一种基于层次细粒度分类的图像分类方法
本发明属于细粒度分类、深度学习以及人工智能领域,具体涉及一种基于层次细粒度分类的图像分类方法。
背景技术:
1、图像分类是计算机视觉领域中的一项重要任务,它的目标是将图像分类到预定义的一组类别中。在过去的几十年里,图像分类已经得到了广泛的研究,在很多应用领域中,如动物识别、智能交通以及医疗诊断中都存在图像分类问题。图像分类问题作为一个重要研究内容,目前存在进一步细粒度分类的需求。
2、细粒度分类作为对大类下的子类进行识别的分类任务,其相对于传统图像分类任务的区别和难点在于其图像所属类别的粒度更为精细。例如传统分类任务是将“猫”和“狗”进行分类,而细粒度分类任务在于将该类别下的细粒度子类进行分类,即将“哈士奇”和“柴犬”进行分类,后者的图像特征更为相似,其分类更为困难。细粒度图像分类需要从图像的细微之处中进一步挖掘出足够用于分类的信息,即通过对图像提取定位信息并进行分类,从而提升分类性能。目前已存在一些对图像进行细粒度分类的方法。如基于特征的方法中,其将图像转换为特征向量,然后对特征向量进行分类。这种方法通常需要设计合适的特征提取方法,例如使用卷积神经网络(cnn)提取特征。在基于局部的方法中,其通过将图像分解为不同的部件,更好地理解图像中不同部分之间的关系,然后对每个部件进行分类。
3、但针对细粒度分类,目前已有的方法都存在一些问题和限制,大多数为直接对图像进行细粒度分类,没有逐步定位具有代表性的局部特征来帮助分类器更好地识别细节和差异,这导致分类效果并不能完全令人满意,无法保证可以准确全面的利用关键信息来提高分类性能。
技术实现思路
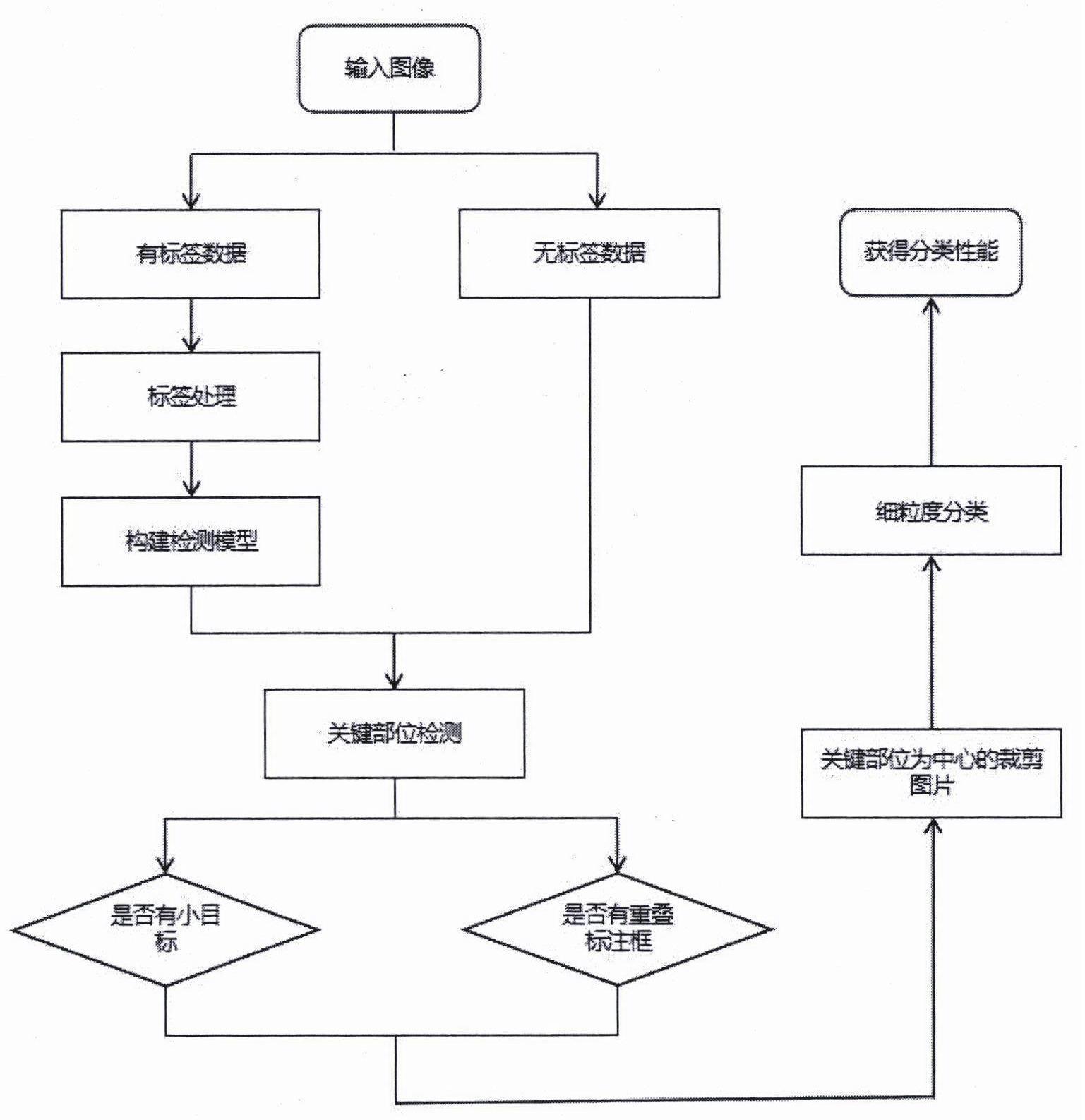
1、基于现有的细粒度分类技术中存在的一些不足与挑战,本发明提供了一种基于层次细粒度分类的图像分类方法,通过两阶段网络的实现,逐步对图像进行精细分类。本发明方法尤其适用于只有少数标注标签样本集的细粒度图像分类。
2、本发明提供的基于层次细粒度分类的图像分类方法,包括以下步骤:
3、步骤1、对少量标注的样本标签进行处理,获取适用于yolov5算法的文本标签,文本标签由类别、标注框的中心点坐标以及标注框的长和宽组成;
4、步骤2、构建检测器,将未标注的图像输入检测器,检测器先使用基于yolov5的检测模型检测输入图像中的目标,剔除面积小于预设值的目标框以及重叠的目标框,最后输出标注了类别和置信度的目标框的图像;
5、步骤3、获得步骤2输出的标注类别的目标框的图像,对每个目标框,从图像中裁剪获得以目标框为中心的固定大小的子图像,子图像包含所识别目标的上下文关系;将子图像输入细粒度分类网络;
6、所述细粒度分类网络使用resnet-50作为预训练模型;细粒度分类网络先使用拼图生成器将输入的子图像按照预设的大中小三种粒度进行分割,再使用预训练模型依次对大中小三种粒度的图像块提取局部特征,再使用预训练模型对输入的子图像提取全局特征;最后将提取的三种局部特征以及全局特征进行拼接融合,输入分类模块,输出子图像对应的细粒度类别。
7、所述的步骤1中,对标签进行转换的方式是:获得图像中的标注框及标签,根据每个标注框的左上角和右下角的图像坐标,计算标注框的中心点坐标、标注框的长和宽,并进行归一化处理。
8、所述的步骤2中,当目标框的面积小于输入图像面积的三百分之一时,认为该目标框为无法提供更多有用价值的小目标,进行剔除。当目标框距离图像边缘小于10像素时,认为该目标框中为太靠近边缘显示不完整的目标,进行剔除。判断目标框为重叠框的依据为依次判断所有目标框的中心点坐标,若二者差距小于设置阈值,则为重叠,保留根据置信度高的目标框。
9、所述的步骤3中,对每个目标框,以目标框为中心从图像中裁剪256*256像素大小的子图像;拼图生成器设置的大中小三种粒度分别为输入子图像的1/4、1/16、1/64。
10、相对于现有技术,本发明方法的优点和有益效果在于:
11、(1)本发明方法所设计的两阶段框架通过构建从“整幅图像->关键部位->精细特征”的过程,从粗到细通过逐层聚焦构建完整的识别框架,从而辨别更加细微的类间差异来提高分类性能。相比直接对整幅图像进行分类,本发明采用逐步精细化的方式,更加充分地利用了图像中的局部特征,提高了分类的准确性和鲁棒性。
12、(2)在实际应用中,图像中关键部位的获取依赖于大量的标记数据,但面对海量图像,需要专家从每张图像中进行标注,这进一步增加了人工标注的负担、难度以及高昂的成本。为此,本发明方法通过训练标注有限的检测模型来进一步识别未被标记的图像中的关键部位,从而能够有效地减少标注数据的需求量,降低标注成本,提高图像分类的效率和可扩展性。
技术特征:
1.一种基于层次细粒度分类的图像分类方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的方法,其特征在于,所述的步骤1中,对标签进行转换的方式是:获得图像中的标注框及标签,根据每个标注框的左上角和右下角的图像坐标,计算标注框的中心点坐标、标注框的长和宽,并进行归一化处理。
3.根据权利要求1所述的方法,其特征在于,所述的步骤2中,将面积小于输入图像面积的三百分之一的目标框进行剔除。
4.根据权利要求1所述的方法,其特征在于,所述的步骤2中,若检测的目标框距离图像边缘小于10像素,则判断该目标框太靠近边缘,剔除该目标框。
5.根据权利要求1或3或4所述的方法,其特征在于,所述的步骤2中,剔除重叠的目标框的方式是:依次对图像中的任意两个目标框的中心点坐标之差的绝对值,与预先设置的阈值m进行比较,若小于m,则判断两目标框重叠,再对比两目标框的分类置信度,剔除置信度低的目标框。
6.根据权利要求1所述的方法,其特征在于,所述的步骤3中,对每个目标框,以目标框为中心,从图像中裁剪256*256像素大小的子图像。
7.根据权利要求1或6所述的方法,其特征在于,所述的步骤3中,拼图生成器设置的大中小三种粒度分别为输入子图像的1/4、1/16、1/64。
8.根据权利要求1或6所述的方法,其特征在于,所述的步骤3中,对细粒度分类网络进行渐进式训练,先使用大粒度的图像块进行训练,再逐步使用中粒度的图像块和小粒度的图像块进行训练,训练时使用的交叉熵损失函数。
技术总结
本发明公开了一种基于层次细粒度分类的图像分类方法,涉及细粒度分类、深度学习技术等。本发明方法包括:对少量标注的样本标签进行处理,获取适用于YOLOv5算法的文本标签;建立基于YOLOv5算法的检测器,检测图像中的目标,剔除面积小于预设值的目标框以及重叠的目标框;以目标框为中心从图像中裁剪固定大小的子图像,子图像包含所识别目标的上下文关系,对子图像输入细粒度分类网络,提取子图像的大中小三种粒度的局部特征和全局特征,进行特征融合后进行细粒度类别分类。本发明实现更全面地利用关键信息和局部特征来提高分类性能,从而能更加准确地捕捉图像中的细节和差异,提高图像细类别的分类性能。
技术研发人员:万玉钗,贾舒琴,李一凡,张珣
受保护的技术使用者:北京工商大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!