一种基于可解释模型的文本持续分类方法
本发明涉及一种文本持续分类方法,具体涉及一种基于可解释模型的文本持续分类方法,包括文本分类、可持续学习、可解释学习、经验回放等多方面技术,属于自然处理。
背景技术:
1、目前持续学习技术尚未发展成熟,很多方法的持续学习性能并没有达到预期效果,该领域的研究发展空间巨大,也是促进各种深度学习模型能够更加广泛地应用于实际场景中的重要技术之一。
2、文本分类(text classification,tc)任务,旨在给文本标记预定义的标签,以此判定给定文本的分类类别。该技术是自然语言处理中最重要及最基础的任务之一。目前文本分类技术发展十分成熟,在给定充分标记数据集的监督学习下,其表现十分优异。然而,与大多数基于深度学习的任务类似,传统的模型大多没有持续学习的能力且具有不可解释性。
3、文本持续分类的主要目标是减轻分类器在学习新任务数据时对旧任务知识的遗忘程度,使得分类器在顺序学完新任务后,在新旧任务上的表现都很好。比较典型的持续学习方法是经验回放,也就是在新数据训练时穿插着训练旧任务的数据。目前基于经验回放的持续学习方法回放的都是旧任务的原始样本或用于替代旧样本的生成式伪数据样本。然而,由于回放的数据是少量的,所以如何使得模型通过少量样本回忆旧知识就成为模型能否持续分类的关键。研究表明,当前提出的一些可解释文本分类模型可以在输出解释的同时模型分类准确率,该方法通过找到模型重点关注样本特征,进而通过这些特征提升分类器在数据集上的表现。
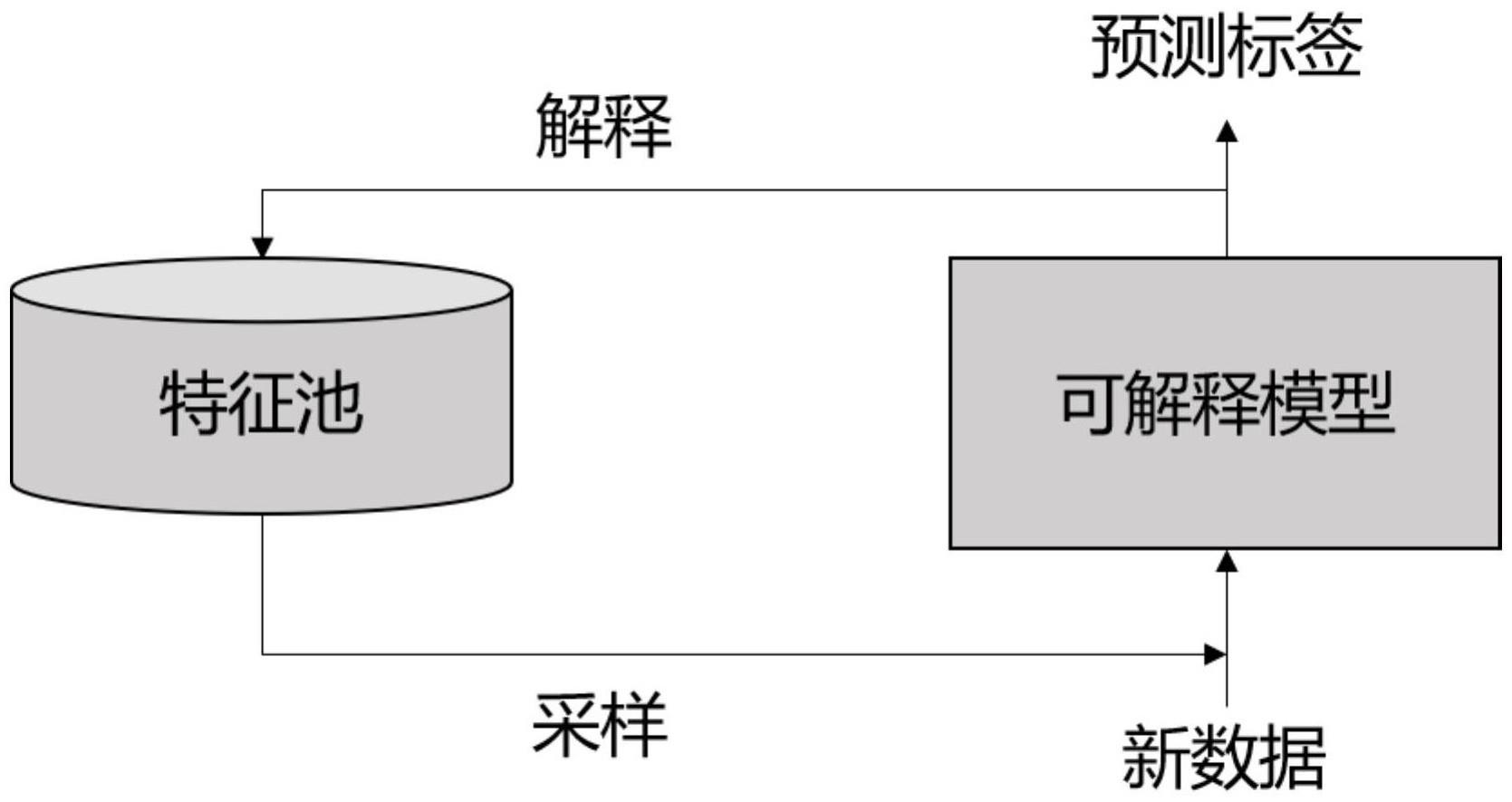
4、因此,本申请提出了一种融合样本特征的的文本持续分类方法。该方法用于优化经验回放方法在文本持续分类方面的表现,通过将可解释属性融入模型,输出的可解释特征作为重要的样本特征放入存储记忆模块,以供后续模型进行回放。值得说明的是,这里回放的是样本特征,而非完整的原始样本,以此来提升分类器对旧任务知识的掌握程度,增强模型的文本持续分类方法。
技术实现思路
1、本发明的目的是针对文本分类的持续学习及可解释性研究两大挑战,打破这两大挑战之间的壁垒,得到一个可解释的文本持续分类模型,同时将可解释文本分类输出的解释作为文本的重要特征,提升文本持续分类的效果,提出一种基于可解释模型的文本持续分类方法。
2、本发明的创新点在于:在文本分类任务中,创造性地将可解释性与持续学习相结合,得到一个在可解释的同时又可以持续分类的模型,同时输出的解释又作为回放的数据来提升持续分类的效果。
3、本发明的目的是通过下述技术方案实现的。
4、定义任务数据顺序输入序列(d0,d1,……dn),设置经验回放频率α,初始化特征池为空。设当前学习任务为di,将任务数据分成m个batch训练,频率α表示当前任务中,每训练α个batch的di数据就回放一批次(batch)的特征数据。
5、一种基于可解释模型的文本持续分类方法,包括以下步骤:
6、步骤1:融合短语结构知识的文本表示输入,按批次(batch)输入,
7、设当前学习的任务为di,若当前任务不是第一个任务(即i不等于0),则此时特征池不为空的前提下,且当前的批次计数为α的倍数,则从特征池中随机抽取1个批次(batch)特征来回放学习,即此时学习的数据为特征池中旧任务的特征;否则输入的就是当前任务的数据。
8、步骤1-1:获取文本编码。
9、使用编码器将输入文本编码为文本表示向量word embeddings。
10、步骤1-2:对新任务的输入进行短语结构信息获取。
11、短语结构信息通过将步骤2-1得到的编码向量利用语法分析解析为短语结构树(如可使用nltk解析器来获取句子对应的短语结构树);若是回放样本则无需进行短语结构信息获取,后续通过步骤3中子树矩阵来统一处理。
12、步骤2:可解释特征提取
13、需要说明的是,只有当前任务数据需要做可解释特征提取以供后续存入数据池中,作为以后任务到来时回放该任务的特征。
14、步骤2-1:短语结构知识与文本向量融合
15、将步骤1得到的输入文本的word embeddings和对应的短语结构树知识进一步融合。
16、需要说明的是,所该输入的样本为特征池中的样本,则直接将短句结构树矩阵设为全1矩阵,即回放的已经是特征,无需再次提取。
17、步骤2-2:解释短语提取
18、根据步骤2-1的融合提取结果计算可解释系数及可解释向量。
19、步骤3:输出解释和预测类别标签
20、根据可解释向量得出类别标签和解释;该解释作为该任务的重要特征数据,存入特征池,以供后续持续分类的回放样本。
21、步骤4:新任务数据获取,继续进行文本持续分类
22、当新的任务数据获得后,重复步骤1-3,进行模型持续分类的过程。
23、有益效果
24、与现有的方法对比,本发明利用可解释模型可以在输出解释的同时可以提升分类效果的优势,将其融入基于经验回放的持续文本分类模型中,得到一个既可解释又可持续学习的文本分类模型。不仅沟通了可解释学习与持续学习研究的桥梁,更使其相辅相成。解决了人们对模型的可解释与持续学习的需求,进一步提升文本分类模型在实际中的应用。
技术特征:
1.一种基于可解释模型的文本持续分类方法,其特征在于包括以下步骤:
技术总结
本发明涉及一种基于可解释模型的文本持续分类方法,包括文本分类、可持续学习、可解释学习、经验回放等多方面技术,属于自然处理技术领域。本发明包括两大部分。第一部分是自解释的文本分类模型,输入样本,输出对应样本的预测类别和可解释词;第二部分为特征池,用以存储自解释模型输出的可解释特征,作为回放的旧任务特征。这里自解释的文本分类模型具体为融合短语结构知识的自解释模型,包含三层,第一层输入层,通过编码器得到文本表示,并进一步得到输入样本对应的短语结构知识。第二层为短语结构知识进一步融合的解释层,第三层为线性层,将解释层的输出映射到类别向量空间,得到预测类别标签和样本的解释。
技术研发人员:张华平,谌立凤,岳远
受保护的技术使用者:北京理工大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!