一种基于初始解优化的光片上网络映射方法
本发明属于片上网络,具体涉及一种基于初始解优化的光片上网络映射方法。
背景技术:
1、伴随半导体技术的发展,光片上网络(optical network-on-chip,onoc)逐渐代替传统的通信架构成为片上系统(system-on-chip,soc)上首选片上通信架构,onoc是片上系统的一种新的通信方法,它是多核技术的主要组成部分。onoc借鉴了并行计算和计算机网络的设计思想,不同拓扑节点连接到不同的片上路由器中。随着onoc连接的拓扑节点数量的增加,拓扑节点连接到不同路由器极大影响着onoc设计的性能。因此,应用核图中ip核到拓扑节点的映射问题是onoc设计中的一个关键问题。
2、ip核映射指的是将ip核分配到onoc拓扑节点上,以使得网络性能最优。这个问题已经被证明是一个np难问题。随着问题规模的增大,整个解空间呈现爆炸增长。目前,有诸多学者对ip核映射问题展开了研究,并提出大量映射算法。最为广泛采用的映射算法是启发式算法,启发式算法在复杂度和求解时间方面具有优势,但是,启发式算法容易陷入局部最优,从而影响结果的准确性,会对onoc的性能和可靠性产生影响。
技术实现思路
1、为了解决现有技术中存在的上述问题,本发明提供了一种基于初始解优化的光片上网络映射方法。本发明要解决的技术问题通过以下技术方案实现:
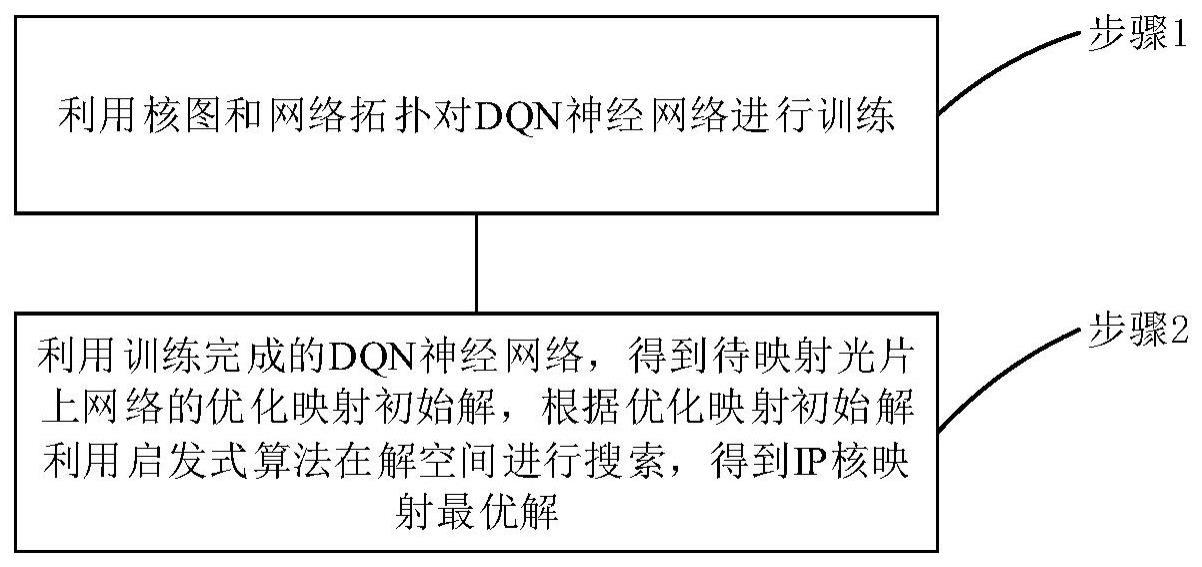
2、本发明提供了一种基于初始解优化的光片上网络映射方法,包括:
3、步骤1:利用核图和网络拓扑对dqn神经网络进行训练;
4、步骤2:利用训练完成的dqn神经网络,得到待映射光片上网络的优化映射初始解,根据所述优化映射初始解利用启发式算法在解空间进行搜索,得到ip核映射最优解。
5、在本发明的一个实施例中,所述步骤1包括:
6、步骤1.1:将所述网络拓扑作为与所述dqn神经网络进行交互的环境;其中,利用所述网络拓扑对应的状态向量表示所述核图中ip核的映射情况;
7、步骤1.2:构建dqn神经网络并进行初始化;其中,所述dqn神经网络包括网络结构相同的主网络和目标网络;所述dqn神经网络根据输入的当前的状态向量,得到下一映射动作的预测q值;
8、步骤1.3:将所述网络拓扑对应的状态向量输入所述dqn神经网络进行训练,直至达到预设的训练截止条件,得到训练完成的dqn神经网络。
9、在本发明的一个实施例中,所述状态向量的维度与所述网络拓扑的节点数目一致,所述状态向量中的元素与所述网络拓扑的节点一一对应;
10、当所述状态向量中元素的取值为0,则该元素对应的网络拓扑的节点没有映射的ip核,否则,该元素对应的网络拓扑的节点已存在映射的ip核,且元素值表示映射的ip核的索引。
11、在本发明的一个实施例中,所述dqn神经网络的映射动作的数量与所述网络拓扑的节点数目一致,每个映射动作与所述网络拓扑的节点一一对应,所述映射动作表示将ip核映射到该映射动作对应的网络拓扑的节点。
12、在本发明的一个实施例中,所述步骤1.3包括:
13、步骤1.31:初始化所述网络拓扑的状态向量,得到全零的初始状态向量,所述初始状态向量作为当前的状态向量;
14、步骤1.32:根据当前的状态向量,利用贪婪算法选择一个映射动作;
15、步骤1.33:根据选择的映射动作对当前的状态向量进行更新,得到下一状态向量,计算得到该选择的映射动作对应的奖励值和q值偏差;
16、步骤1.34:将当前的状态向量、选择的映射动作、选择的映射动作对应的奖励值、下一状态向量和选择的映射动作对应的q值偏差,组合成一条经验并存入经验池中;
17、步骤1.35:将下一状态向量作为当前的状态向量,重复步骤1.32-步骤1.34直至所述核图中的所有ip核一一对应地映射到所述网络拓扑的节点,得到结束状态向量,完成一次迭代训练;
18、步骤1.36:重复步骤1.31-步骤1.35利用所述网络拓扑对应的状态向量进行下一次迭代训练;
19、步骤1.37:每达到预设的迭代训练次数后,进入所述dqn神经网络的参数更新阶段,从所述经验池之中抽取预设数量的经验,对所述dqn神经网络的网络参数进行更新,使用更新的dqn神经网络继续迭代训练,直至达到预设的迭代训练截止次数,得到训练完成的dqn神经网络;
20、其中,在经验池存满时,按照先进先出的原则,将新生成的经验覆盖所述经验池中的旧经验。
21、在本发明的一个实施例中,所述步骤1.32包括:
22、步骤①:设置贪婪系数ε,其中,0<ε<1;
23、步骤②:生成一个随机数,若所述随机数小于ε,则在可选择的映射动作中随机选择一个映射动作,否则根据所述dqn神经网络的主网络的输出结果在可选择的映射动作中选择一个映射动作;
24、其中,所述可选择的映射动作为当前的状态向量中为零的元素值对应的网络拓扑的节点的映射动作;
25、根据所述dqn神经网络的主网络的输出结果在可选择的映射动作中选择一个映射动作;包括:
26、将所述当前的状态向量输入所述dqn神经网络的主网络中,在可选择的映射动作中选择所述主网络输出的最大的预测q值对应映射动作。
27、在本发明的一个实施例中,当执行选择的映射动作后,所述核图中的ip核没有全部映射完成,则该选择的映射动作对应的奖励值为0;
28、当执行选择的映射动作后,所述核图中的所有ip核全部映射完成,则该选择的映射动作对应的奖励值为所述结束状态向量对应的光片上网络最坏情况下光信噪比。
29、在本发明的一个实施例中,所述选择的映射动作对应的q值偏差按照下式计算得到:
30、td-error=qtarget-q(s,aj;θ);
31、
32、其中,td-error表示q值偏差,qtarget表示目标q值,q(s,aj;θ)表示将当前的状态向量输入主网络中,主网络输出的选择的映射动作对应的预测q值,s表示当前的状态向量,aj表示选择的映射动作,θ表示主网络的参数,r表示奖励值,γ表示折扣系数,表示将下一状态向量输入目标网络中,在可选择的映射动作中目标网络输出的最大的预测q值,s'表示下一状态向量,aj'表示目标网络根据输入的下一状态向量选择的下一映射动作,θ-表示目标网络的参数,a'表示可选择的映射动作。
33、在本发明的一个实施例中,在所述步骤1.37中,从所述经验池之中抽取预设数量的经验,对所述dqn神经网络的网络参数进行更新,包括:
34、步骤ⅰ:从所述经验池中抽取预设数量的经验;
35、步骤ⅱ:将抽取的经验分别输入至所述dqn神经网络的主网络和目标网络中,根据构建的损失函数,利用梯度下降法对所述主网络的网络参数进行更新;其中,所述损失函数为:
36、
37、loss(θ)=(qtarget-q(s,aj;θ))2;
38、式中,qtarget表示目标q值,q(s,aj;θ)表示将当前的状态向量输入主网络中,主网络输出的选择的映射动作对应的预测q值,s表示当前的状态向量,aj表示选择的映射动作,θ表示主网络的参数;
39、步骤ⅲ:所述主网络的网络参数更新完成之后,利用更新的dqn神经网络将所抽取的经验中的q值偏差进行更新;
40、步骤ⅳ:根据设置的更新频次,将所述主网络的网络参数与所述目标网络的网络参数进行同步。
41、在本发明的一个实施例中,所述步骤2包括:
42、步骤2.1:对所述待映射光片上网络的状态向量进行初始化,得到所述待映射光片上网络的初始状态向量,将所述初始状态向量作为当前的状态向量;
43、步骤2.2:将当前的状态向量输入至训练完成的dqn神经网络的主网络中,所述主网络根据输入的当前的状态向量,得到下一映射动作的预测q值;
44、步骤2.3:从可选择的映射动作中,选择最大预测q值对应的映射动作,根据选择的映射动作对当前的状态向量进行更新,得到下一状态向量;
45、步骤2.4:将下一状态向量作为当前的状态向量,重复步骤2.2-步骤2.3直至所述待映射光片上网络的核图中的所有ip核一一对应地映射到所述待映射光片上网络的网络拓扑的节点,得到结束状态向量;
46、步骤2.5:根据所述结束状态向量得到优化映射初始解,利用启发式算法在解空间进行搜索,得到ip核映射最优解。
47、与现有技术相比,本发明的有益效果在于:
48、本发明的基于初始解优化的光片上网络映射方法,利用给定的核图和网络拓扑对dqn神经网络进行训练,通过训练完成的dqn神经网络得到待映射光片上网络的优化映射初始解,与启发式算法结合在解空间进行搜索得到ip核映射最优解,相比于仅使用启发式算法解决ip核映射问题,本发明方法利用dqn神经网络对映射初始解进行优化后再进行解空间搜索,可以更快、更好地搜索到映射最优解,提高onoc的性能和可靠性。
49、上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其他目的、特征和优点能够更明显易懂,以下特举较佳实施例,并配合附图,详细说明如下。
- 还没有人留言评论。精彩留言会获得点赞!