一种基于对称直方图分布的神经网络模型隐写分析方法
本发明涉及神经网络模型安全领域,尤其是涉及一种基于对称直方图分布的神经网络模型隐写分析方法。
背景技术:
1、信息隐藏技术能够不可感知地将秘密信息嵌入载体媒介中进行传输,其中以多媒体数据为载体的多媒体信息隐藏及其检测技术在相互对抗中不断发展。近年来,随着深度学习技术广泛应用于人工智能领域,如图像分类、语音识别和自然语言处理等,保护神经网络模型的安全成为人工智能产业化进程中必须面临和解决的难题。
2、类比于多媒体数据,深度神经网络模型以其性能提升被广泛分发和应用于科研和工业部署中,并逐渐成为继图像、视频、音频和文本后的又一新兴的数字媒介。随着深度学习的不断发展,神经网络模型有望在未来成为模型共享平台和在线应用商店的数字产品。这体现了神经网络模型具有的信息媒介特性。此外,多媒体载体因其数据内容中存在的大量信息冗余使得嵌入其中的秘密信息难以被检测,与之类似,神经网络模型具有的深层内部结构和大量的模型参数赋予了模型强大的学习和拟合能力,同时现有的预训练深度神经网络模型通常是过度参数化,这意味着模型参数中存在大量的冗余。从传统数字多媒体载体到神经网络模型作为秘密信息载体,这体现了神经网络模型具有的信息载体特性。现有的神经网络信息隐藏技术包括神经网络水印技术(模型水印)和神经网络隐写技术。模型水印最早于2017年提出,此后得到了学术界和工业界的密切关注并研究了很多方法,可用于神经网络模型的知识产权保护。而神经网络隐写方法更加关注秘密信息的嵌入容量,以实现单信道或多信道下的隐蔽通信,同时由于现有的神经网络隐写方法在网络的训练过程中嵌入秘密信息到模型参数中,其隐写的隐蔽性更强。就高嵌入量和强隐蔽性而言,神经网络隐写可能带来更大的信息安全漏洞,并对深度学习中的神经网络模型安全提出新的挑战。因此,针对神经网络模型的隐写分析方法显得尤为重要。但是,相对于神经网络信息隐藏方法不断被提出,现有的隐写分析方法大都针对以图像、视频、音频和文本等多媒体数据为载体的多媒体信息隐藏,目前有关神经网络模型的有效隐写分析方法却仍然缺失。
技术实现思路
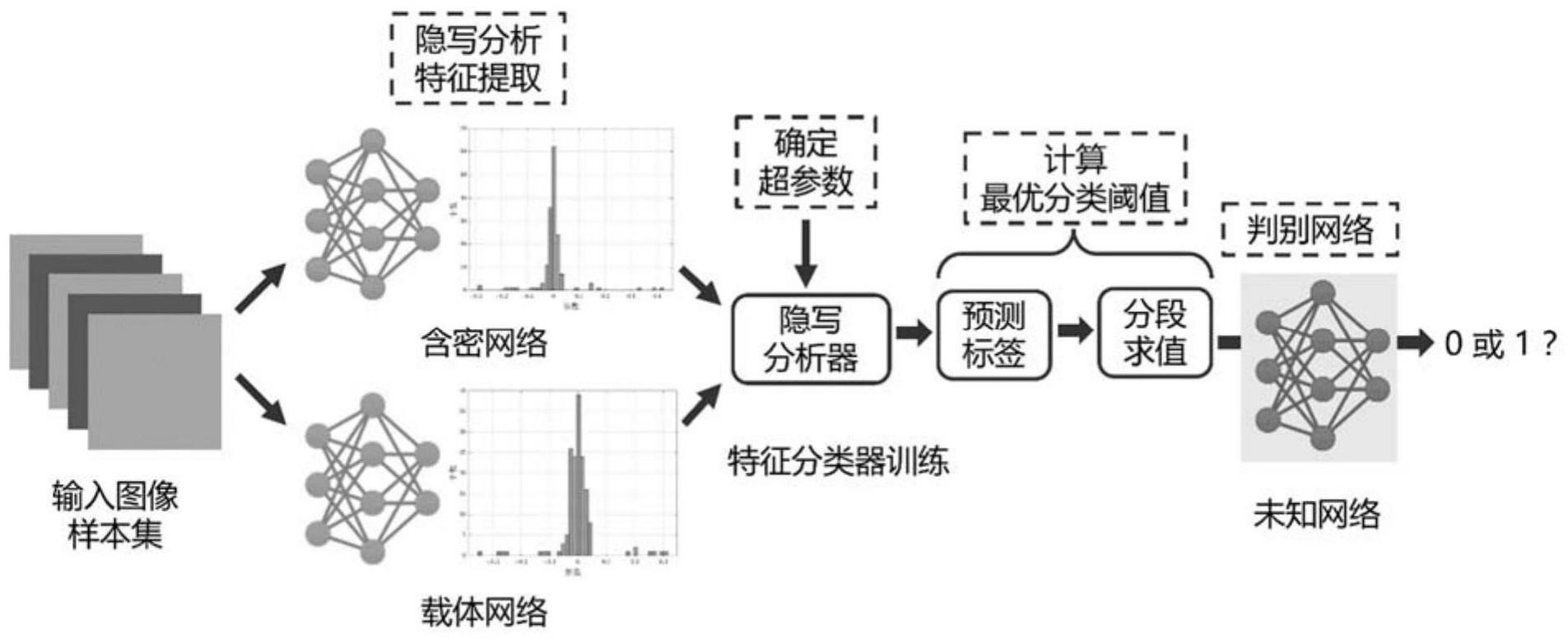
1、本发明的目的是为了提供一种基于对称直方图分布的神经网络模型隐写分析方法,针对以神经网络模型为秘密信息载体构建隐写分析框架与多样性数据集,之后,分析者提取隐写分析特征并用于训练分类器以确定模型超参数,接着,采用高度对称的直方图分布方法确定网络分类最优阈值,作为隐写分析依据;由于特征提取过程无需访问模型任何内部结构和参数细节,以及高度对称的方案不受原始任务类别偏差的影响,因此本发明的隐写分析的实用性和鲁棒性可得到保证。
2、本发明的目的可以通过以下技术方案来实现:
3、一种基于对称直方图分布的神经网络模型隐写分析方法,包括以下步骤:
4、s1、构建用于隐写分析的神经网络模型训练集,所述神经网络模型训练集包括不含密的载体网络和含密网络;
5、s2、基于图像分类数据集测试各网络模型,从网络中提取隐写分析特征并进行预处理;
6、s3、构建svm分类器和集成分类器,以模型分类准确性和泛化性能平衡为指导,以最小化损失为目标,利用隐写分析特征训练svm分类器和集成分类器以确定分类器参数;
7、s4、利用确定参数后的分类器分别预测载体网络和含密网络隐写分析特征的标签,构成标签向量;
8、s5、对标签向量进行分段,并绘制分段检测值的对称直方图及概率密度曲线,确定训练集中每一分段的网络分类最优阈值,按序排列各分段的分类最优阈值,组成最优分类阈值向量,作为网络分类检测依据;
9、s6、获取待检测目标网络数据集并作为输入,利用步骤s2-s4确定待检测目标网络的标签向量,对标签向量进行分段,绘制分段检测值的对称直方图及概率密度曲线,确定待检测目标网络的各分段阈值组成阈值向量,并与最优分类阈值向量比较,若符合度大于预设百分比即判定待检测目标网络为含有秘密信息的含密网络。
10、所述提取隐写分析特征的隐写分析器表示为:
11、{p(1),p(2),...,p(m)}=fdetector(dtrain)
12、其中,fdetector为隐写分析二分类器,由载体网络特征和含密网络特征组成的训练集拟合得到,ntrn为输入样本数量;在拟合过程中,最小化预测标签{p(1),p(2),...,p(m)}ntrn∈{0,1}m与真实标签间差异,预测标签为0代表载体网络特征,1代表含密网络特征。
13、所述svm分类器定义为:
14、fsvm:ωtx+b=0
15、其中ω=(ω1;ω2;...;ωd)为目标分类超平面的法向量,b为与原点间的距离,使用核函数将特征空间映射到高维空间求解最优划分超平面。
16、所述svm分类器的损失函数l由结构损失函数和经验损失函数两部分组成:
17、l=lω+c·ll
18、
19、
20、其中,lω为结构损失函数,用于引入模型结构先验知识并防止过拟合;ll为经验损失函数,用于惩罚误分类情况;超参数c用于调整两部分损失的比重;核函数l()用于特征空间映射。
21、所述svm分类器的惩罚项c和核函数l()通过交叉验证确定最佳选择。
22、所述集成分类器实现为由n个fisher线性判别分类器作为个体学习器b(n)(x)∈{0,1}组成的随机森林,通过使用多数表决策略集成各个体学习器的所有决策以形成最终决策,决策阈值设为n/2:
23、
24、其中表示第n个子特征。
25、所述集成分类器的包外误差用于监测训练过程和确定最优模型参数,表示为:
26、
27、其中,为训练集中载体网络和含密网络特征对,ntrn为输入样本数量。
28、所述集成分类器的总检测误差pe用于评估集成分类器性能,表示为:
29、
30、其中,pfa和pmd分别为虚警率和漏检率。
31、所述集成分类器的个体学习器数目n和特征子空间维度dsub在训练过程中根据包外误差自动确定。
32、所述s5具体为:
33、假定训练集中的载体网络和含密网络各cnet个,将s4得到的2·cnet个标签向量以相同形式分段划分,使得每个分段segi长度为其中,dout为分类类别数;
34、计算每个分段中标签为1的数量作为该分段检测值,其中,标签为0代表载体网络特征,1代表含密网络特征;
35、分别绘制cnet个载体网络和含密网络的相同索引下标i的分段检测值的直方图及概率密度曲线,求同一坐标下两条密度曲线的唯一相交点,所述相交点对应横坐标值即确定为所在分段的最优分类阈值
36、按序排列各分段分类阈值组成最终的最优分类阈值向量
37、与现有技术相比,本发明具有以下有益效果:
38、(1)本发明实现了一种新的隐写分析方案,即以图像分类神经网络模型为秘密信息载体的隐写分析,将隐写分析从多媒体内容扩展到深度神经网络模型,从而保护深度神经网络模型免于被用来传输秘密信息。
39、(2)本发明设计了一种基于直方图分布的高度对称方案来确定最优分类阈值,作为神经网络模型隐写分析的判别依据,其中隐写分析者可直接通过“黑盒”式输入-输出交互方式运行神经网络模型来提取隐写特征,而无需访问模型内部结构和参数细节。
40、(3)本发明基于构建的多样性神经网络数据集,拟合svm和集成分类器作为隐写分析器,以渐进方式测试了适用于不同实际场景的神经网络模型隐写分析,并取得较高的分类准确率,大量实验证明了本发明的实用性和鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!