换道决策网络的训练方法、装置、计算机设备及存储介质与流程
本公开涉及换道决策网络的训练,具体而言,涉及一种换道决策网络的训练方法、装置、计算机设备及存储介质。
背景技术:
1、随着自动驾驶技术的快速发展,越来越多的自动驾驶车辆出现在人们的日常生活中。在进行自动驾驶的过程中,车辆的决策模块可以根据车辆在行驶过程中感知的环境信息,确定出自动驾驶的行驶轨迹,从而可以在合适的时间和位置发起换道。
2、相关技术中,往往是由训练好的神经网络根据输入的换道场景信息(即车辆周围的环境信息),输出包含合适的时间和位置发起换道的换道策略,但由于换道场景的数量较多,需要在训练过程中分为多个训练阶段对神经网络进行训练,而随着训练的逐步进行往往会使得神经网络逐渐遗忘之前训练阶段时掌握的相关决策能力,从而使得神经网络的网络精度有待提高。
技术实现思路
1、本公开实施例至少提供一种换道决策网络的训练方法、装置、计算机设备及存储介质。
2、第一方面,本公开实施例提供了一种换道决策网络的训练方法,包括:
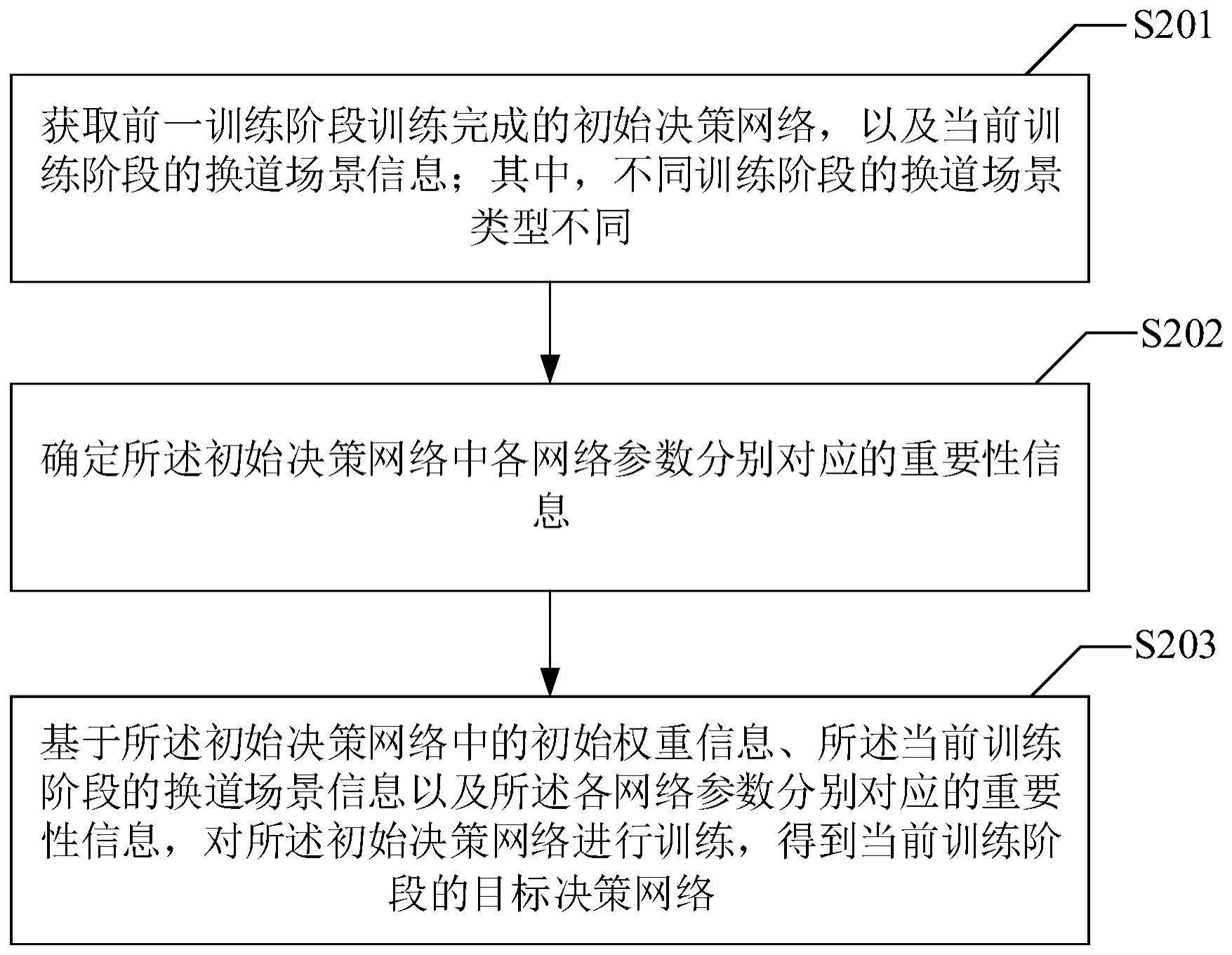
3、获取前一训练阶段训练完成的初始决策网络,以及当前训练阶段的换道场景信息;其中,不同训练阶段的换道场景类型不同;
4、确定所述初始决策网络中各网络参数分别对应的重要性信息;
5、基于所述初始决策网络中的初始权重信息、所述当前训练阶段的换道场景信息以及所述各网络参数分别对应的重要性信息,对所述初始决策网络进行训练,得到当前训练阶段的目标决策网络。
6、一种可能的实施方式中,所述确定所述初始决策网络中各网络参数分别对应的重要性信息,包括:
7、针对所述前一训练阶段训练完成的初始决策网络,提取所述初始决策网络对应的费歇耳信息矩阵;其中,所述费歇耳信息矩阵用于表征所述初始决策网络中各网络参数分别对应的重要性。
8、一种可能的实施方式中,所述基于所述初始决策网络中的初始权重信息、所述当前训练阶段的换道场景信息以及所述各网络参数分别对应的重要性信息,对所述初始决策网络进行训练,得到当前训练阶段的决策网络,包括:
9、针对训练过程中的任一次网络参数调整,基于所述初始权重信息和所述各网络参数分别对应的重要性信息,确定该次网络参数调整过程中各网络参数分别对应的更新后的参数值;
10、基于各网络参数分别对应的更新后的参数值和所述当前训练阶段的换道场景信息,确定用于训练所述当前训练阶段的决策网络的目标损失值,并基于所述目标损失值对所述初始决策网络进行训练,得到当前训练阶段的决策网络。
11、一种可能的实施方式中,所述基于所述初始权重信息和所述各网络参数分别对应的重要性信息,确定该次网络参数调整过程中各网络参数分别对应的更新后的参数值,包括:
12、基于各网络参数分别对应的重要性信息,以及待调整的所述当前训练阶段的网络参数的参数值与所述初始权重信息之间的差值,确定各网络参数分别对应的权重调整值;
13、基于各网络参数分别对应的权重调整值对所述初始权重信息进行调整,得到该次网络参数调整过程中各网络参数分别对应的更新后的参数值。
14、一种可能的实施方式中,所述基于各网络参数分别对应的更新后的参数值和所述当前训练阶段的换道场景信息,确定用于训练所述当前训练阶段的决策网络的目标损失值,包括:
15、基于各网络参数分别对应的更新后的参数值和所述当前训练阶段的换道场景信息,确定更新参数值后的决策网络针对所述当前训练阶段的换道场景信息输出的第一样本决策结果;
16、基于所述第一样本决策结果和所述当前训练阶段的换道场景信息对应的换道策略,确定用于训练所述当前训练阶段的决策网络的目标损失值。
17、一种可能的实施方式中,所述获取前一训练阶段训练完成的初始决策网络,以及当前训练阶段的换道场景信息,包括:
18、在检测到满足预设的换道场景训练条件的情况下,获取前一训练阶段训练完成的初始决策网络,以及当前训练阶段的换道场景信息,其中,所述换道场景训练条件包括检测到新的换道场景类型的数量达到预设数量。
19、一种可能的实施方式中,所述基于各网络参数分别对应的更新后的参数值和所述当前训练阶段的换道场景信息,确定用于训练所述当前训练阶段的决策网络的目标损失值,包括:
20、基于各网络参数分别对应的更新后的参数值、所述当前训练阶段的换道场景信息以及所述前一训练阶段的换道场景信息,确定更新参数值后的决策网络针对所述当前训练阶段和所述前一训练阶段的换道场景信息输出的第二样本决策结果;
21、基于所述第二样本决策结果、所述当前训练阶段的换道场景信息对应的换道策略以及所述前一训练阶段的换道场景信息对应的换道策略,确定用于训练所述当前训练阶段的决策网络的目标损失值。
22、第二方面,本公开实施例还提供一种车辆控制方法,包括:
23、获取待检测场景信息;
24、基于预先训练的目标决策网络和所述待检测场景信息,确定目标换道策略,并按照所述目标换道策略进行车辆控制;
25、其中,所述目标决策网络是基于多轮训练阶段训练完成的,不同训练阶段的换道场景类型不同,任一训练阶段的初始决策网络是在前一轮训练完成的初始决策网络的基础上,结合前一轮训练完成的初始决策网络中各网络参数分别对应的重要性信息训练得到的,第一训练阶段的初始决策网络是基于第一训练阶段的样本场景信息训练得到的。
26、第三方面,本公开实施例还提供一种换道决策网络的训练装置,包括:
27、获取模块,用于获取前一训练阶段训练完成的初始决策网络,以及当前训练阶段的换道场景信息;其中,不同训练阶段的换道场景类型不同;
28、确定模块,用于确定所述初始决策网络中各网络参数分别对应的重要性信息;
29、训练模块,用于基于所述初始决策网络中的初始权重信息、所述当前训练阶段的换道场景信息以及所述各网络参数分别对应的重要性信息,对所述初始决策网络进行训练,得到当前训练阶段的目标决策网络。
30、第四方面,本公开可选实现方式还提供一种计算机程序产品,包括计算机程序,当所述计算机程序被执行时实现如第一方面和/或第二方面所述的方法。
31、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,而非限制本公开的技术方案。
32、本公开实施例提供的换道决策网络的训练方法、装置、计算机设备及存储介质,在当前训练阶段的训练过程中,可以确定出前一训练阶段训练得到的初始决策网络中各网络参数分别对应的重要性信息,从而可以根据所述初始决策网络中的初始权重信息、所述当前训练阶段的换道场景信息以及所述各网络参数分别对应的重要性信息,对所述初始决策网络进行训练,得到当前训练阶段的目标决策网络。这样,由于在训练当前阶段的决策网络的过程中,添加了针对前一训练阶段训练后得到的初始决策网络中各网络参数分别对应的重要性信息,从而可以保留前一训练阶段训练的初始决策网络中较为重要的网络参数,避免在对训练过程中使决策网络遗忘前一训练阶段得到的相关能力,使得经过当前训练阶段后得到的目标决策网络能够同时包含所述初始决策网络对应的决策能力,以及经过当前训练阶段后掌握的新的决策能力,提高了目标决策网络的网络精度。
33、为使本公开的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。
- 还没有人留言评论。精彩留言会获得点赞!