基于信息关联机制的任务型对话系统的制作方法
本发明涉及数据处理,具体涉及基于信息关联机制的任务型对话系统。
背景技术:
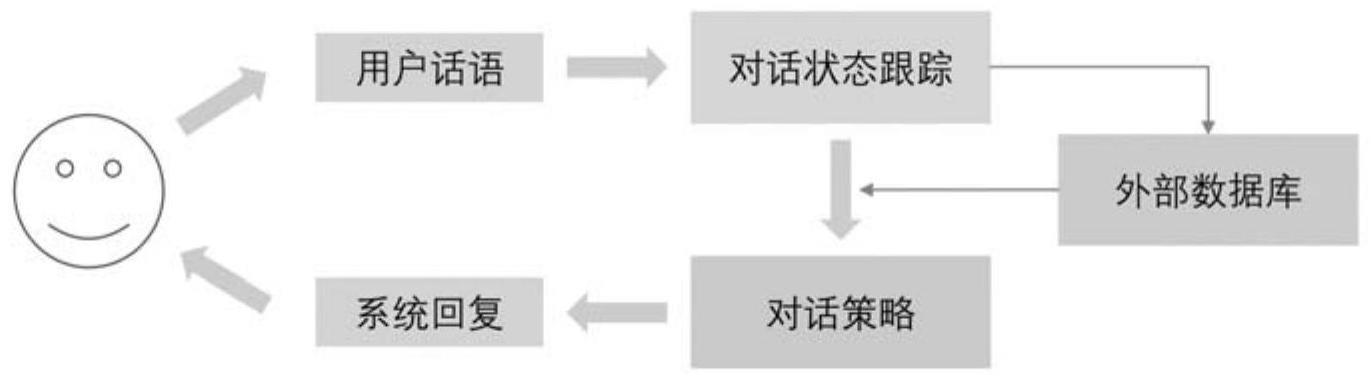
1、和现有的大多数对话系统不同,该数据处理系统面向垂直领域,需要领用尽可能少的对话来帮助用户完成任务,如预定酒店、火车票以及机票等;目前数据处理系统主要由两大部分组成,第一个是对话状态跟踪,以对话历史作为输入,对话状态跟踪就是在对话过程中维护并更新对话状态;第二个是对话策略,对话策略就是根据当前的对话状态决定对话系统下一步的动作并根据对话策略选择的动作生成一句话。
2、现有的数据处理系统的对话状态跟踪模型大都需要预定义的本体(ontology),即把所有领域具体槽可能的值都预定义好,虽然可以简化数据处理系统结构,但是这类数据处理系统存在如下缺点:在现实世界中不可能把所有领域具体槽可能出现的槽预定义好,因为现实世界是不断变化的;其次,这类数据处理系统通常需要额外的自然语言理解模块来协助对话状态跟踪,这使得在对话状态跟踪模型训练过程中会收到自然语言理解模块噪声的影响,进而影响精度;最后目前的数据处理系统大都没有考虑领域间信息关联的问题,由于人类的语言变化多端,这需要对话系统能够有效辨别出哪些领域的信息是可共享的;对话策略模型需要准确地预测出相应的对话动作并生成一段回复反馈用户;然而当前的序列到序列(sequence to sequence)模型通常会产生“我不知道”之类的无效信息回应阻碍对话继续进行;此外,多领域对话策略涉及多个领域对话动作,序列到序列模型通常使用一个对话动作的全局向量来生成系统回复,在一个对话回合中有多个对话动作时,这需要模型为不同的对话动作生成不同的系统回复子序列,全局向量不能捕捉对话动作之间的相互关系,也不能灵活地生成响应,特别是涉及到多个对话动作时。
技术实现思路
1、针对背景技术中存在的技术缺陷,本发明提出基于信息共享机制的数据处理系统,解决了上述技术问题以及满足了实际需求,具体的技术方案如下所示:
2、基于信息关联机制的任务型对话系统,包括数据处理系统,所述数据处理系统包括对话状态跟踪子系统和对话策略子系统;所述对话状态跟踪子系统用于获取对话状态,所述对话状态由领域具体槽与其相关值组成,一个领域具体槽由领域和槽两部分组成,领域具体槽与其相关值组成领域-槽-值三元组,全部所述领域-槽-值三元组组成对话状态,所述领域具体槽包括相似领域具体槽和所述非相似领域具体槽;所述对话策略子系统用于对话策略和系统回复生成,所述对话策略由对话动作组成,所述对话动作由领域、动作以及槽组成,系统回复根据每个对话动作生成信息相关且丰富的话语反馈用户,对话状态跟踪子系统包括多视图卷积组件、多代理强化学习组件以及对话上下文编码器,所述对话策略子系统包括对话上下文编码器、动态图指针联合解码器组件。
3、作为上述方案的改进,将对话历史中的用户话语和系统回复输入对话上下文编码器,得到对话上下文表征矩阵。
4、作为上述方案的改进,根据领域具体槽之间的相似性(领域具体槽之间的槽是否相同,槽相同则为相似领域具体槽,反之为非相似领域具体槽)构建相似领域具体槽图数据以及非相似领域具体槽图数据,通过图卷积网络对图结点进行聚合得到所述领域具体槽第一表征矩阵和所述第二表征矩阵,根据上一轮对话状态动态构建动态槽关联图数据(查看上一轮对话的对话状态中是否有值相同的领域具体槽,有相同的值则它们在所构建的图中存在边的连接),并使用图卷积网络对图结点进行聚合得到领域具体槽第三表征矩阵,将领域具体槽第一表征矩阵、第二表征矩阵和第三表征矩阵按照一定权重相加得到最终的领域具体槽表征矩阵;将最终的领域具体槽表征矩阵与对话上下文表征矩阵做注意力得到每个领域具体槽相关值在对话中的开始位置和结束位置。
5、作为上述方案的改进,单独训练对话状态跟踪模型,使用监督学习预训练模型,随后使用多代理强化学习进一步对模型进行微调,最后得到最终训练好的对话状态跟踪模型,具体为:
6、将模型使用监督学习进行预训练,预训练结束后,随后使用强化学习训练;
7、考虑预测每个领域具体槽在当前对话下的提取值视为局部可观测马尔可夫过程,在每个时刻t,每个代理(领域具体槽)i获得一个本地观测(实质为在步骤1.2中领域具体槽的最终的表征向量),采取一个动作(在当前对话下,为每个领域具体槽选择其值的开始位置和结束位置);
8、根据预测的所述对话动作与真实标签之间的差异程度计算模糊匹配得分,并根据所述模糊匹配得分使用策略梯度微调整个网络。
9、作为上述方案的改进,将对话历史中的用户话语和系统回复以及数据库查询信息输入对话上下文编码器,得到对话上下文表征矩阵。
10、作为上述方案的改进,对话动作解码器解码出每个对话动作生成词,将每个对话动作生成词视为图结点,根据对话动作词的关联性构建成图,使用图卷积网络对图结点进行聚合,得到新的对话动作词嵌入表征矩阵。
11、作为上述方案的改进,将新的对话动作词嵌入表征矩阵与当前系统回复生成词嵌入用自注意力机制得到包含对话动作与系统回复生成词关联的表征向量,用该表征向量预测系统回复下一生成词的概率分布,同时用该表征向量与对话上下文表征矩阵做注意力得到系统回复下一生成词可在对话上下文中复制的概率分布,系统回复解码器用一个分类器判断当前系统回复生成词是从系统与对话上下文提取还是从词库中选择,并解码生成系统回复生成词。
12、作为上述方案的改进,在训练阶段按照一定概率选择老师引导式训练和自引导式训练,若为老师引导式,对话动作解码器和系统回复解码器的输入为数据集标签所给词,若为自引导式则对话动作解码器和系统回复解码器的输入为解码器的上一个预测词;
13、计算对话动作与系统回复的交叉熵损失;
14、为对话动作交叉熵损失和系统回复交叉熵损失设置两个可学习的参数作为损失权重,这两个参数在训练过程中动态调整。
15、本发明具有的有益效果在于:
16、1、本发明包括两个合作模块:多视图图卷积网络和多代理强化学习;多视图图卷积网络用于提取用户与系统对话中的对话状态图结构信息,目的在于有效地学习领域具体槽间的关联;与现有学习领域具体间关联方法相比,本发明提出的多视图有更好的互补性,弥补了当前方法仅学习相似领域具体槽间关联的缺陷;同时本文探索了强化学习在对话状态跟踪任务上的使用,多代理强化学习目的在于进一步训练多视图图卷积网络以提升其学习领域具体槽间关联的能力,和现有方法不同在于本更关注代理之间学习合作,每个领域具体槽在决策时受到其他领域具体槽的影响,它们之间彼此交互学习合作。
17、2、本发明通过将对话动作的预测建模为序列生成任务,对话动作与系统回复协同生成。本发明的方法更关注每个对话动作生成词对系统回复生成的影响,在每回合根据生成的对话动作序列动态构建成图谱以挖掘对话动作间的语义关联,同时利用指针网络由模型自主判断当前系统回复生成词是从系统与用户对话中提取还是从词库中选择,以此让生成的系统回复更流利以及包含更多相关信息。
- 还没有人留言评论。精彩留言会获得点赞!