面向深度学习推理任务编译器的算子融合方法和系统
本发明涉及深度学习,特别是涉及一种面向深度学习推理任务编译器的算子融合方法和系统。
背景技术:
1、深度学习被广泛的应用于图像分类与识别,自然语言理解等人工智能技术领域。而随着半导体技术和编译器软件的进步,数据中心和超级计算机系统的工作负载也越来越多地来自以深度学习神经网络为代表的人工智能技术。
2、为了进一步提高基于深度学习神经网络模型的计算任务在设备上的运行速度,很多面向深度学习的编译器将神经网络模型中单个算子的优化作为主要工作。它们往往通过自动调整调度参数和调用硬件厂商提供的算子库来完成编译优化。然而,对于很多人工智能(ai)计算任务,尤其是对于深度学习的推理任务来说,神经网络模型中顺序运行的单个算子通常很难完全利用整个加速器的并行计算单元和其他资源。
3、而当前深度学习中卷积神经网络的设计也越来越倾向于使用多分支卷积来代替以往的单分支,从而使整个网络模型变得更宽、更深,单个算子的操作数也随之逐渐降低。最近的研究表明,在早期的图像分类识别网络vgg中,卷积算子平均包含2230mflops。而在2018年之后出现的图像分类网络nasnet中,卷积运算的平均浮点操作数就降到了82mflops。这种趋势伴随着硬件技术的进一步发展,将使算力浪费问题变得更加严重。
4、现有的深度学习编译器使用算子融合技术来提高单个算子的计算规模,减少算子间数据搬移次数,减少核函数加载的额外开销,从而提高整体计算的效率。此种算子融合技术可以在神经网络模型的执行通路上顺序地融合特定的算子组合。但是这种纵向的融合方案依赖于厂商停供的算子库,可融合的算子组合有限,而且只能沿着计算通路进行融合,无法彻底解决系统运行时计算资源利用率低下的问题。
5、利用硬件厂商提供的多流或资源隔离机制,有些优化方法可以将并行的算子分配到隔离的硬件流中并发执行从而提高系统计算资源的利用率,改善了系统的整体性能。但是这种方案受限于硬件资源的隔离机制,资源的分配调整难以动态实现,给核函数的优化带来困难。而且这种方法引入的调度开销无法被忽略,影响了总体的执行效率。
6、基于设备厂商提供的加速库,还有些方法可以执行计算图级别的并行算子融合优化。这种优化方法可以将相同的可并行化的小算子通过加速库中相应的批处理函数转化成相应的大算子,从而有效的提高加速器的利用率。然而这种方案受限于厂商提供的加速库,支持的算子有限,不同种类不同大小的并行算子也无法进行融合。并且这种方法还需要在融合前后对算子的输入和输出进行连接和拆分处理,这也会增加不小的计算开销。
7、最近的一些工作成果也提出了一些不依靠厂商加速库的并行算子融合机制,比如rammer和hfuse。这些方法可以把多个顺序或并行的element-wise类算子融合到一个大算子之中,从而更好地利用硬件计算单元,降低了模型端到端执行时间。但是现有的这些并行化算子融合机制无法处理常见复杂算子间的融合,比如卷积和矩阵乘。而且它们也没能提供融合后算子的调优方案,限制了进一步优化的空间。
8、针对深度学习编译器中单算子优化无法充分利用加速器算力资源的问题,以及上述现有算子融合解决方案存在的缺点,本发明提出了一种面向深度学习推理任务编译器的算子融合方法。
技术实现思路
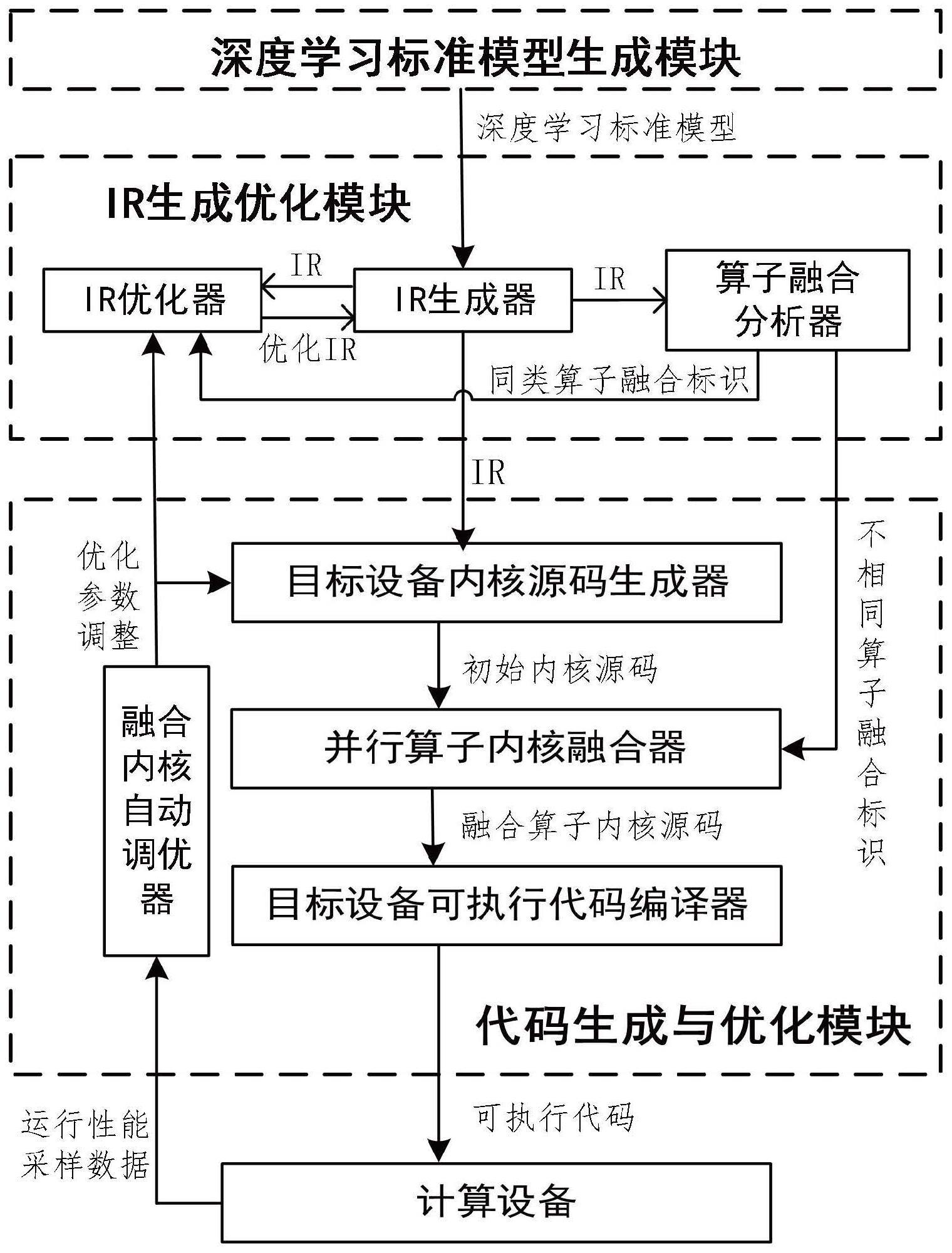
1、针对上述问题,本发明提出一种面向深度学习推理任务编译器的算子融合方法,包括:将深度学习推理任务模型的标准模型,转化为初始图级ir;遍历该初始图级ir,将该初始图级ir中的可融合算子标识为同类算子或异类算子;将该初始图级ir转化为张量表达式,融合该张量表达式中的同类算子;将该张量表达式编译为内核源码,融合该内核源码中的异类算子;将该内核源码编译为可执行代码并部署运行。
2、本发明所述的算子融合方法,其中标识该可融合算子的步骤包括:对该初始图级ir的抽象语法树做广度优先搜索,将该标准模型中同一层的算子做并行标识,以得到多组可融合算子;遍历每组可融合算子,将本组内算子种类和输入输出都相同的可融合算子,标识为同一组的同类算子;将本组内算子种类和/或输入输出不相同,且部署运行时最大活跃线程块数处于一个划分区间的可融合算子,标识为同一组的异类算子。
3、本发明所述的算子融合方法,其中,融合该同类算子的步骤包括:对于同一组同类算子,将其对应的张量表达式的输出与输入部分同时增加一个相同的批次维度以生成新张量表达式,该批次维度的大小等于该组同类算子的个数;以该新张量表达式替换该组同类算子在该标准模型的语法树上的位置,并将该新张量表达式的输入与输出接入该语法树。融合该异类算子的步骤包括:对于同一组异类算子,从该内核源码中找到该异类算子的算子内核;将该算子内核的线程块对齐为大小一致;将对齐后的算子内核源到源地融合为单个新算子内核,并将该新算子内核的核函数的线程网格设置为一维结构,重新映射该一维结构的线程索引,以保证该新算子内核的计算逻辑与输入输出的正确性;将本组异类算子所有输入输出重新映射和添加到该新算子内核上;在该新算子内核的核函数内统一分配存储空间,以代替本组异类算子各自核函数内的存储空间请求。
4、本发明所述的算子融合方法,其中对齐该线程块的步骤包括:对于一个该算子内核,减少其线程块的数量,并增大其线程块的大小,或者,保留其线程块数量,并向其线程块内添加空线程来增大线程块的大小,使对齐后的线程块与本组的算子内核中具有的最大线程块大小一致。
5、本发明所述的算子融合方法,其中于标识该可融合算子的步骤前还包括:使用常数折叠和/或死代码消除和/或算子布局调整方式,对该初始图级ir进行优化
6、本发明还提出一种面向深度学习推理任务编译器的算子融合系统,包括:标识模块,用于标识可融合算子;将深度学习推理任务模型的标准模型,转化为初始图级ir;遍历该初始图级ir,将该初始图级ir中的可融合算子标识为同类算子或异类算子;同类算子融合模块,用于将该初始图级ir转化为张量表达式,融合该张量表达式中的同类算子;异类算子融合模块,用于将该张量表达式编译为内核源码,融合该内核源码中的异类算子;运行模块,用于将该内核源码编译为可执行代码并部署运行。
7、本发明所述的算子融合系统,其中该标识模块包括:搜索子模块,用于对该初始图级ir的抽象语法树做广度优先搜索,将该标准模型中同一层的算子做并行标识,以得到多组可融合算子;标识子模块,用于将该可融合算子标识为同类算子或异类算子;遍历每组可融合算子,将本组内算子种类和输入输出都相同的可融合算子,标识为同一组的同类算子;将本组内算子种类和/或输入输出不相同,且部署运行时最大活跃线程块数处于一个划分区间的可融合算子,标识为同一组的异类算子。
8、本发明还提出一种计算机可读存储介质,存储有计算机可执行指令,其特征在于,当该计算机可执行指令被执行时,实现如前所述的面向深度学习推理任务编译器的算子融合方法。
9、本发明还提出一种数据处理装置,包括如前所述的计算机可读存储介质,当该数据处理装置的处理器调取并执行该计算机可读存储介质中的计算机可执行指令时,实现面向深度学习推理任务编译器的算子融合方法。
10、本发明提供的算子融合方法是针对计算图中的可并行算子,其优势在于,这些待融合算子在计算图中可以处于不同的计算路径之上,而且带融合算子可以是非特定算子。
- 还没有人留言评论。精彩留言会获得点赞!