一种基于二元随机退化过程的可靠性评估方法
本发明专利涉及复杂系统可靠性与安全,具体而言,涉及一种基于二元随机退化过程的可靠性评估方法。
背景技术:
1、在工程应用中,复杂的工程系统因其能满足无数的功能需求而被建造,然而随着时间的推移,无论是串联系统还是并联系统中的多个部件,由于磨损,缺口等原因会导致应力集中,从而产生疲劳,其功能会逐渐退化,从而降低系统的可靠性。对许多系统来说,退化是导致系统发生故障的主要原因之一。
2、近二十年来,已有许多基于简单系统可靠性的研究,这些研究往往依赖于完备数据。然而,随着科学技术的发展,许多复杂工程系统高度可靠且有更复杂的失效机制,在正常情况下,故障不会在短时间内发生,使得获取完备的寿命数据不仅具有技术挑战性,而且成本较高,因此传统的依赖于完备数据的简单系统可靠性评估方法无法满足要求。与此同时,系统的复杂性和失效机制的复杂性使得系统更容易产生大量故障,故障的产生与服役时间、次数、载荷大小及服役环境密切相关。而大多数产品的故障归因于一些潜在的退化机制,例如机械部件的磨损,电子器件的电阻和电池的容量,且具有时变的特征,当退化达到故障阈值时,最终导致产品故障。因此状态检测和退化分析等方法可以为现代复杂系统的可靠性分析提供一种有效的方法。
3、为此,本发明旨在通过对退化数据进行分析,建立退化模型,从而计算复杂系统可靠度,提供一种基于二元随机退化过程的可靠性评估方法。
技术实现思路
1、本发明的目的在于克服上述现有技术的不足,提供一种基于二元随机退化过程的可靠性评估方法,通过本发明的方法,能更好地对复杂系统进行故障预测和健康管理。
2、本发明的目的通过以下方案实现:
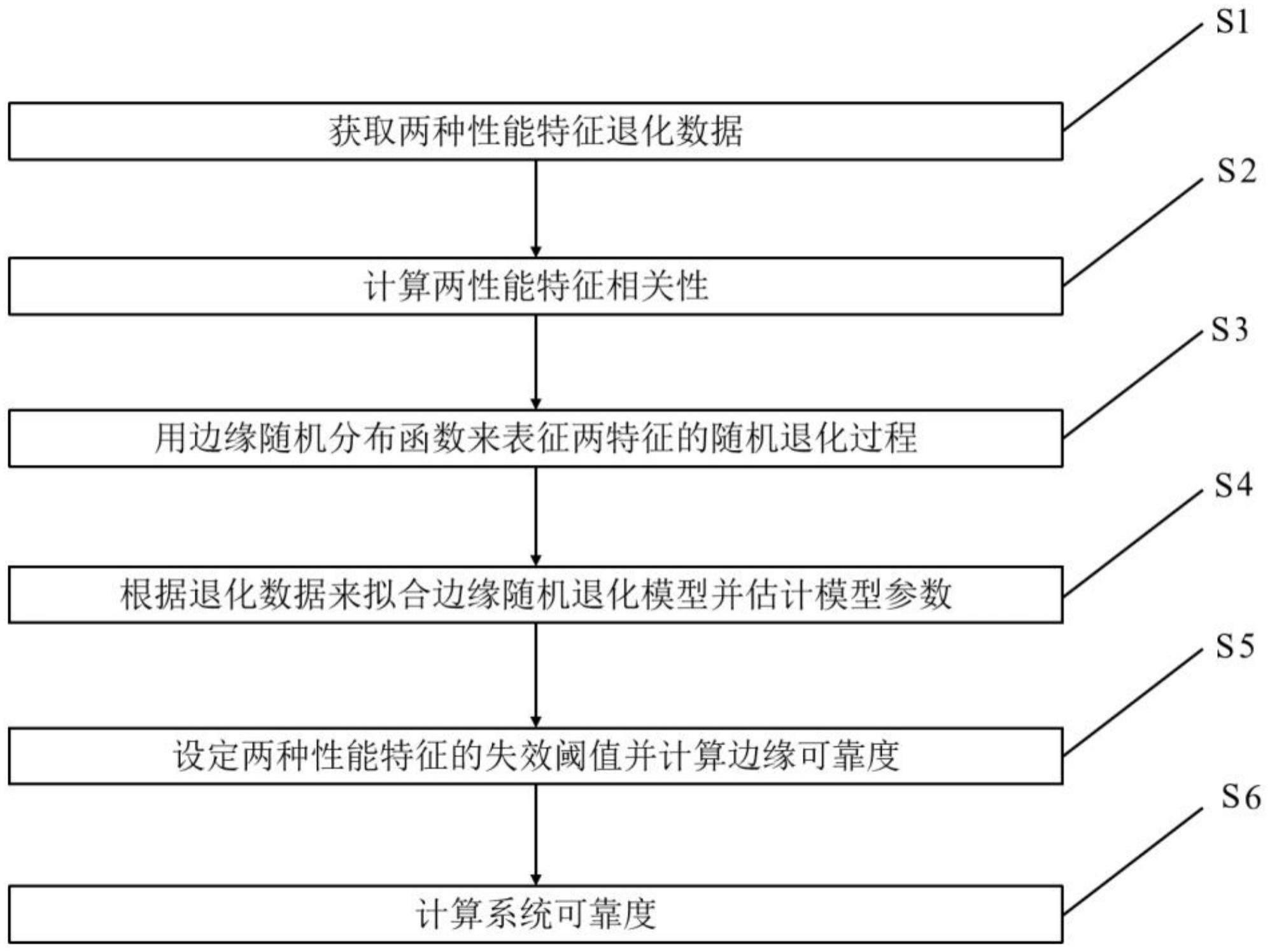
3、一种基于二元随机退化过程的可靠性评估方法,包括以下步骤:
4、s1、通过退化测试(dt)或加速退化测试(adt)获取两种性能特征退化数据;
5、s2、判断两性能特征间的相关性;
6、s3、基于边缘分布函数表征两性能特征的随机退化过程;
7、s4、用退化数据来拟合随机退化模型并估计模型参数;
8、s5、设定两种性能的失效阈值并分别计算单一性能特征可靠度;
9、s6、若两性能特征相互独立,则按一般串联系统计算系统可靠度;若两性能特征存在相关性,则用copula函数来建立两特征之间的相关性关系,并对参数进行估计,最后通过copula函数计算考虑特征间相关关系的系统可靠度。
10、进一步地,步骤s1中通过退化测试(dt)或加速退化测试(adt)获取两种性能特征退化数据为:
11、
12、式中,y1,y2为两种性能特征的退化数据集;y为t时刻,在应力s条件下测得的退化数据,j指示测试单元的次序,n为总的测试单元数;s'j和s'j'为第j个测试单元的压力变量值,如电流电压等;kj为第j个测试单元中的测量总次数,各个测试单元的k值可能有所不同;
13、由退化数据可得退化增量为:
14、δyij(tk)=yij(tk)-yij(tk-1);
15、其中,j为特征的序号,tk,tk-1为在第j个测试单元下相邻的两个测试时刻。
16、进一步地,步骤s2中判断两种性能特征间的相关性的方法为:
17、采用kendall秩相关系数(r)判断两特征间是否存在相关性,kendall相关系数是指设有n个统计对象,每个对象有两个属性的系数;将所有统计对象按属性1取值排列,不失一般性,设此时属性2取值的排列是乱序的;设p为两个属性排列大小关系一致的统计对象的数目;则r的表达式为:
18、
19、其中,r=0时,表示两特征独立;r=1时,表示两特征呈现正相关;r=-1时,表示两特征负相关;所述判断两性能特征相关性的方法中,为消除数据随机性带来的影响,当|r|<0.3时,不考虑两特征间的相关性关系,即认为是独立的串联系统;当|r|>0.3时,判定两性能特征有相关性,即在计算系统可靠度时,考虑两特征之间的相关关系。
20、进一步地,步骤s3中基于边缘分布函数表征两性能特征的边缘随机退化过程为:
21、假设两性能的退化过程为随机退化过程,分别服从于某边缘退化分布函数,即:
22、
23、式中,δyij(tk)为在第i个测试单元,第tk时刻,第j个性能的退化过程,mdp为边缘退化过程,为边缘退化过程(mdp)的参数;所述边缘退化过程用维纳(wiener)分布函数表征,如下式所示:
24、
25、式中,α,β为维纳分布函数中待求的两个未知参数,控制随机退化过程中退化量的均值和方差,h(.)为边际模型中协变量的函数;δλ(tk;γi)=λ(tk;γi)-λ(tk-1;γi)=tk^γi-tk-1^γi,表示参数γi对原始时间进行幂变换后的时间间隔。
26、进一步地,步骤s4中用退化数据来拟合边缘随机退化模型并估计模型参数的方法为:
27、基于维纳(wiener)退化过程,通过贝叶斯方法来估计边缘模型参数,边缘退化过程的后验分布表达式为:
28、
29、式中,π(θimar)为上述维纳(wiener)分布函数中未知参数的先验概率密度函数。
30、进一步地,构建所述后验分布,采用马尔科夫链蒙特卡罗方法(mcmc)来生成参数的后验采样点,mcmc方法采用metropolis算法,根据所述metropolis算法,已知采样点θ(s),生成新采点θ(s+1)的步骤为:
31、(1)由θ*~j(θ|θ(s))对θ*进行采样,其中j为参数为θ(s)的条件分布;
32、(2)通过下式计算接收率r:
33、
34、其中,data表示观测数据点,此处表示退化量;
35、(3)假设参数u服从[0,1]上的均匀分布,对u进行采样,根据下式来判断是否更新采样点:
36、
37、得到每个边缘退化过程参数之后,根据如下所示贝叶斯信息准则(bic)为性能特征退化数据选择最好的边缘退化模型:
38、
39、式中,为似然函数估计值,p和n分别为边缘分布函数中未知参数和mcmc采样点的个数。
40、进一步地,所述设定两种性能特征的失效阈值并计算边缘可靠度的方法为:
41、设两性能特征的失效阈值为yith(i=1,2),即性能特征退化到yith时认定该性能特征失效,所述边缘可靠度计算公式分别为:
42、wiener过程:
43、
44、式中,ri(t)为第i个性能特征的可靠度,tω负为性能首次达到失效阈值的时间,y(t)为退化性能值,φ(·)为标准正态分布函数。
45、进一步地,所述计算系统可靠度的方法为:
46、根据判断两种性能特征间的相关性的方法得到两性能特征之间的相关性,若认定两性能特征间不存在相关性,则系统可靠度为:
47、r(t)=r1(t)·r2(t);
48、若两性能特征间存在相关性,则用copula函数构建其相互依赖关系,对于串联系统,所述copula函数为:
49、
50、式中,ud=fd(xd)为单一性能特征的分布函数,即单一性能特征的可靠性;
51、所述联合概率密度函数为:
52、
53、式中,fi(xi)为单一性能特征的概率密度函数,c(f1(x),f2(x),...,fd(x))为copula密度函数,其定义为:
54、
55、式中,为d次偏导公式;
56、根据边缘退化过程,通过copula函数,构造基于维纳(wiener)过程的二元退化过程,有:
57、(δy1j(tk),δy2j(tk))~c(f1(δy1j(tk)),f2(δy2j(tk));δ)
58、
59、
60、式中,δ表示两特征之间的关联参数;αi,βi分别表示第i个特征维纳过程的漂移参数和扩散参数,应力变量si代表第i个测试单元的应力水平;
61、所述copula函数采用阿基米德家族copula函数:gumbel copula,claytoncopula,frankcopula或joe copula,采用gumbelcopula时,函数表达式为:
62、
63、式中,u1,u2分别为特征1和特征2的可靠度;δ为未知参数,即两特征之间的关联参数;
64、考虑特征之间的相关关系时,根据上述copula函数,所述二元随机退化系统的可靠度公式为:
65、
66、式中,θcop为copula函数中的未知参数;
67、其中,在构造copula函数计算基于特征间相关性的系统可靠度之前,还需对未知参数进行估计求解,所述边缘分布函数的参数估计方法,采用贝叶斯方法来估计copula函数中的未知参数,copula参数的后验分布表达式为:
68、
69、同样,通过马尔科夫链蒙特卡罗方法(mcmc)方法来生成参数的后验采样点。
70、与现有技术相比,本发明具有以下有益效果:
71、1、本发明的方法通过退化测试或加速退化测试获取的退化数据来评估系统可靠性,能较精准地判断系统部件维护与更换时间,为维护与检修提供指导意见,从而节约成本,推动系统可靠性领域的进一步发展;
72、2、本发明的方法克服了现有技术中的缺陷,能更好地对复杂系统进行故障预测和健康管理。
- 还没有人留言评论。精彩留言会获得点赞!