一种麻醉药类型自动识别的方法和系统与流程
一项关于麻醉深度监测的发明, 其改进之处是通过深度学习图像识别技术实现了患者所用麻醉药类型的自动识别,并使识别的准确率达到了可商业化的水平。
背景技术:
1、麻醉是现代外科手术得以实施的前提。对于麻醉医生来说,如何评估一个患者在术中麻醉过程中的麻醉深度,动态调整麻醉药输注速率,使得患者在整个手术过程中始终保持在适宜的麻醉深度,是一项充满挑战性的事情。主要原因是不同患者对于麻醉药存在很大的个体差异。麻醉过浅,会使得患者应激增加、产生炎症反应,影响预后,甚至有可能产生术中知晓(即患者在术中突然恢复意识,且术后形成清楚的记忆),给患者带来痛苦和持续的心理创伤。麻醉过深,更为普遍,且影响更为深远。会使得患者术后苏醒延迟(长时间不能醒来)、谵妄(患者术后神志不清),甚至产生术后认知障碍(痴呆)。
2、麻醉药作用于脑,改变脑的状态,使得大脑皮层的神经元放电模式发生改变。这种大脑皮层的电活动改变,可以通过在头皮上放置电极的方式,以无创的形式被接收,接收到的信号被称为脑电波(eeg)。随着麻醉药浓度的增加和麻醉深度的加深,头皮上接收到的脑电波会产生数种有特征性的表现,每一种波形特征对应于一种麻醉状态。所以可以通过患者的脑电波去判断患者的麻醉深度。但直接判读这些波形,对于麻醉医生而言较为困难。麻醉深度监测仪的主要功能就是将这些难懂的脑电波波形利用算法转换成麻醉医生易于理解的数字(数字范围0-100),这个数字被称为“麻醉深度指数”。不同数值范围对应于不同的麻醉深度。不同公司具体的数值范围略有差异。一般而言,80-100对应于清醒,60-80对应于中、浅镇静的麻醉深度水平,40-60对应于适合手术的麻醉深度水平,小于40指示麻醉过深。
3、麻醉医生经常抱怨麻醉深度监测仪不准。原因之一是现有的麻醉深度监测仪在算法设计时,没有针对不同麻醉药开发相对应的麻醉深度算法。而脑科学方面的基础研究已经发现不同麻醉药由于其分子机制不同,会产生不同的脑电特征,见pantrik prudon2015年clinical electroencephalography for anesthesiologists: part i: backgroundand basic signatures一文中的图14 。而现有的所有麻醉深度监测产品,均没有考虑到不同麻醉药产生的脑电特征差异。
4、目前,麻醉药主要有两类:一种是通过麻醉呼吸机输送的吸入麻醉药,主要是氟烷类物质,另一种是通过静脉注射的麻醉药,主要是丙泊酚。理想的麻醉深度监测仪,应针对不同的麻醉药使用不同的麻醉深度算法模型。本发明通过深度学习的手段,在现有麻醉深度监测仪采集的脑电数据的基础上,自动分析患者在麻醉药作用下的脑电波特征,实现了对麻醉类型或者叫麻醉药种类(氟烷吸入麻醉/丙泊酚静脉麻醉)的自动判别。其有两个好处:一、它是构建具有“麻醉药针对性”的麻醉深度算法的基础。二、可以引导麻醉医生关注不同麻醉药的脑电波特征,对其开展麻醉领域的基础研究可能有所裨益。
5、麻醉学家在此领域的研究,侧重点在于发现科学规律,即:研究不同麻醉药会产生何种脑电信号特征。如何利用患者的脑电信号去自动判别患者使用了何种麻醉药,是一个“反问题”,是一个较少被研究的领域。经初步检索,未发现学术界有这方面的文献发表。
6、经检索,专利pct/cn2017/120348中一部分内容涉及麻醉药类型的识别,其基本思路是通过计算脑电信号在频域的一些特征,利用传统统计学习的方式,实现麻醉药类型的预测。但其有以下不足:一、针对此类问题,统计学习一般不能使得分类准确率达到实际可用的水平。类比于经典的“猫狗识别”问题,专利pct/cn2017/120348的基本思想是通过人为定义、计算一些特征,如“耳宽”、“腿长”等,去识别猫狗。脑电信号除受麻醉药类型影响外,还受麻醉药浓度、患者个体差异、手术刺激大小等多种因素的影响,最终使得脑电信号是“千人千面”,很难去总结出一个明确的分类规则。图像识别、语音识别和机器翻译等领域的无数例子已证明:对于这类难以用明确规则去描述的分类问题,统计学习一般只有理论意义,很难达到实际可用的水平。目前,所有已实现商业化的图像识别、语音识别、机器翻译和大语言模型等商业应用,均采用基于大样本量的深度学习技术。二、对于机器学习,无论是传统的统计学习还是深度学习,都需要展示其模型的预测表现。专利pct/cn2017/120348中没有提供相关内容,这可能是符合专利申请要求的,但没有满足机器学习最基本的要求、没有遵循机器学习中百分之一百的普遍做法:即通过混淆矩阵、roc曲线等展示模型预测的实际表现(准确率等)。 本发明实现了基于深度学习框架的麻醉药类型识别,并展示了分类模型准确率已达到实际可用水平的证据。
7、目前,没有发现利用深度学习框架解决麻醉药类型自动识别的先例。其主要难点在于:一、深度学习需要大样本的训练数据,而医学数据由于受伦理、患者隐私等限制,较难积累满足深度学习要求的大量患者麻醉监测数据;二、深度学习要求输入的是图像,所以在医学领域,深度学习主要用于医学影像(x光、mri、超声、ct)等的自动识别,对于脑电eeg等非图像的时间序列信号,深度学习应用的相对较少;三、相比于日常的图像数据,医学数据的标注更为困难。 在麻醉药类型识别这个具体领域,各种术中监测设备和信息系统中,并没有专门的字段记录麻醉药类型。人工翻看大量患者的各种医疗历史文档、分析监测设备的历史数据,然后手工标注出每个患者的麻醉药类型,是一项繁琐、枯燥、且工作量巨大、极其耗时的工作。本发明通过计算机程序自动分析患者麻醉过程中麻醉呼吸机和输注泵产生的文件记录,可以判断出患者使用了何种麻醉药,实现了患者麻醉药类型的“自动标注”。
技术实现思路
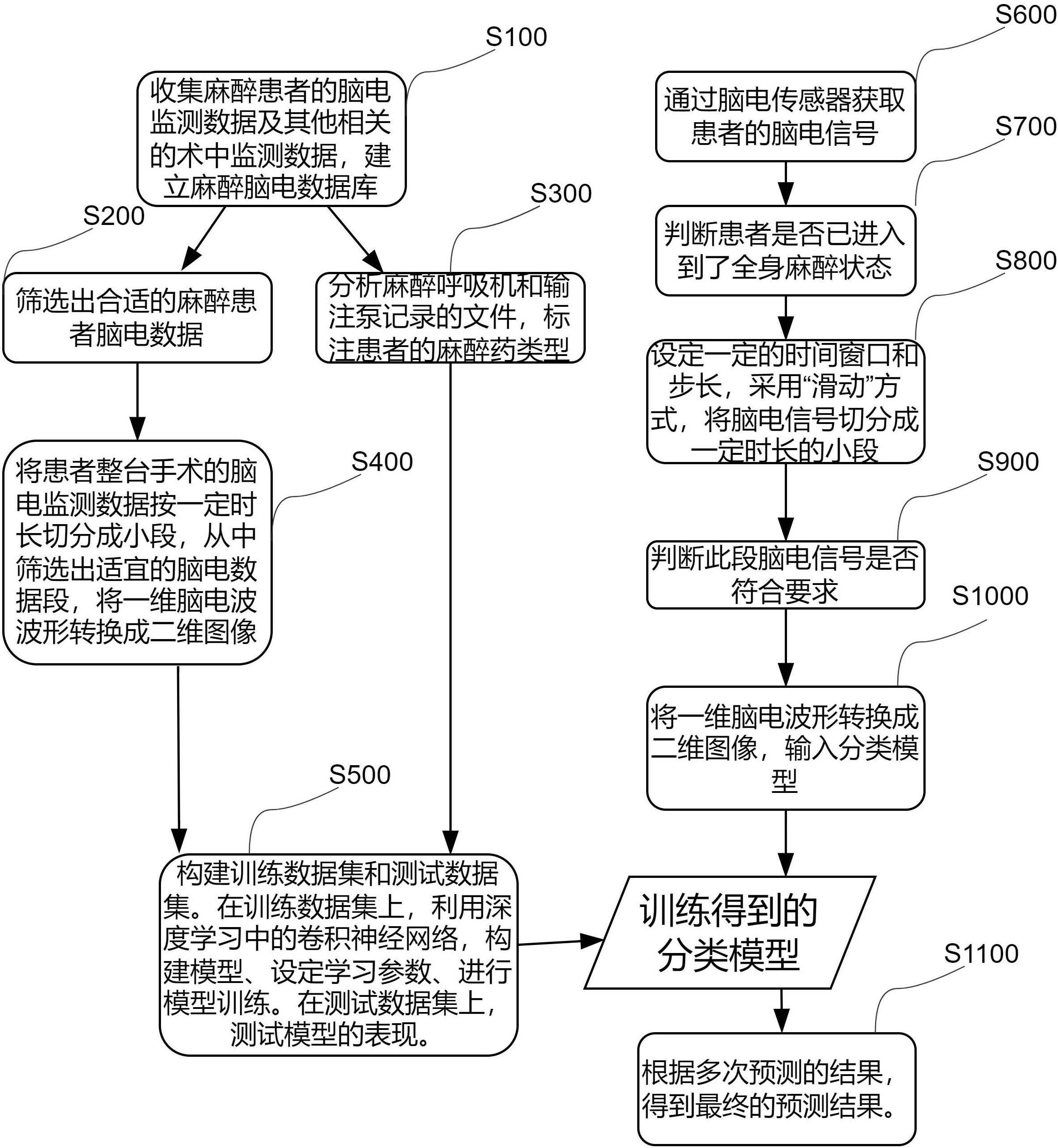
1、为了实现基于深度学习框架的麻醉药类型自动识别,本发明所采用的技术方案如下:由基于大量患者麻醉监测历史数据的麻醉药类型分类模型训练方法和手术室场景下某个特定患者的麻醉药类型实时自动识别方法两部分组成。如图1所示。
2、基于大量患者麻醉监测历史数据的麻醉药类型分类模型训练方法,包括以下步骤:
3、步骤s100:收集麻醉患者的脑电监测数据及其他相关的术中监测数据,建立麻醉脑电数据库。除了脑电数据外,还需要记录:麻醉方式(全身麻醉、镇静、局部麻醉等)、患者脑疾病和精神疾病状态、患者饮酒吸烟及服用精神类药品的情况、患者asa体质状况分级、手术类型等。特别的,需要记录麻醉呼吸机数据和输注泵数据等。
4、步骤s200:筛选出合适的麻醉患者脑电数据。排除6岁以下儿童,排除脑疾病和精神疾病患者、排除重度饮酒吸烟及服用精神类药品患者,排除asa分级>3的患者,仅选择全身麻醉患者。
5、步骤s300:分析麻醉呼吸机和输注泵记录的文件,标注患者的麻醉药类型。通过分析麻醉呼吸机、输注泵数据文件的有无及值是否全为0,确定患者是氟烷吸入麻醉/静脉丙泊酚麻醉两种中的哪一种,自动完成机器学习中的数据标注工作。具体判断逻辑如图2所示。
6、步骤s400:将患者整台手术的脑电监测数据按一定时长切分成小段,从中筛选出适宜的脑电数据片段,并将一维脑电波波形转换成二维图像。经大量试验,时长选择为10-30秒时,能取得较好效果。所图3所示,脑电数据片段筛选的具体方法如下:给脑电信号设定一个阈值; 给对应时刻的麻醉深度值设定一个阈值;给脑电信号质量设定一个阈值;将脑电爆发抑制比的阈值设定为0;以上4个阈值,有一个超过,则弃用此段脑电信号。选择信号分析领域中任意一种时频分析方法将一维脑电波波形转换成二维图像。经测试,任意一种时频分析方法均能满足后续深度学习的要求。
7、步骤s500:构建训练数据集和测试数据集。在训练数据集上,选择机器学习领域任意一种已有的图像识别模型,利用迁移学习的方式,进行模型训练。迁移学习,利用的是已有的深度学习卷积模型,其模型结构已公开,在此不再入赘述。根据麻醉药类型识别这个特定场景,需要将已有的深度学习卷积模型进行调整,主要包括 :将最后一层卷积层和分类输出层替换为麻醉药类型。同时设定学习速率(learning rate)、批大小(batch size),训练轮数(epoch)等训练参数,进行模型训练。在测试数据集上,测试模型的表现,以混淆矩阵等方式展示模型的表现。 经测试,机器学习领域任意一种已有的图像识别模型进行迁移学习的,其分类准确率均能满足要求。
8、手术室场景下某个特定患者的麻醉药类型实时自动识别方法,包括包括以下步骤::
9、步骤s600:通过脑电传感器获取患者的脑电信号。要求采样率不得低于100hz。
10、步骤s700:分析患者是否已从麻醉诱导转入麻醉维持阶段。通过分析距当前时刻较近和较远一段时间的麻醉深度值的平均值,判断患者是否进入了全身麻醉状态。若当前时刻为t,分别计算[t-t, t]和[t-2t,t-t]两个时间段的麻醉深度值的众数平均数a1和a2,若a1小于清醒状态下的麻醉深度值a3且a2-a1大于某个设定的阈值a4, 则判断患者已从麻醉诱导转入麻醉维持阶段。
11、步骤s800:在确定患者已进麻醉维持阶段、达到全身麻醉的麻醉深度水平后,设定一定的时间窗口和步长,采用“滑动”方式,将脑电信号切分成一定时长的小段。
12、步骤s900:判断当前段的脑电信号是否符合图3所示的要求。
13、步骤s1000:将一维脑电信号转换成二维时频图像,并将其输入已训练好的卷积神经网络分类模型,得到麻醉药类型的预测值和相应的概率。
14、步骤s1100:进行多次预测,得到最终预测结果,以提高最终预测结果的可靠性。给预测次数设定一个阈值k, 分类模型会输出两个长度为k的数组;麻醉类型数组[d1,d2...,dk]和相应概率的数组[p1,p2,...,pk]计算麻醉类型数组[d1,d2...,dk]的众数m1;提取此众数对应的麻醉药类型,从概率数组中提取相对应的概率[px1,px2,...,pxn],计算其算术平均数m2;给模型输出的麻醉类型的众数设定一个阈值k0, 给预测概率的算术平均数设定一个阈值pt。当同时满足上述两个阈值时,则输出最终预测结果。
15、上述方法,可以形成对应的软件模块,组成麻醉药类型自动识别系统,所图4所示。
- 还没有人留言评论。精彩留言会获得点赞!