一种基于区块链的多服务器协作高安全度存储方法与流程
本发明属于分布式数据存储领域,具体涉及一种基于区块链的多服务器协作高安全度存储方法。
背景技术:
1、数据存储技术已经发展到了一个相当成熟的阶段,但是在实现高安全度存储方面仍然存在一些挑战和不足。传统的数据存储方法通常需要依靠中心化的服务器进行管理和维护,这种方式容易受到黑客攻击、自然灾害等外部因素的影响,从而导致数据丢失或泄露,缺乏高安全度保障。区块链技术具有去中心化、不可篡改、高安全度等特点,然而区块链技术的性能仍然较低,交易速度较慢,因此无法满足大规模数据存储和传输的需求区块链技术的普及度还比较低,尚未成为主流技术,因此在实际场景中应用起来存在一定的难度。区块链的存储成本也相对较高,在某些场景下并不划算。公开号为cn111563128b的专利文献中尽管提供了一种基于区块链的医疗信息安全存储协作系统,可以在一定程度上借助上链单元将对应信息的地址值整合为地址信息,并将地址信息借助链上存储模块,对其进行上链存储,但是,对于存储的文本信息中语义上进行重要部分的识别与提取仍存在不足。
技术实现思路
1、本发明的目的在于提出一种基于区块链的多服务器协作高安全度存储方法及系统,以解决现有技术中所存在的一个或多个技术问题,至少提供一种有益的选择或创造条件。
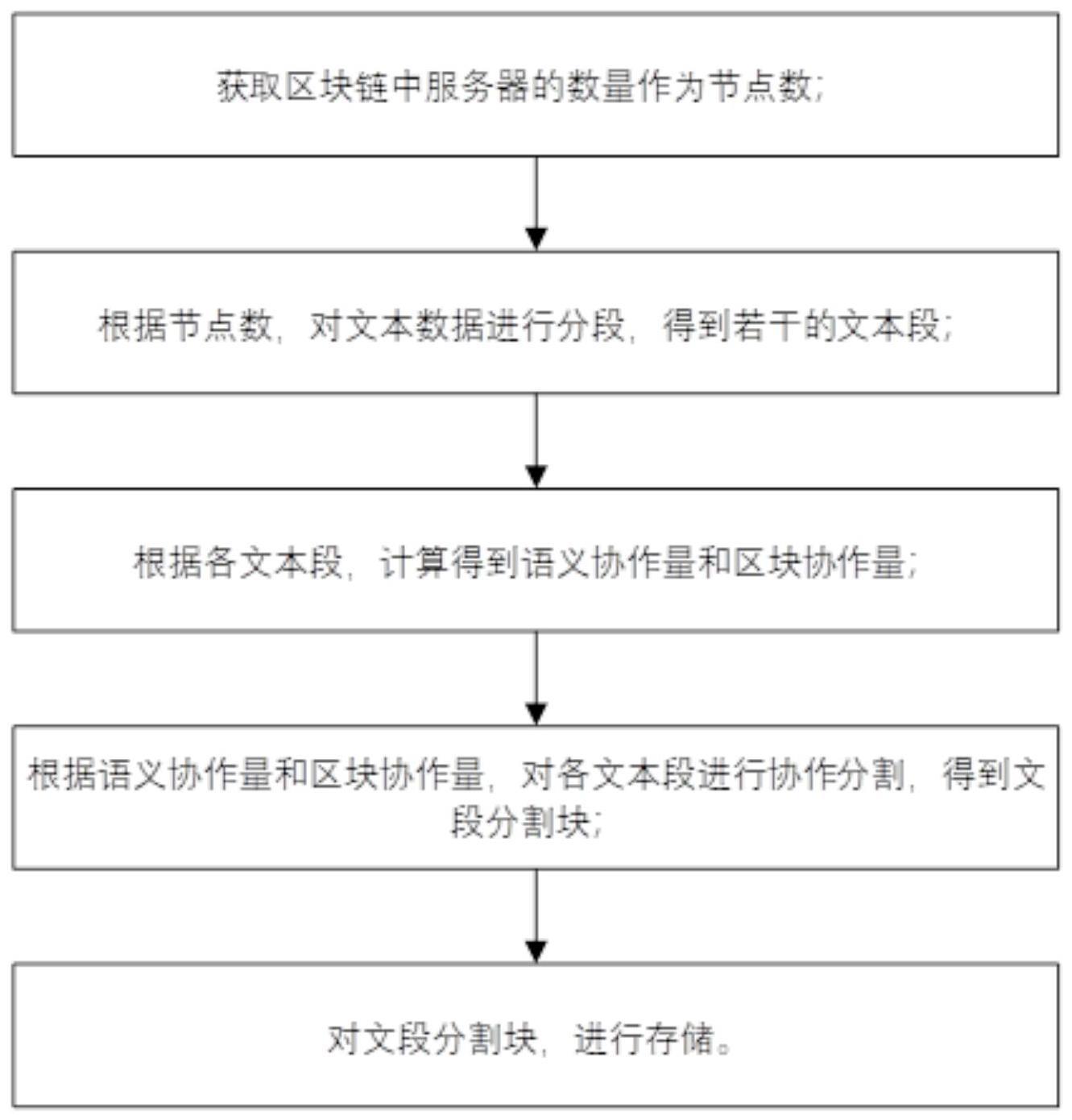
2、本发明提供了一种基于区块链的多服务器协作高安全度存储方法,获取区块链中服务器的数量作为节点数,根据节点数对文本数据进行分段得到若干的文本段,根据各文本段计算得到语义协作量和区块协作量,对各文本段进行协作分割得到文段分割块,进行安全协作存储。
3、为了实现上述目的,根据本发明的一方面,提供一种基于区块链的多服务器协作高安全度存储方法,所述方法包括以下步骤:
4、获取区块链中服务器的数量作为节点数;
5、根据节点数,对文本数据进行分段,得到若干的文本段;
6、根据各文本段,计算得到语义协作量和区块协作量;
7、根据语义协作量和区块协作量,对各文本段进行协作分割,得到文段分割块;
8、对文段分割块,进行存储。
9、进一步地,所述区块链中存在多个不同的服务器,以各服务器为节点,从而获取区块链中服务器的数量作为节点数。
10、进一步地,根据节点数,对文本数据进行分段,得到若干的文本段的方法为:
11、所述文本数据为一个字符串,将所述文本数据分成与节点数相同份的文本段。
12、进一步地,根据各文本段,计算得到区块协作量的方法中:
13、进行张量区块协作处理,得到区块协作量,具体可为:
14、对各文本段以i为序号进行排序,记各文本段的数量为n,节点数等于各文本段的数量同为n,i属于1至n;
15、将每份的文本段分别与各文本段之间进行对照,并计算每份的文本段分别与各文本段之间的语义相似度,得到语义相似度矩阵,所述语义相似度矩阵为对称矩阵:所述语义相似度矩阵为n行n列的矩阵,所述语义相似度矩阵中行序号的排列也是以序号i属于1至n,语义相似度矩阵中第i行的n个维度数值对应序号为i的文本段分别与各文本段之间的语义相似度,而所述语义相似度矩阵中列序号的排列也是以序号i属于1至n,语义相似度矩阵中第i列的n个维度数值也对应了序号为i的文本段分别与各文本段之间的语义相似度,
16、若记所述语义相似度矩阵为smat,则为了防止混淆,记行的序号依旧为i∈[1,n],但是对于列的序号则在i加上标以i`以示区分,i`还是属于[1,n],同时这样的好处是在标识上使得i和i`两变量之间具体数值的变化可以相互独立不影响,
17、计算所述语义相似度矩阵的特征向量为语义协作量,语义协作量有n个维度的数值分别对应n个文本段,其中序号为i的维度的数值对应序号为i的文本段;
18、所述区块协作度为两份文本段之间的语义相似度分别对于所在语义相似度矩阵中分别对于行最大值与列最大值的概率比值,smat中第i行第i`列的数值为smat(i,i`),可优选地,对于所述smat(i,i`),以第i行中各数值的算术平均值为row(i)avg,以第i`列中最小的数值为col(i`)min,计算所述smat(i,i`)的区块协作度bcon(i,i`),区块协作度的计算公式为:
19、
20、其中,函数exp可为以自然常数为底的指数函数;
21、构建区块协作矩阵,所述区块协作矩阵与所述语义相似度矩阵的行列大小及行列序号保持一致,所述区块协作矩阵中行列位置的元素的数值为所述语义相似度矩阵中相同行列位置的元素对应的区块协作度;
22、计算所述区块协作矩阵的特征向量为区块协作量,语义协作量有n个维度的数值分别对应n个文本段,其中序号为i的维度的数值对应序号为i的文本段;
23、其中,smat(i,i`)-row(i)avg反映了当前位置的语义相似度距离该个文本段对比其他各文本段的平均概率分布水平的距离,smat(i,i`)-col(i`)min反映了当前位置的语义相似度距离该个文本段对比其他各文本段的最低概率分布水平即语义最不相似文本段的距离,指数化的函数有利于防止数据的丢失同时提升数据特征的提取精度,|row(i)avg-col(i`)min|反映了该个文本段对比其他各文本段的平均概率分布水平与语义最不相似文本段的距离,对其相乘可以进行数值的线性结合有效地对各文本段中构成文本的主体部分进行识别,且由于节点数等于各文本段的数量这一数量特征一致贯穿于各步骤的数值计算中,反映在语义协作矩阵与区块协作矩阵以及其特征向量的维度数目中,有利于对应后续区块链的节点对数据的分担存储;
24、其中,所述特征向量为单位化的特征向量,单位化的特征向量中各维度的数值处于0~1,可以当作比例使用于文本的抽取。
25、进一步地,根据区块协作量,对各文本段进行协作分割,得到文段分割块,具体为:
26、分别对各文本段进行分词,得到各文本段的分词序列;
27、获取语义协作量中对应各文本段的维度的数值作为该文本段的语义协作比率,
28、获取区块协作量中对应各文本段的维度的数值作为该文本段的区块协作比率;
29、从各分词序列中,抽取出语义协作比率同等比例的分词作为该分词序列的第一文段分割块,并将该分词序列中除所述第一文段分割块外的分词作为余一文段分割块;
30、从各分词序列中,抽取出区块协作比率同等比例的分词作为该分词序列的第二文段分割块,并将该分词序列中除所述第二文段分割块外的分词作为余二文段分割块;
31、其中,从各分词序列中抽取出分词的方法可为计算tf-idf,然后根据tf-idf排序,从中抽取出按tf-idf排序后相应比率的分词;
32、所述文段分割块的种类包括各分词序列的第一文段分割块、余一文段分割块、第二文段分割块和余二文段分割块;
33、这是因为网络的推荐系统需要整个网络社交平台上的海量数据,存储海量的数据往往容易丢失其中某些部分,造成推荐的偏差(参考文献:[1]susan s,kumar a.thebalancing trick:optimized sampling of imbalanced datasets—a brief survey ofthe recent state of the art[j].engineering reports,2020;[2]dulhanty,chris.issues in computer vision data collection:bias,consent,and labeltaxonomy.2020.),而由于如tf-idf等的抽出的算法对一个分词序列进行排序的过程中,会将出现频率高于词频平均概率的常用词或语气词、或者出现频率低于词频平均概率的生僻词或专业术语等安排在排序后序列的首端或末端,但是对于排在中间部分的分词却是缺乏数据特征上的反应的(参考文献:[3]yahav i,shehory o,schwartz d.comments miningwith tf-idf:the inherent bias and its removal[j].ieee transactions onknowledge and data engineering,2018,pp(99):1-1;[4]zhang r h,liu q,fan a x,etal.minimize exposure bias of seq2seq models in joint entity and relationextraction[j].2020.),而这些排在中间部分的分词是构成文本的主体部分,在分布式存储中很容易在同一个节点上进行丢失,例如第一文段分割块和余二文段分割块虽然是从同一个分词序列上进行文本抽取出来的,但是由于语义协作比率和区块协作比率的差异会产生重叠的部分,尽管一个节点大概率存在数据的损失,当第一文段分割块和余二文段分割块、第二文段分割块和余一文段分割块分别存储于不同的区块链服务器的节点中,通过本发明所述方法则可以有效地避免同一个节点中构成文本的主体部分数据的损失,减少了数据特征工程的偏差。
34、进一步地,对文段分割块,进行存储的方法中具体包括一种安全协作存储约束,所述安全协作存储约束为:一个分词序列的第一文段分割块不能与同一个分词序列的余一文段分割块存储于同一个节点中,且一个分词序列的第一文段分割块不能与同一个分词序列的余一文段分割块存储于同一个节点中;并且,当一个节点中存储了同一个分词序列的第一文段分割块与余二文段分割块,则该节点不能存储所述同一个分词序列的第二文段分割块与余一文段分割块,反之,当一个节点中存储了同一个分词序列的第二文段分割块与余一文段分割块,则该节点不能存储所述同一个分词序列的第一文段分割块与余二文段分割块。
35、本发明还提供了一种基于区块链的多服务器协作高安全度存储系统,所述一种基于区块链的多服务器协作高安全度存储系统包括:处理器、存储器及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现所述一种基于区块链的多服务器协作高安全度存储方法中的步骤,所述一种基于区块链的多服务器协作高安全度存储系统可以运行于桌上型计算机、笔记本电脑、掌上电脑及云端数据中心等计算设备中,可运行的系统可包括,但不仅限于,处理器、存储器、服务器集群,所述处理器执行所述计算机程序运行在以下系统的单元中:
36、节点数获取单元,用于获取区块链中服务器的数量作为节点数;
37、文本分段单元,用于根据节点数,对文本数据进行分段,得到若干的文本段;
38、文本计算单元,用于根据各文本段,计算得到语义协作量和区块协作量;
39、文段分割单元,用于根据语义协作量和区块协作量,对各文本段进行协作分割,得到文段分割块;
40、安全协作存储单元,用于对文段分割块,进行存储。
41、本发明的有益效果为:本发明提供了一种基于区块链的多服务器协作高安全度存储方法,获取区块链中服务器的数量作为节点数,根据节点数对文本数据进行分段得到若干的文本段,根据各文本段计算得到语义协作量和区块协作量,对各文本段进行协作分割得到文段分割块,进行安全协作存储,有利于在多个服务器之间进行数据分布式存储和协作,提高了存储效率和安全性。
- 还没有人留言评论。精彩留言会获得点赞!