境下进行生长和合成抗生素的代谢活动。发酵过程具有很强的时变性及非线性。作为一种典型的间歇过程,具有多批次特性。但由于产品生命周期的有限性以及成本投入的经济效益,产品质量的在线测量存在较大困难。数据驱动的软测量方法由于低成本和低延迟的特性,已逐渐替代昂贵费时的离线测量方法,并在过程产品的关键质量预测领域广泛使用。
2、基于深度学习的数据驱动方法在历史数据挖掘方面已表现出较好的能力,例如卷积神经网络和自编码器。大多数的应用假设训练数据和测试数据具有相似的过程特性。但是青霉素发酵的间歇过程通常会改变操作条件或原料配比以生产各种规格的产品。由于过程之间的非线性差异,特定过程建立的模型在不同过程的预测性能会趋于下降。而新的过程重新收集标记数据训练模型的过程又费时费力,导致无法建立可靠的软测量模型。
3、基于迁移学习的域适应软测量方法已逐渐应用于间歇过程,该方法放宽了对过程非线性差异和标签数据量的限制,并旨在迁移相关领域的数据知识辅助当前领域建模。但现有研究通常存在一定的缺陷:它们忽略了变量之间的关系,而是直接将他们封装为抽象特征,一定程度上限制了模型的应用。
4、图神经网络作为深度学习的一个分支,可以学习具有图结构的数据信息,这有助于理解不同节点之间的关系。而作为传统图神经网络的一种变体,图卷积网络(graphconvolution network,gcn)通过对结构数据进行卷积运算,体现了强大的表示能力。然而目前gcn在过程工业中的应用却比较有限,特别在间歇过程,如何更好地适应间歇过程的批次间非线性差异,建立适用于批次切换过程的域适应模型却缺乏研究。
技术实现思路
1、针对现有技术中存在的上述问题,本发明提出了基于域适应的图卷积(deepadaption graph convolutionnetwork,dagcn)方法来进行青霉素发酵过程的软测量建模。dagcn考虑了变量之间的拓扑结构和过程的时序特性,并旨在利用相关过程的数据信息,扩大模型的使用范围。具体建模流程如下:首先基于gcn对相关过程数据进行建模来捕捉数据的拓扑结构信息,其中变量的关系矩阵由模型端到端进行训练。加入采集的时间信息以捕捉过程的时序特性。全连接层学习过程变量和输出变量之间的映射关系,最后基于当前批次的少量数据微调全连接层的参数,扩大了模型的使用范围。在青霉素发酵的间歇过程中表明提出的模型具有较好的性能。
2、本发明解决其技术问题所采用的技术方案是:
3、一种基于域适应图网络的发酵过程软测量建模方法,所述方法包括以下步骤:
4、(1)数据的获取和分析
5、通过青霉素仿真软件获得不同批次数据。
6、(2)输入变量选择
7、选择和输出变量之间相关性较大的输入变量作为模型输入。
8、(3)建模训练
9、构建基于dagcn的过程软测量模型。
10、(4)模型性能评估
11、基于目标域测试数据评估模型性能。
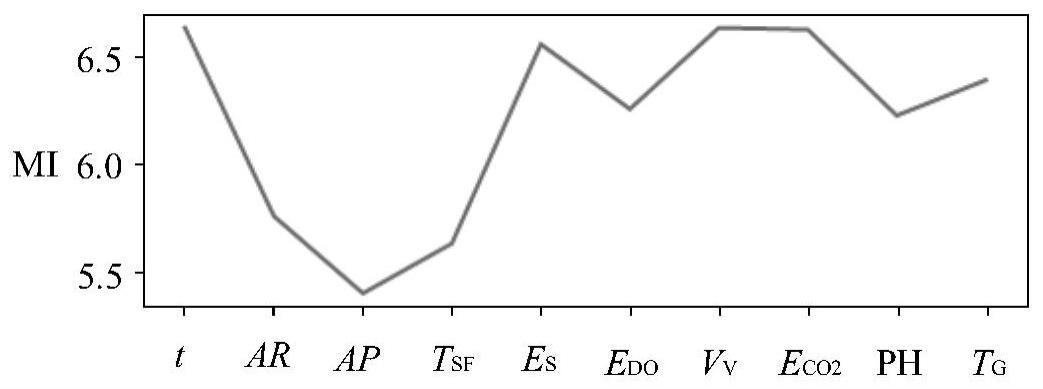
12、进一步,所述步骤(1)的过程为:
13、步骤1.1:通过仿真软件pensim模拟青霉素发酵过程的不同反应条件,具体发酵过程的可变变量为:时间(time,t)、通气速率(aeration rate,ar)、搅拌器功率(agitatorpower,ap)、底物进给温度(substrate feed temperature,tsf)、底物浓度(substrateconcentration,es)、溶解氧浓度(dissolved oxygen concentration,edo)、容器容积(vessel volume,vv)、二氧化碳浓度(co2concentration,eco2)、溶液的酸碱度ph、发酵产生温度(generated temperature,tg)等,输出变量为青霉素浓度(penicillinconcentration,ep)。为了符合真实生产过程,在过程中添加2%的高斯噪声。最终得到三种不同批次特性的青霉素发酵过程,分别记为批次g1、g2、g3。
14、步骤1.2:将不同批次数据划分为源域和目标域数据,其中源域具有足量标记数据,而目标域只拥有少量标记数据。
15、步骤1.3:由于不同输入变量之间具有量纲的差异,因此需要对数据进行标准化处理,具体公式如下所示:
16、
17、其中,x是未经标准化处理的原数据,x'是经标准化处理后的数据,μ、δ分别是数据的均值和标准差。
18、进一步,所述步骤(2)的过程为:
19、基于两个变量的互信息(mutual information,mi)相关性来衡量源域输入变量x和输出变量y之间的相互依赖性,具体计算如下:
20、
21、其中p(x)、p(y)是单个变量x、y的边缘概率密度函数,i(x,y)、p(x,y)分别是两者的mi系数和联合概率密度函数。具体mi值越大表明变量之间的相关性则越高。
22、进一步,所述步骤(3)的过程为:
23、步骤3.1:基于mi排序变量,并选择主要过程变量作为模型的输入。使用源域数据训练gcn模块,具体图卷积运算经过变体可表示为:
24、
25、其中gcn(xθ,a)表示图卷积操作,d-1/2ad-1/2为图卷积核,d=∑jaj为邻接矩阵a的度矩阵,xθ表示表示特征矩阵,其中h表示批次数量,c表示通道数,p表示时间步,v表示变量个数。i表示单位矩阵,conv(.)表示卷积操作,σ(.)是激活函数,w是权重矩阵。
26、为了减少特征位置对于预测变量的影响,将gcn提取到的特征输入到全连接层模块(fully connected layers,fcl)中,学习过程特征和输出变量之间的映射关系。
27、利用根均方误差(root mean square error,rmse)作为模型损失,而为了学习更具泛化性能的邻接矩阵a,加入元素层面熵的约束,用于鼓励结构离散,具体的损失公式如下:
28、
29、l(a)=-alog2(a)-(1-a)log2(1-a)
30、其中yj和分别为源域预测数据的真实值和预测值,其中n为源域训练样本数。l(.)表示元素层面的熵,γ表示正则化系数。
31、步骤3.2:在冻结gcn模块参数信息的基础上,基于目标域少量的标记数据对fcl模块参数进行微调,扩大模型的适用范围。
32、进一步,所述步骤(4)的过程为:
33、在目标域的测试集数据上评估模型的性能,具体采用rmse和平均绝对误差(meanabsolute error,mae)指标。
34、
35、
36、其中yi和分别为目标域预测数据的真实值和预测值,目标域的测试样本量为u,rmse和mae指标越小,表明模型性能越好。
37、本发明的有益效果主要表现在:本发明提出了一种基于域适应图网络的发酵过程软测量建模方法。在捕捉变量关系和过程时序性的同时,进一步基于微调技术扩大了模型的使用范围。
- 还没有人留言评论。精彩留言会获得点赞!