基于知识图谱构建答案语义空间的视觉问答方法与流程
本发明涉及计算机视觉、自然语言处理、知识图谱等,主要方法是通过知识图谱中的相关实体节点来增强答案空间中涉及实体的答案的特征表达。该技术可以应用于在线教育、盲人辅助、智能问答等领域,具有很大的商业价值。
背景技术:
1、视觉问答是一项要求在给定问题和图像作为输入的情况下提供文本答案的任务。视觉问答模型需要对图像内容以及问题的高级理解,因此通常被认为是一个允许评估系统视觉推理能力的代理任务。
2、虽然该任务本身需要预测文本输出,即文本答案。文本答案是一个结构丰富的输出空间,但大多数已知的基准和评价原型都将其作为分类问题处理,如vqav1、vqav2、gqa。在之前的方法中,答案词典高度依赖于训练集,不利于对未见数据的泛化,同时,词典的答案类被认为是独立的,没有考虑它们的语义关系。这导致模型高度依赖于问题偏差。
3、同时,在视觉问答任务中大量的问题需要用与图像内容相关的一般性知识进行推理。例如,对于“地面上的红色物体可以用来做什么?”这样的问题?人们不仅需要在视觉上识别红色物体是消火栓,而且要知道消火栓可以用于灭火。wang等人构造了一个基于事实的vqa数据集fvqa,fvqa中的问题需要借助外部知识来回答。wang等人还提出了一种新的vqa方法,该方法可以从大型结构化知识库中自动找到支持可视化问题的事实,如conceptnet和dbpedia。该方法不是直接学习从问题到答案的映射,而是学习从问题到知识库查询的映射。wen和peng等人提出了基于常识知识的推理模型,该模型通过获取外部知识支持视觉常识推理任务。除此之外,利用外部知识的视觉问答方法还有很多,但是当前的一些基于外部知识的视觉问答方法,并没有考虑在数据集中答案集合中所包含的外部知识。
4、综上所述,在现有的视觉问答任务中,如何充分利用答案所包含的外部知识以及如何利用类似答案直接的语义关联性,仍是迫切需要解决的问题。
技术实现思路
1、1、一种基于知识图谱参与构建答案语义空间的视觉问答方法,其特征在于,
2、包括以下步骤:
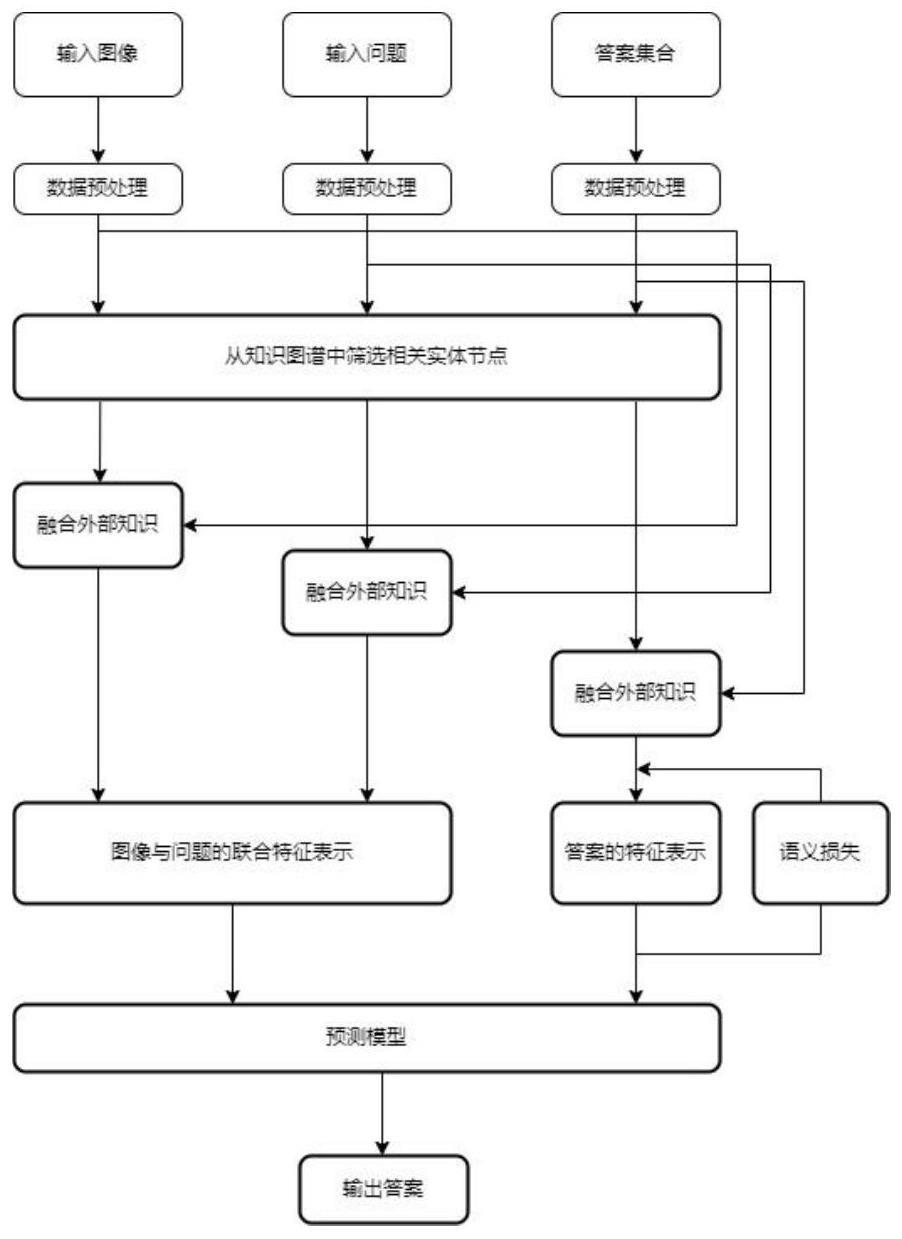
3、步骤1.1:从外部大规模知识图谱中提取问题和图像上下文相关的实体节点,分别嵌入图像特征和问题的文本特征,得到外部知识嵌入的图像特征vk和外部知识嵌入的问题特征qk。
4、步骤1.2:将vk,qk输入多模态双线性池化网络,去掉最后的softmax分类层,取最后一层的状态fθ(vk,qk),作为图像和问题的联合特征,其中θ为双线性池化模型的参数。
5、步骤1.3:从外部大规模知识图谱中筛选出与答案相关的实体节点,保留知识图谱中相关程度最高的实体节点用以嵌入答案特征表达从而生成外部知识嵌入的答案特征表达gφ(a)。
6、步骤1.4:将步骤1.2和步骤1.3得到的图像和问题的联合特征fθ(vk,qk)和外部知识嵌入的答案特征表达gφ(a)投射到同一个答案语义空间之中进行学习。
7、步骤1.5:给定输入图像和问题,模型通过以下公式预测答案:
8、
9、其中a*代表预测得出的答案。
10、2、根据权利要求1所述的一种基于知识图谱与答案语义嵌入的视觉问答方法,其特征在于,所述步骤1.1中将相关外部知识分别嵌入文本和图像的方法如下:
11、步骤2.1:使用在visual genome数据集上预训练好的目标检测网络处理入图像,得到视觉特征其中nv=18,vi代表检测框中物体的特征,同时,每个检测框还得到5维的检测框特征dv和检测到的实体名称检测框特征包含检测框上下左右四个角的坐标以及检测框的置信度。图像中涉及的实体集合其中vn为检测到的实体个数。
12、步骤2.2:用glove词嵌入表示输入问题中的每个单词,每个单词用1024维的词嵌入表示,然后输入到长短期记忆网络中得到问题的整体文本特征表示
13、步骤2.3:通过斯坦福命名实体识别对问题进行分析,得到问题中涉及的实体集合其中qn为检测到的实体个数。
14、步骤2.4:从大规模知识图谱conceptnet中通过计算余弦相似度筛选出图像中出现的实体和问题相关的实体得到最关联实体节点ek∈e,其中e代表实体节点的集合。以实体节点ek为起点,将ek展开到其二阶领域,保留领域实体和边,最终构成图像和问题上下文相关的知识图谱,所有的实体名称以glove词嵌入作为特征。通过rgcn处理得到的知识图谱,在经过图神经网络多轮迭代后,得到更新后的与图像和问题上下文相关的实体节点特征表示
15、步骤2.5:将步骤2.4中得到的最终的实体节点特征分别嵌入图像特征和问题的文本特征,得到包含外部知识信息的图像特征vk和包含外部知识信息的图像特征qk用于下游多模态特征融合任务。
16、3、根据权利要求2中步骤2.5所述的将外部知识分别嵌入文本和图像,其特征在于,所述嵌入方法具体步骤如下:
17、步骤3.1:对于目标检测网络检测到的每一个实体,将其视觉特征vi与知识图谱中对应的实体节点特征进行拼接得到外部知识嵌入得视觉特征,即每个视觉特征总体的输入图像特征在嵌入外部知识后表示为vk。
18、步骤3.2:将问题中检测到的实体节点特征作为辅助特征拼接在问题特征之后,得到外部知识嵌入的问题特征表达然后qk将输入一个多层感知机,得到外部知识嵌入的问题特征qk。
19、4、根据权利要求1所述的一种基于知识图谱构建答案语义空间的视觉问答方法,其特征在于,所述步骤1.3将外部包含知识信息的实体节点嵌入答案特征的方法如下:
20、步骤4.1:将视觉问答中的出现概率最高的前3500个答案标签建模为实体ea,从大规模知识图谱中通过计算余弦相似度筛选出与答案实体相关的实体,所有的实体名称以glove词嵌入作为特征,将这些实体展开到其二阶领域,保留领域实体和边,最终构成答案上下文相关的知识图谱。
21、步骤4.2:在经过rgcn多轮迭代后,各答案相关的实体节点聚合周边节点知识信息得到更新后的实体节点特征表示
22、步骤4.3:若答案的标签与实体名称一致,则直接将知识图谱中的实体建模为答案集合中的元素。若答案标签包含实体名称以外的单词,则将答案相关的实体特征拼接在答案标签的文本特征之后得到新的答案特征作为答案集合中的元素。
23、5、根据权利要求1所述的一种基于知识图谱与答案语义嵌入的视觉问答方法,其特征在于,所述步骤1.4中将fθ(vk,qk)和gφ(a)投射到答案语义空间中学习的方法如下:
24、步骤5.1:将步骤4.3中得到的答案集合中的每一个元素输入一个lstm神经网络,取lstm网络隐层的最后一层作为答案的表示特征其中为lstm网络的参数。
25、步骤5.2:将特征fθ(vk,qk)和投射到同一个答案语义空间之中进行学习,在神经网络训练过程中,通过优化模型使fθ(vk,qk)和在一个公共的特征空间之中相互接近,其中a为所有答案的集合。训练过程中的损失函数为:
26、
27、其中i(a,b)是一个二元指示函数,当a=b为真时,取1,否则为0。
28、步骤5.3:为了惩罚语义临近的预测和目标之间的分类失误,定义语义损失函数如下:
29、
30、其中s表示相似度计算函数,最终,在训练过程中模型的整体损失函数为:
31、
32、其中,λ为一个预定义的超参数。
33、本发明的有益结果:本发明结合知识图谱和图卷积的相关技术,提出了一种构建答案语义空间的解决方案,极大地提高了数据集中答案信息对视觉问答任务的积极作用。
- 还没有人留言评论。精彩留言会获得点赞!