一种知识图谱实体相似度计算方法及系统与流程
本发明涉及数据处理,特别是涉及一种知识图谱实体相似度计算方法及系统。
背景技术:
1、知识图谱实体相似度计算可以应用于如搜索引擎、自然语言处理、推荐系统,知识图谱融合等许多领域中。其具体为:信息检索:利用知识图谱实体相似度计算方法对文本或数据进行语义匹配和相似性搜索,从而提高信息检索的准确性和效率;推荐系统:基于用户的兴趣和行为,利用知识图谱实体相似度计算方法计算不同实体之间的相似度,从而推荐用户感兴趣的内容或产品;生物信息学:利用知识图谱相实体似度计算方法对生物序列、基因、蛋白质等进行相似性计算和分类,从而实现生物信息学中的基因组学、蛋白质组学和代谢组学等领域的研究;社交网络:利用知识图谱实体相似度计算方法对不同用户之间的关系进行建模和计算,从而实现社交网络中的好友推荐和群体分析等任务。
2、传统的知识图谱实体相似度计算主要是基于结构比较的方法,例如计算实体节点的相似度和路径的相似度等。其中,节点相似度计算通常考虑实体之间的属性和标签等信息,而路径相似度计算则着眼于实体之间的关联关系。这种方法的主要问题在于无法考虑到实体之间的上下文信息,难以准确地反映知识图谱的语义相似度。此外,传统的相似度计算方法难以处理知识图谱中的复杂关系和大规模实体数据,因此在实际应用中受到一定的限制。
3、因此提供一种具有更高的计算效率和准确性,尤其在处理大规模知识图谱时表现更为优秀的知识图谱实体相似度计算方法及系统是本领域技术人员亟待解决的问题。
技术实现思路
1、本发明的目的在于提供知识图谱实体相似度计算方法及系统,该方法逻辑清晰,安全、有效、可靠且操作简便,既能有效提高相似度计算效率和准确性,又能在处理大规模知识图谱时表现更为优秀。
2、基于以上目的,本发明提供的技术方案如下:
3、一种知识图谱实体相似度计算方法,包括如下步骤:
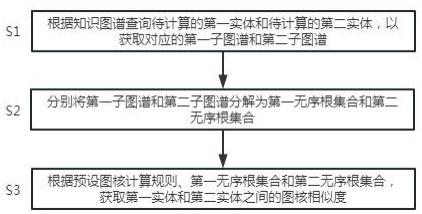
4、s1.根据知识图谱查询待计算的第一实体和待计算的第二实体,以获取对应的第一子图谱和第二子图谱;
5、s2.分别将所述第一子图谱和所述第二子图谱分解为第一无序根集合和第二无序根集合;
6、s3.根据预设图核计算规则、所述第一无序根集合和所述第二无序根集合,获取所述第一实体和所述第二实体之间的图核相似度。
7、优选地,在所述步骤s3之后,还包括:
8、根据第一预设公式标准化所述图核相似度,以获取标准化的图核相似度。
9、优选地,所述第一预设公式具体为:
10、
11、其中,为图核相似度标准化值,为图核相似度,为第一子图谱,为第二子图谱。
12、优选地,所述步骤s2中的分解子图谱,包括如下步骤:
13、以子图谱节点为起始点,按照广度优先遍历算法的顺序添加边和节点,以形成无序根组成的集合;
14、根据上述步骤,则所述第一子图谱对应的分解为第一无序根集合,所述第二子图谱对应的分解为第二无序根集合。
15、优选地,所述以子图谱节点为起始点,按照广度优先遍历算法的顺序添加边和节点,以形成无序根组成的集合,具体为:
16、a1.对每个子图谱节点v,以v为起始点执行广度优先遍历,初始无序根初始化为节点v;
17、a2.按照访问顺序,依次将访问到的节点和边加入至所述初始无序根中;
18、a3.按照遍历顺序为每条边指定方向,以使得每条边均从上一层访问的节点指向本层访问的节点;
19、a4.删除连接已访问的第g层节点与已访问的第l层节点之间的边,其中g<l。
20、优选地,所述步骤s3具体为:
21、b1.根据所述第一无序根集合中的第一初始节点、所述第二无序根集合中的第二初始节点和第二预设公式,计算获取所述第一无序根集合和所述第二无序根集合之间存在相同无序根的数量;
22、b2.根据所述相同无序根的数量和第三预设公式,计算获取树核相似度;
23、b3.根据所述树核相似度和所述第四预设公式,计算获取所述第一实体和所述第二实体之间的图核相似度。
24、优选地,所述步骤b1包括如下步骤:
25、判断所述第一初始节点和所述第二初始节点是否一致;
26、若不一致,则所述相同无序根的数量为0;
27、若一致,且所述第一初始节点和所述第二初始节点均为准叶子节点,则定义所述相同无序根的数量为第一参数;
28、若一致,且所述第一初始节点和所述第二初始节点均不为准叶子节点,则根据所述第二预设公式和所述第一参数计算获取所述相同无序根的数量。
29、优选地,所述第三预设公式具体为:
30、
31、其中,为树核相似度,为以,为根的,的子树之间的相同无序根的数量,为第一初始节点,为第二初始节点,为第一无序根,为第二无序根。
32、优选地,所述第四预设公式具体为:
33、
34、其中,为图核相似度,为第一子图谱,为第二子图谱,第一无序根集合,为第二无序根集合。
35、一种知识图谱实体相似度计算系统,包括:
36、子图谱模块,用于根据知识图谱查询待计算的第一实体和待计算的第二实体,以获取对应的第一子图谱和第二子图谱;
37、分解模块,用于分别将所述第一子图谱和所述第二子图谱分解为第一无序根集合和第二无序根集合;
38、图核相似度模块,用于根据预设图核计算规则、所述第一无序根集合和所述第二无序根集合,获取所述第一实体和所述第二实体之间的图核相似度。
39、本发明所提供的知识图谱相似度计算方法,是通过根据已有的知识图谱查询待计算相似度的第一实体和第二实体,从而获取与第一实体相对应的第一子图谱和与第二实体相对应的第二子图谱;通过将第一子图谱分解为对应的第一无序根集合,将第二子图谱分解为对应的第二无序根集合;通过预设的图核计算规则、第一无序根集合和第二无序根集合,计算获取第一实体与第二实体之间的图核相似度。
40、本发明具体是通过比较第一实体和第二实体的所有关系以及相关实体所构成的第一子图谱和第二子图谱之间的相似性来计算实体相似度,在比较两个子图谱之间的相似性时,通过一种基于有序分解的图核来计算它们的相似度值。相比于现有技术,图核作为一种基于图的子结构衡量图之间相似度的方法,可以捕捉节点和边之间的上下文信息,更好地考虑关联结构的信息,从而在知识图谱实体相似性比较时表现更加出色。另外,相对于传统的计算方法,图核方法具有更高的计算效率和准确性,尤其在处理大规模知识图谱时表现更为优秀。因此,本发明提出的基于图核的知识图谱实体相似度计算方法具有更好的准确性和高效性。
41、本发明还提供了一种知识图谱实体相似度计算系统,由于该系统与该方法解决相同的技术问题,属于相同的技术构思,理应具有相同的有益效果,在此不再赘述。
技术特征:
1.一种知识图谱实体相似度计算方法,其特征在于,包括如下步骤:
2.如权利要求1所述的知识图谱实体相似度计算方法,其特征在于,在所述步骤s3之后,还包括:
3.如权利要求2所述的知识图谱实体相似度计算方法,其特征在于,所述第一预设公式具体为:
4.如权利要求1所述的知识图谱实体相似度计算方法,其特征在于,所述步骤b1包括如下步骤:
5.如权利要求1所述的知识图谱实体相似度计算方法,其特征在于,所述第三预设公式具体为:
6.如权利要求3所述的知识图谱实体相似度计算方法,其特征在于,所述第四预设公式具体为:
7.一种知识图谱实体相似度计算系统,其特征在于,包括:
技术总结
本发明公开了一种知识图谱实体相似度计算方法及系统,包括如下步骤:S1.根据知识图谱查询待计算的第一实体和待计算的第二实体,以获取对应的第一子图谱和第二子图谱;S2.分别将第一子图谱和第二子图谱分解为第一无序根集合和第二无序根集合;S3.根据预设图核计算规则、第一无序根集合和第二无序根集合,获取第一实体和第二实体之间的图核相似度。该方法逻辑清晰,安全、有效、可靠且操作简便,既能有效提高相似度计算效率和准确性,又能在处理大规模知识图谱时表现更为优秀。该系统具有相同的有益效果。
技术研发人员:何嘉伟,王晓龙,左勇
受保护的技术使用者:智慧眼科技股份有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!