知识问答方法、装置、设备及存储介质与流程
本技术涉及大语言模型,更具体的说,是涉及一种知识问答方法、装置、设备及存储介质。
背景技术:
1、知识问答是指,用户向机器提出指令,由机器针对用户提出的指令给出对应的答复内容的过程。
2、现有的知识问答方案大多为基于知识图谱方案或者基于文本相似度匹配方案。知识图谱方案需要预先根据业务场景构建图谱的纲要schema,然后根据schema将大量的结构化或者非结构化数据整理成三元组。在知识检索过程,将用户请求中的实体抽取出来,在知识图谱中匹配实体相关的三元组,进而将三元组中的实体属性值作为答案输出。文本相似度匹配方案需要预先收集同一类问题的各种表达及对应的答案,将各种表达及答案整理到知识库中。在知识检索过程,基于用户请求在知识库中查找相同或相似的问题表达,并将查找到的问题表达对应的答案输出。
3、上述无论是基于知识图谱方案还是基于文本相似度匹配方案,其在进行知识检索时均是基于用户请求进行文本相似度的计算,并基于相似度计算结果确定最终的知识答案。其并未真正理解用户的问题,这就导致最终给出的知识答案出现错误的概率较高,示例如对于如下两个用户提问:“一班的班长”、“二班的班长”,二者的文本相似度很高但是表达的意思却完全不同,在无法真正理解问题的情况下,极容易给出错误的知识答案。
技术实现思路
1、鉴于上述问题,提出了本技术以便提供一种知识问答方法、装置、设备及存储介质,以解决现有基于用户请求进行文本相似度计算来确定知识答案的方式,并未真正理解用户问题,导致给出的知识答案容易出错的问题。具体方案如下:
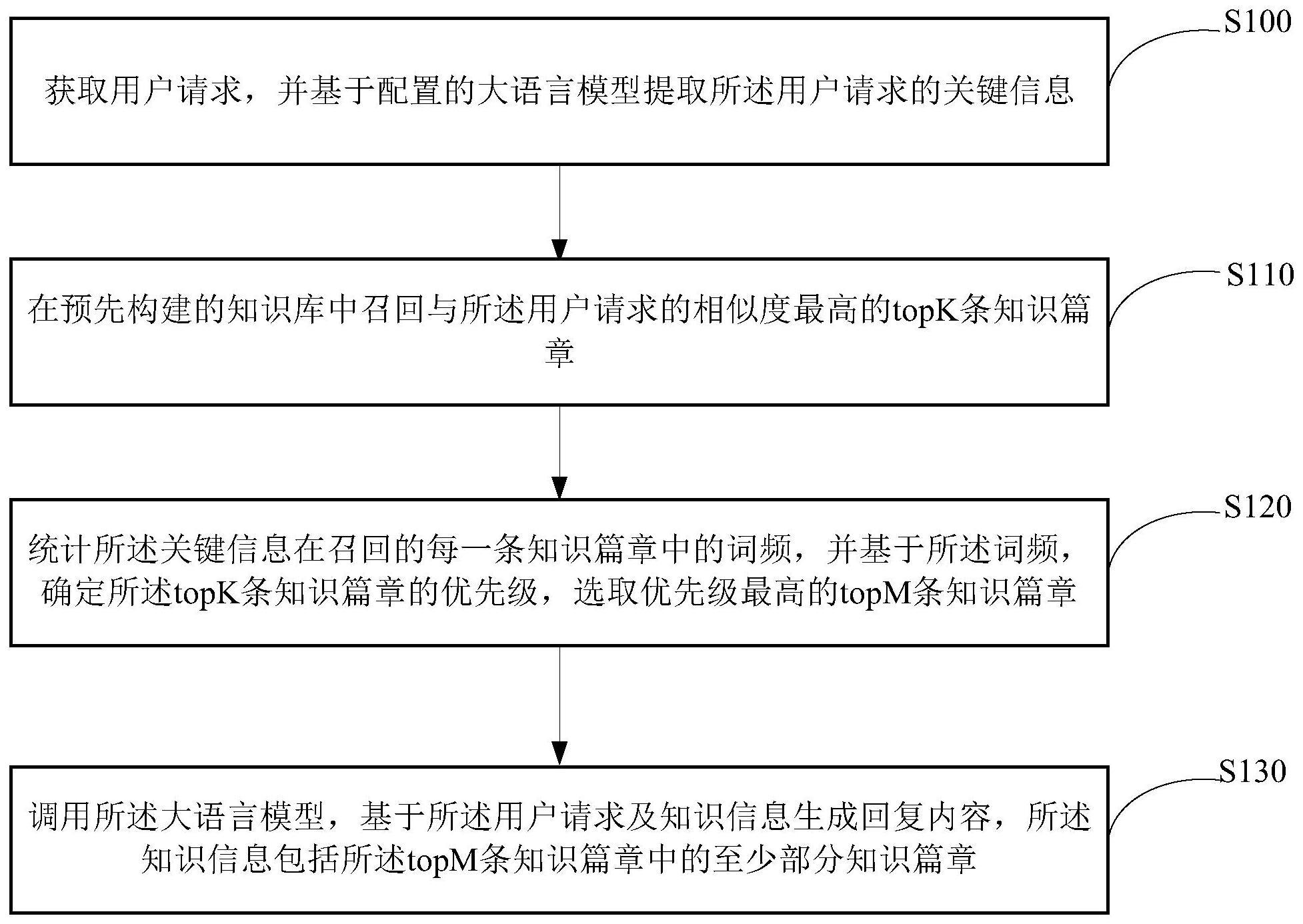
2、第一方面,提供了一种知识问答方法,包括:
3、获取用户请求,并基于配置的大语言模型提取所述用户请求的关键信息;
4、在预先构建的知识库中召回与所述用户请求的相似度最高的topk条知识篇章;
5、统计所述关键信息在召回的每一条知识篇章中的词频,并基于所述词频,确定所述topk条知识篇章的优先级,选取优先级最高的topm条知识篇章,其中词频与优先级间呈正相关关系,m<k;
6、调用所述大语言模型,基于所述用户请求及知识信息生成回复内容,所述知识信息包括所述topm条知识篇章中的至少部分知识篇章。
7、优选地,所述知识库中的每一条知识篇章均对应有向量表征;
8、在预先构建的知识库中召回与所述用户请求的相似度最高的topk条知识篇章,包括:
9、生成与所述用户请求对应的目标查询向量表征;
10、基于所述目标查询向量表征及所述知识库中各条知识篇章的向量表征进行相似度运算,并召回相似度最高的topk条知识篇章。
11、优选地,所述知识库中每一条知识篇章对应的向量表征通过预训练的双塔模型中的第二编码器编码得到,所述双塔模型在训练过程通过第一编码器对用户输入进行编码,通过第二编码器对知识篇章进行编码;
12、所述生成与所述用户请求对应的目标查询向量表征,包括:
13、采用所述双塔模型中的第一编码器对所述用户请求进行编码,得到目标查询向量表征。
14、优选地,基于配置的大语言模型提取所述用户请求的关键信息,包括:
15、获取预配置的第一prompt格式模板,所述第一prompt格式模板包括用户请求信息槽,所述第一prompt格式模板用于指示大语言模型将用户请求信息槽内的用户请求拆解为若干个子问题,并提取用户请求中的关键信息;
16、将所述用户请求填充至所述用户请求信息槽,得到编辑后的第一提示指令prompt,并输入大语言模型,得到大语言模型输出的对所述用户请求拆解后的若干个子问题及用户请求包含的关键信息。
17、优选地,所述知识库中的每一条知识篇章均对应有向量表征;
18、在预先构建的知识库中召回与所述用户请求的相似度最高的topk条知识篇章,包括:
19、生成与每一所述子问题对应的目标查询向量表征;
20、基于每一所述目标查询向量表征及所述知识库中各条知识篇章的向量表征进行相似度运算,并召回相似度最高的topk条知识篇章。
21、优选地,所述第一prompt格式模板还用于指示大语言模型理解用户的查询意图;
22、则在将第一提示指令prompt输入大语言模型后,还得到大语言模型输出的与用户请求对应的用户查询意图;
23、所述调用所述大语言模型,基于所述用户请求及知识信息生成回复内容,包括:
24、调用所述大语言模型,基于所述用户查询意图及知识信息生成回复内容。
25、优选地,所述调用所述大语言模型,基于所述用户查询意图及知识信息生成回复内容,包括:
26、获取预配置的第二prompt格式模板,所述第二prompt格式模板包括用户查询意图槽和知识信息槽,所述第二prompt格式模板用于指示大语言模型参考所述知识信息槽内的知识信息,生成所述用户查询意图槽内的用户查询意图匹配的回复;
27、将所述用户查询意图填充至所述用户查询意图槽、将所述知识信息填充至所述知识信息槽,得到编辑后的第二提示指令prompt,并输入大语言模型,得到大语言模型输出的回复内容。
28、优选地,在调用所述大语言模型,基于所述用户请求及知识信息生成回复内容之前,该方法还包括:
29、分别对所述topm条知识篇章中每条知识篇章的向量表征与所述目标查询向量表征进行交叉混合编码,并基于交叉混合编码向量计算相似度,召回相似度最高的topn条知识篇章,n<m;
30、则所述知识信息具体包括:所述topn条知识篇章。
31、优选地,分别对所述topm条知识篇章中每条知识篇章的向量表征与所述目标查询向量表征进行交叉混合编码,并基于交叉混合编码向量计算相似度,包括:
32、将所述topm条知识篇章中每条知识篇章的向量表征分别与所述目标查询向量表征拼接为句子对,并输入到预训练的bert模型,基于bert模型输出的句子对的交叉混合编码向量计算相似度。
33、优选地,基于所述词频,确定所述topk条知识篇章的优先级,包括:
34、按照每一条知识篇章的词频大小,对所述topk条知识篇章的优先级进行排序,词频越大的知识篇章的优先级越高;
35、或,
36、以每一条知识篇章的词频大小作为权重,对每一条知识篇章与所述用户请求的相似度进行加权,得到每一条知识篇章与所述用户请求的加权后相似度;
37、按照加权后相似度,对所述topk条知识篇章的优先级进行排序,加权后相似度越大的知识篇章的优先级越高。
38、第二方面,提供了一种知识问答装置,包括:
39、用户请求获取单元,用于获取用户请求;
40、第一大语言模型调用单元,用于基于配置的大语言模型提取所述用户请求的关键信息;
41、知识召回单元,用于在预先构建的知识库中召回与所述用户请求的相似度最高的topk条知识篇章;
42、词频处理单元,用于统计所述关键信息在召回的每一条知识篇章中的词频,并基于所述词频,确定所述topk条知识篇章的优先级,选取优先级最高的topm条知识篇章,其中词频与优先级间呈正相关关系,m<k;
43、第二大语言模型调用单元,用于调用所述大语言模型,基于所述用户请求及知识信息生成回复内容,所述知识信息包括所述topm条知识篇章中的至少部分知识篇章。
44、第三方面,提供了一种知识问答设备,包括:存储器和处理器;
45、所述存储器,用于存储程序;
46、所述处理器,用于执行所述程序,实现如前所述的知识问答方法的各个步骤。
47、第四方面,提供了一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现如前所述的知识问答方法的各个步骤。
48、借由上述技术方案,本技术在知识库中召回与用户请求相似度最高的topk条知识篇章,以及通过大语言模型提取用户请求中的关键信息,统计关键信息在召回的每条知识篇章中的词频,并基于词频确定topk条知识篇章的优先级,选取优先级最高的topm条知识篇章,最后,调用大语言模型,基于用户请求和topm条知识篇章中的至少部分知识篇章,来生成回复内容。显然,本技术方案并未直接将从知识库中召回的知识篇章作为答案输出,而是进一步与用户请求进行组合,输入到大语言模型,充分利用大语言模型的文本理解能力对用户请求进行理解,并基于召回的相关知识篇章,辅助生成与用户请求相匹配的回复内容,使得该生成的回复内容更加准确,更加满足用户的请求。
49、进一步地,本技术在确定用户请求相关的知识篇章时,也利用了大语言模型的理解能力,从用户请求中提取出关键信息,对于在知识库中召回的与用户请求相似度最高的topk条知识篇章,对每条知识篇章进行关键信息的词频统计,以此来进一步确定topk条知识篇章的优先级,并从中选取topm条优先级高的知识篇章,其与用户请求的相关程度更高,将topm条知识篇章送入大语言模型辅助进行回复内容的生成,能够更加有利于大语言模型基于该知识篇章来生成与用户请求匹配的回复内容。
- 还没有人留言评论。精彩留言会获得点赞!