一种数据处理方法及装置与流程
本技术涉及数据处理,具体而言,涉及一种数据处理方法及装置。
背景技术:
1、目前,ibm主机(mainframe)作为计算机中的顶级产品,由于其安全性(尚无黑客可以对其进行攻击)和高可靠性(号称全年宕机时间不超过5分钟)一直被用于金融、证券等行业,而dfsort(基于ibm z/os为数据分析提供排序、合并、拷贝、过滤、解析、编辑、重新格式化、求和等功能)与icetool(一个多用途的dfsort使用程序,在一个作业步中对一个或多个数据集执行多个操作)作为ibm两款针对数据分析的产品,仍旧在国内大型银行的金融业务中扮演着重要角色。然而,在实践中发现,ibm主机具有封闭集中式架构,无法进行数据处理的自主可控,同时,使用ibm主机需要高昂的采购与维护成本。
技术实现思路
1、本技术实施例的目的在于提供一种数据处理方法及装置,能够替代ibm主机对数据进行分布式处理,实现数据处理的自主可控,同时有效减少了业务和技术的耦合度,从而显著降低业务开发人员的时间成本,并在提高了系统的可用性的同时也大大降低了运维成本。
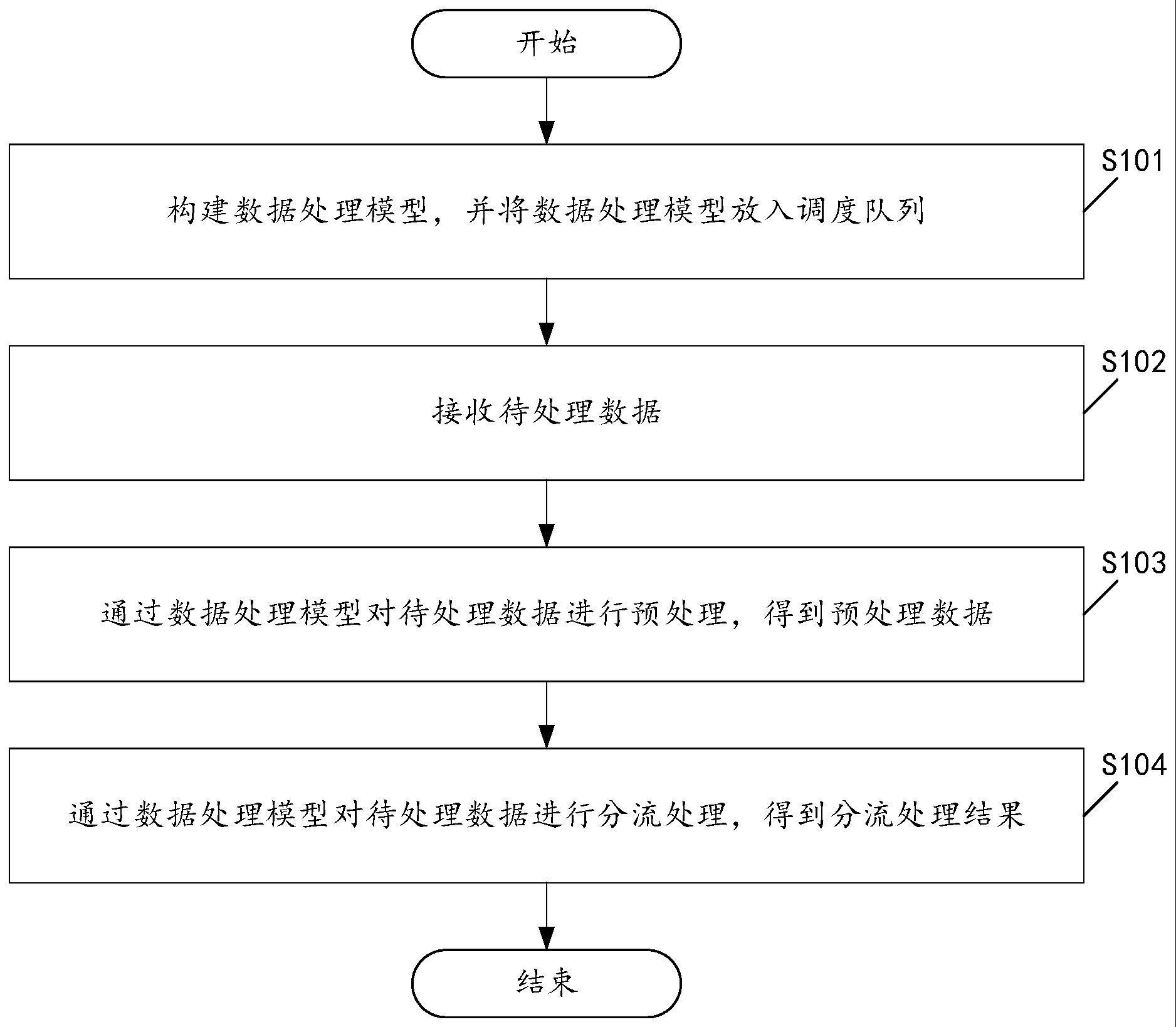
2、本技术实施例第一方面提供了一种数据处理方法,包括:
3、构建数据处理模型,并将所述数据处理模型放入调度队列;
4、接收待处理数据;
5、通过所述数据处理模型对所述待处理数据进行预处理,得到预处理数据;
6、通过所述数据处理模型对所述待处理数据进行分流处理,得到分流处理结果。
7、在上述实现过程中,该方法可以优先构建数据处理模型,并将数据处理模型放入调度队列;然后,接收待处理数据,并通过数据处理模型对待处理数据进行预处理,得到预处理数据;最后,再通过数据处理模型对待处理数据进行分流处理,得到分流处理结果。可见,该方法能够替代ibm主机对数据进行分布式处理,实现数据处理的自主可控,同时有效减少了业务和技术的耦合度,从而显著降低业务开发人员的时间成本,并在提高了系统的可用性的同时也大大降低了运维成本。
8、进一步地,所述构建数据处理模型,包括:
9、接收企业级作业调度平台下发的至少一个批处理作业;其中,所述批处理作业包括一个或多个作业步,且每个作业步之间有依赖关系;
10、对所述批处理作业进行解析,得到解析数据;
11、根据所述解析数据构建为以作业步为单位的数据处理模型;其中,所述数据处理模型包括数据输入上下文、数据处理逻辑上下文以及数据输出上下文。
12、进一步地,所述通过所述数据处理模型对所述待处理数据进行预处理,得到预处理数据,包括:
13、确定所述数据处理模型的输入上下文;
14、获取所述输入上下文中定义的元数据;其中,所述元数据包括数据源类型、数据格式、数据分区以及数据代理方式;
15、根据所述元数据对待处理数据进行预处理,得到预处理数据。
16、进一步地,所述通过所述数据处理模型对所述待处理数据进行分流处理,得到分流处理结果,包括:
17、确定所述数据处理模型的处理逻辑上下文;
18、获取所述处理逻辑上下文中的作业步jcl文件;
19、通过预先配置的语义解析器将所述作业步jcl文件进行格式转换,得到预设文件格式的目标文件;其中,所述目标文件包括type字段部分、input字段部分以及output字段部分;
20、根据所述元数据加载所述预处理数据,并结合所述目标文件对所述预处理数据进行分流处理,得到分流处理结果。
21、进一步地,所述结合所述目标文件对所述预处理数据进行分流处理,得到分流处理结果,包括:
22、根据所述目标文件,按照数据大小对所述预处理数据进行分流,得到第一分流数据和第二分流数据;其中,所述第一分流数据的数据大小小于预设阈值,所述第二分流数据的数据大小不小于所述预设阈值;
23、对所述第一分流数据进行lambda流式处理,得到第一处理结果,以及采用预先配置的spark、flink框架对所述第二分流数据进行处理,得到第二处理结果;
24、汇总所述第一处理结果和所述第二处理结果,得到分流处理结果。
25、本技术实施例第二方面提供了一种数据处理装置,所述数据处理装置包括:
26、构建单元,用于构建数据处理模型,并将所述数据处理模型放入调度队列;
27、接收单元,用于接收待处理数据;
28、预处理单元,用于通过所述数据处理模型对所述待处理数据进行预处理,得到预处理数据;
29、分流处理单元,用于通过所述数据处理模型对所述待处理数据进行分流处理,得到分流处理结果。
30、在上述实现过程中,该装置可以通过构建单元构建数据处理模型,并将数据处理模型放入调度队列;通过接收单元接收待处理数据;通过预处理单元来通过数据处理模型对待处理数据进行预处理,得到预处理数据;再通过分流处理单元来通过数据处理模型对待处理数据进行分流处理,得到分流处理结果。可见,该装置能够替代ibm主机对数据进行分布式处理,实现数据处理的自主可控,同时有效减少了业务和技术的耦合度,从而显著降低业务开发人员的时间成本,并在提高了系统的可用性的同时也大大降低了运维成本。
31、进一步地,所述构建单元包括:
32、接收子单元,用于接收企业级作业调度平台下发的至少一个批处理作业;其中,所述批处理作业包括一个或多个作业步,且每个作业步之间有依赖关系;
33、解析子单元,用于对所述批处理作业进行解析,得到解析数据;
34、构建子单元,用于根据所述解析数据构建为以作业步为单位的数据处理模型;其中,所述数据处理模型包括数据输入上下文、数据处理逻辑上下文以及数据输出上下文。
35、进一步地,所述预处理单元包括:
36、第一确定子单元,用于确定所述数据处理模型的输入上下文;
37、第一获取子单元,用于获取所述输入上下文中定义的元数据;其中,所述元数据包括数据源类型、数据格式、数据分区以及数据代理方式;
38、预处理子单元,用于根据所述元数据对待处理数据进行预处理,得到预处理数据。
39、进一步地,所述分流处理单元包括:
40、第二确定子单元,用于确定所述数据处理模型的处理逻辑上下文;
41、第二获取子单元,用于获取所述处理逻辑上下文中的作业步jcl文件;
42、转换子单元,用于通过预先配置的语义解析器将所述作业步jcl文件进行格式转换,得到预设文件格式的目标文件;其中,所述目标文件包括type字段部分、input字段部分以及output字段部分;
43、处理子单元,用于根据所述元数据加载所述预处理数据,并结合所述目标文件对所述预处理数据进行分流处理,得到分流处理结果。
44、进一步地,所述处理子单元包括:
45、分流模块,用于根据所述目标文件,按照数据大小对所述预处理数据进行分流,得到第一分流数据和第二分流数据;其中,所述第一分流数据的数据大小小于预设阈值,所述第二分流数据的数据大小不小于所述预设阈值;
46、处理模块,用于对所述第一分流数据进行lambda流式处理,得到第一处理结果,以及采用预先配置的spark、flink框架对所述第二分流数据进行处理,得到第二处理结果;
47、汇总模块,用于汇总所述第一处理结果和所述第二处理结果,得到分流处理结果。
48、本技术实施例第三方面提供了一种电子设备,包括存储器以及处理器,所述存储器用于存储计算机程序,所述处理器运行所述计算机程序以使所述电子设备执行本技术实施例第一方面中任一项所述的数据处理方法。
49、本技术实施例第四方面提供了一种计算机可读存储介质,其存储有计算机程序指令,所述计算机程序指令被一处理器读取并运行时,执行本技术实施例第一方面中任一项所述的数据处理方法。
- 还没有人留言评论。精彩留言会获得点赞!