一种海关报关单据信息风险规则生成方法及系统
本发明涉及数据挖掘,具体为一种海关报关单据信息风险规则生成方法及系统。
背景技术:
1、自我国加入世界贸易组织,海关进口贸易出现大幅增长,根据中国海关的统计,我国2022年进口货物贸易额18.1万亿元,进口规模再次创造历史新高,为海关安全准入货物入境查验带来非常大的挑战。在进口规模体量激增、贸易主体数量增长以及通关时间紧张的影响下,目前海关在货物入境查验上面临人工资源紧张、风险查验效率低、查验压力大的问题,海关需要进一步提高查验效率并推动智能化建设。
2、目前关于提高海关风险查验效率的研究主要是从流程简化与管理等角度出发的,无法真正缓解海关大量的入境查验需求。针对该问题,海关方面采用基于专家经验的风险规则辅助查验,解决安全准入场景下货物入境的查验需求,一线业务人员利用风险规则作为查验依据对货物入境的风险性进行判断,提高通关查验效率。此外,基于风险规则的查验方法具有重要的意义,为口岸负责查验的业务人员提供风险研判的基础规则支撑。海关方面提出拟采用关联规则等机器学习方法,基于报关单查验数据进行风险规则的自动挖掘工作。
3、风险规则自动挖掘算法可以从报关单查验黑样本中发现潜在风险因素,自动发现挖掘产生共性较强的风险规则,解决专家规则数量少、可扩展性低的问题,降低对专家的依赖程度。目前的海关风险规则挖掘算法难以满足较大规模的报关单查验数据要求,在时间效率、空间效率上仍需改进。
技术实现思路
1、本发明的目的在于提供一种海关报关单据信息风险规则生成方法及系统,以解决上述背景技术中提出的问题。
2、为了解决上述技术问题,本发明提供如下技术方案:
3、一种海关报关单据信息风险规则生成方法:该方法包括以下步骤:
4、s1、根据时间周期,设置定期生成的间隔周期,输出所述间隔周期;
5、s2、根据动态权值can-tree海关风险规则增量挖掘算法(ddwct)和所述间隔周期,生成风险规则;
6、s3、对所述风险规则进行审核,审核所述风险规则的有效性,输出有效风险规则;
7、s4、对所述有效风险规则进行维护与管理。
8、在步骤s2中,动态权值can-tree海关风险规则增量挖掘算法(ddwct)包括:
9、s2-1、根据海关大数据资源池和查验系统获取海关报关单数据,处理所述海关报关单数据,生成can-tree;
10、根据海关大数据资源池和查验系统获取货物入境相关报关单数据及查验放行结果,根据所述报关单信息、所述报关单查验结果,构建原始报关单查验黑样本数据;通过海关大数据资源池和查验系统获取新的货物入境相关报关单数据及查验放行结果,构建增量报关单查验黑样本数据。
11、s2-2、根据所述can-tree中的数据项,计算所述数据项的计算量预估值;
12、s2-3、计算所述can-tree的节点性能,输出负载均衡策略;
13、s2-4、根据所述计算量预估值和所述负载均衡策略,生成并行挖掘方案;
14、s2-5、根据所述并行挖掘方案,生成所述风险规则。
15、在步骤s2-1中,处理所述海关数据包括:
16、s3-1、对所述海关报关单数据进行去重操作,得到去重海关报关单数据;
17、s3-2、获得所述去重海关报关单数据的数值型数据属性,通过聚类算法进行划分,获得特征区间;
18、海关报关单数据样本中存在大量的数值型数据属性,如数量、重量、离岸价、到岸价、关税等。
19、s3-3、根据所述特征区间,构建所述数值型数据属性的模糊值,所述模糊值为所述风险规则的部分表示属性;
20、s3-4、将单一的所述数值型数据属性进行组合,生成扩展属性;
21、s3-5、将所述部分表示属性和所述扩展属性作为所述海关报关单数据的数据属性;
22、s3-6、对所述数据属性进行权值分配,建立对应所述数据属性的权值网络;
23、s3-7、根据所述权值网络,排序所述数据属性,获得所述数据属性的重要性排序;
24、s3-8、根据所述重要性排序,计算动态支持度,生成数据项动态支持度;
25、s3-9、将所述数据项动态支持度进行逆序排序,得到数据项动态风险权值排序顺序。
26、在步骤s2-2中,计算所述数据项的计算量预估值包括:
27、s4-1、根据所述数据项动态风险权值排序顺序,生成全量频繁1-项集f1-list;
28、s4-2、获取数据项i在所述路径f1-list中的顺序ldi,获取所述全量频繁1-项集f1-list的总长度ld,计算深度计算量预估值cdi:
29、s4-3、获取所述数据项i在所述can-tree中所处的分支数ebi,获取所述数据项i在所述can-tree中所处的总分支数eb,获得计算量预估值ci:λ为所述分支数ebi的权重因子,μ为所述总分支数eb的权重因子。
30、在步骤s2-3中,输出负载均衡策略包括:
31、s5-1、获取集群的节点数量n,服务器处理器的核心数a1,所述服务器处理器的线程数a2,所述服务器处理器的主频a3,内存规则b,硬盘规格c,带宽大小d,计算服务器pi的静态性能:
32、其中a1为所述核心数a1的权重因子,a2为所述线程数a2的权重因子,a3为所述主频a3的权重因子,且a1+a2+a3=1,α为所述服务器处理器的权重因子,β为所述内存规则b的权重因子,ω为所述硬盘规格c的权重因子、ψ为所述带宽大小d的权重因子;
33、s5-2、获取节点的处理器占用率ua,内存使用率ub,磁盘使用率uc,带宽使用率ud,计算节点动态负载性能:di=αauai+βbubi+ωcuci+ψdudi,αa为所述处理器占用率ua的权重系数,βb为所述内存使用率ub的权重系数,ωc为所述磁盘使用率uc的权重系数,ψd为所述带宽使用率ud的权重系数;
34、s5-3、获取所述节点的响应时间ti,连接数qi,集群节点总连接数q,节点平均响应时间计算节点ni的负载权重:
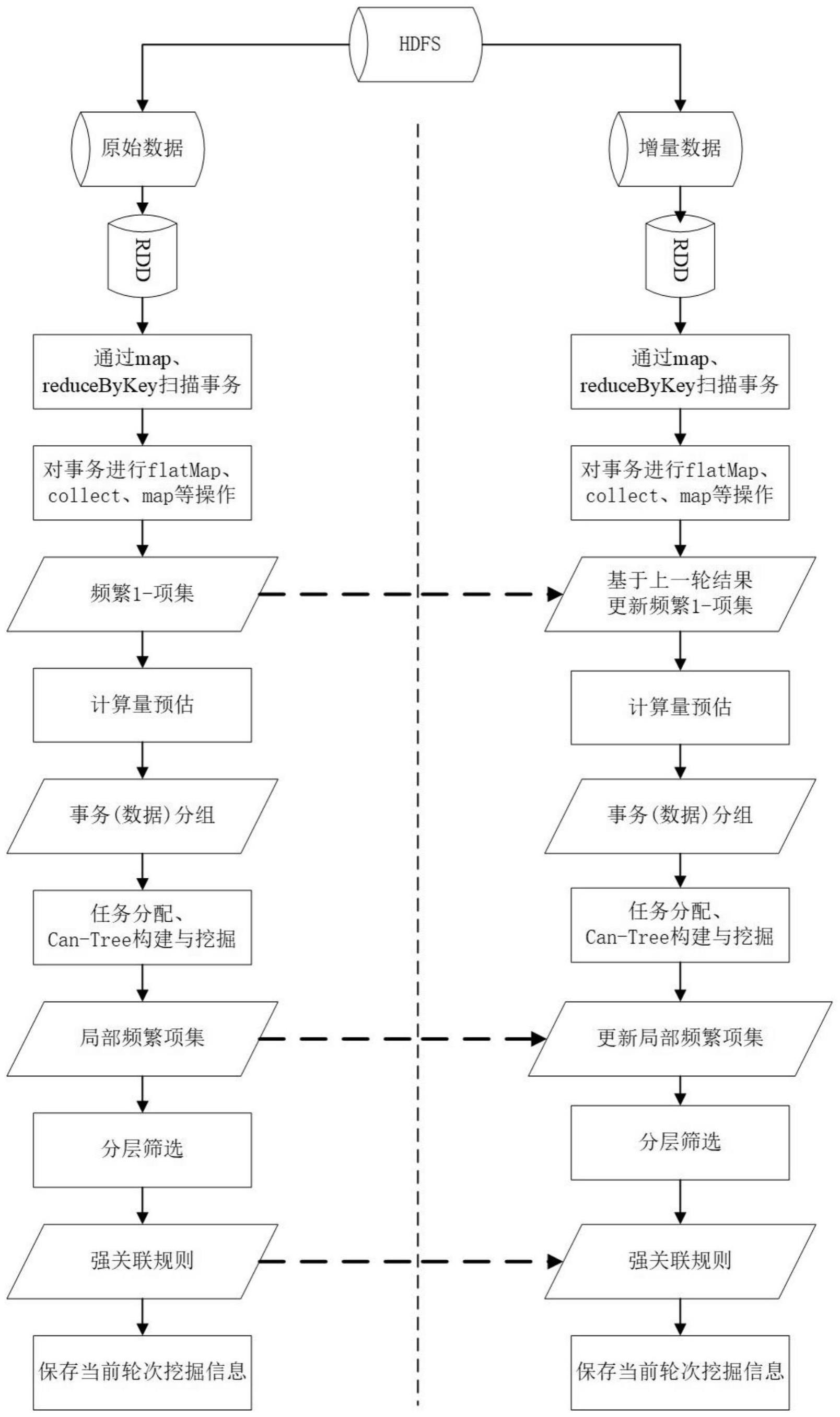
35、s5-4、根据所述负载权重,划分服务器区间,生成服务器节点区间序列l={l1,l2,……,lk};
36、s5-5、根据所述计算量预估值和所述服务器节点区间序列,生成所述负载均衡策略。
37、在步骤s2-4中,生成并行挖掘方案包括:
38、s6-1、在每个服务器节点上分别构建子can-tree,每个子can-tree在各自节点上记为原始can-tree;
39、s6-2、增量数据更新时,分配到各个子节点中,基于上一轮的所述原始can-tree,构建新的增量can-tree。
40、在步骤s2-5中,生成所述风险规则包括:
41、读取原始事务数据集:spark通过textfile从分布式文件存储系统hdfs中读取原始事务数据集,并将数据转换成rdd;
42、构建全量频繁1-项集:通过flatmap、map进行rdd数据的扁平化和映射,生成键值对<key,frequency>,其中key表示事务,frequency表示该事务在原始事务集中出现的次数,经由reducebykey、collect处理得到全量的频繁1-项集(f1-list)。为了维持can-tree算法“一次构建多次挖掘”的特点,基于原始事务数据库得到的f1-list不必经过最小支持度的筛选,实现全量can-tree的构建,方便后续增量数据的插入;
43、结合数据项深度与广度的计算量负载均衡策略:根据数据项在f1-list中的位置预估计算量,记为cal<item,size>,根据设定的分组,按照size从大到小的方式将数据项并入最小的分组;
44、基于服务器动态负载能力的负载均衡策略实现计算任务分配;
45、服务器集群执行dwct算法:通过负载均衡策略将原始事务数据均匀分配给节点,进行can-tree的构建与挖掘,最后得到局部频繁项集;
46、构建全局频繁项集:根据各个节点生成的频繁项集local<frequency_list,frequency>,由spark执行map算子映射所有节点的频繁项集,按照frequency_list长度分层,汇总构建k个层次的频繁项集global<k,frequency_list>;
47、分层生成强关联规则:根据多层频繁项集,通过最小置信度、提升度阈值筛选,得出对应的强关联规则;
48、存储相关挖掘信息:节点在完成频繁项集的生成之后,存储各节点计算得到的f-list用于下一次增量挖掘的参考;
49、读取增量数据:spark读入增量数据到rdd,依次通过flatmap、map、reducebykey、collect操作,并且根据上一轮原始事务数据库的f1_list结果更新并生成当前的频繁1-项集new_f1_list;
50、实现增量数据的负载均衡:按照负载均衡方法重新计算并分配给相应的节点;
51、纵向更新频繁模式树:随着增量数据的增加,数据项的动态支持度会发生一定的变化,原先非频繁的项可能变成频繁项,频繁项可能会变成非频繁的项,因此,需要调整节点在can-tree中的位置。对比new_f1_list和f1-list中数据项的变化,调整can-tree结构;
52、挖掘增量数据:各节点在更新后的can-tree上进行规则的挖掘工作,依据前一轮各自保存的原始频繁项集,更新得到新的局部增量频繁项集,聚合所有节点生成增量挖掘结果并且保存到数据库中;
53、重复迭代原始事务-增量事务:各节点增量挖掘任务完成后,同时存储节点当前的new_f1_list、局部频繁项集等信息,以用于后续增量挖掘使用。
54、下一轮的增量挖掘是在当前挖掘的基础上进行,即当前所有节点的“增量挖掘数据和结果”记作下一轮增量挖掘的“原始事务数据和结果”,逐层迭代,生成新鲜度较高的强关联风险规则。
55、一种海关报关单据信息风险规则生成系统:该系统包括后台管理模块、风险规则生成模块、风险规则审核模块和风险规则管理模块:
56、所述后台管理模块用于根据所述时间周期,设置定期生成的所述间隔周期,输出所述间隔周期,所述后台管理模块的输出端与所述风险规则生成模块的输入端相连接;
57、所述风险规则生成模块用于根据所述动态权值can-tree海关风险规则增量挖掘算法(ddwct)和所述间隔周期,生成并输出所述风险规则,所述风险规则生成模块的输出端与所述风险规则审核模块的输入端相连接;
58、所述风险规则审核模块用于接收所述风险规则,对所述风险规则进行审核,审核所述风险规则的有效性,输出所述有效风险规则,所述风险规则审核模块的输出端与所述风险规则管理模块的输入端相连接;
59、所述风险规则管理模块用于接收所述有效风险规则,对所述有效风险规则进行管理与维护。
60、所述风险规则生成模块包括模型阈值配置单元、定期风险规则生成单元和手动风险规则生成单元;
61、所述模型阈值配置单元用于设置支持度阈值、置信度阈值和提升度阈值,输出聚合阈值,所述模型阈值配置单元的输出端与所述定期风险规则生成单元的输入端和所述手动风险规则生成单元的输入端相连接;
62、所述定期风险规则生成单元用于接收所述间隔周期和所述聚合阈值,生成并输出定期风险规则,所述定期风险规则模块的输出端与所述风险规则审核模块的输入端相连接;
63、所述手动风险规则生成单元用于接收所述聚合阈值,通过用户手动设置,输出手动风险规则,所述手动风险规则生成单元的输出端与所述风险规则审核模块的输入端相连接。
64、与现有技术相比,本发明所达到的有益效果是:
65、1.在数据量较大时,满足大规模数据下风险规则生成的时间和空间需求,提高数据挖掘效率;
66、2.通过分析can-tree结构的广度和深度影响,实现数据分组,更为全面的实现计算量预估;
67、3.通过节点动态负载的方式,实现任务分组,提高多节点的任务处理效率。
- 还没有人留言评论。精彩留言会获得点赞!