移动场景下基于视频生成毫米波雷达数据的方法及装置
本发明涉及毫米波雷达移动感知,尤其涉及一种移动场景下基于视频生成毫米波雷达数据的方法及装置。
背景技术:
1、毫米波雷达作为一种新的、有前景的感知模态引起了人们越来越多的关注。毫米波雷达对障碍物有良好的穿透能力,具有应对恶劣条件的能力,同时不会暴露用户的外貌特征,支持鲁棒的、隐私保护的人体感知。
2、基于这些特点,毫米波雷达存在两个典型的应用。一是动作识别,例如:(1)使用移动机器人识别人体动作进而辅助独居老人,(2)允许无人机根据识别的人体动作跟拍用户;二是目标检测,例如:(1)火灾时根据移动机器人检测到的人员执行紧急救援任务,(2)移动机器人夜间检测建筑物内非法入侵者并进行智能报警操作。
3、然而,现有的动态雷达数据集,通常是针对具体任务进行定制的,且相应的规模较小,这就使得深度学习模型的潜力难以被挖掘,无法实现高泛化性和鲁棒性。同时,收集和标注雷达数据也是非常耗时耗力的工作,这也限制了毫米波雷达数据集大规模的扩充。
4、为了扩充毫米波雷达数据集,目前一些方法已经利用运动捕捉数据、深度相机数据和视频数据等数据源生成了其他类型数据,例如惯性测量单元数据、声音数据和毫米波雷达数据。但是,基于运动捕捉数据生成的毫米波雷达数据通常是稀疏和粗糙的。基于深度相机数据生成的毫米波雷达数据通常会缺失一些场景的动作,并不能覆盖人类的日常行为。利用生成对抗网络来增强真实毫米波雷达数据的方法,其得到的雷达数据针对一些相似的动作容易出现混淆现象。最近,出现了基于视频生成毫米波雷达数据的方法,但是该方法仍然存在以下的局限性:(1)现有方法依赖于深度图,不能准确估计出人和相机的相对位置;同时动态视频数据会出现运动模糊和抖动现象,进一步限制了人体网格的提取精度,从而导致生成的强度信号存在严重的错误叠加;(2)现有方法当背景中有运动或传感器本身在运动时,系统会失效。因此,利用大规模动态视频数据来解决动态毫米波雷达数据缺乏的问题依然是个挑战。
技术实现思路
1、本发明针对目前移动场景下毫米波雷达感知数据缺乏的问题,目的是设计一种移动场景下基于视频生成毫米波雷达数据的方法及装置,将动态视频数据作为输入生成对应场景下的动态毫米波雷达数据,有效扩充了毫米波雷达数据集,降低雷达数据的采集成本,并支持移动场景细下毫米波雷达在人体感知领域的进一步拓展与应用。
2、为了实现上述目的,本发明提供如下技术方案:
3、一方面,本发明提供一种移动场景下基于视频生成毫米波雷达数据的方法,包括如下步骤:
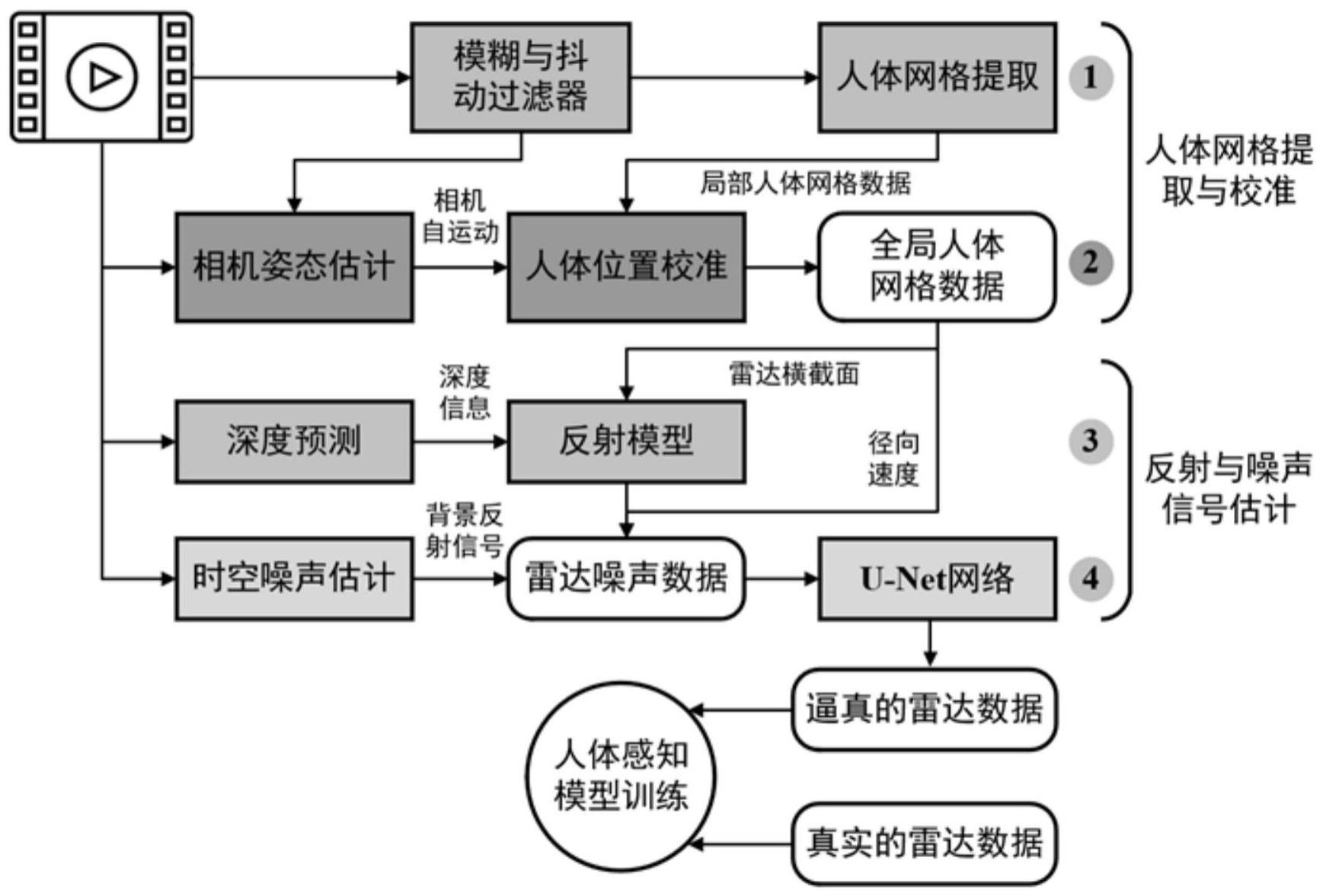
4、s1、使用模糊和抖动过滤器对动态视频数据进行噪声过滤,基于处理后的视频,使用人体网格提取算法提取出相对于相机坐标系下的人体网格数据;
5、s2、使用相机姿态估计算法把背景和获得的相机运动真实值作为输入来估计相机自我运动状态参数,基于相机自我运动状态参数和局部人体网络数据进行人体位置校准,输出全局人体网格数据;
6、s3、使用深度预测模型估计出动态视频数据中人体的深度信息,基于人体的深度信息,利用全局人体网格数据计算出人体顶点的雷达横截面,通过每个顶点的先前帧位置来计算人体表面径向速度;使用反射模型将深度信息和雷达横截面作为输入来模拟雷达信号的多径反射与衰减,并输出强度图;
7、s4、使用时空噪声估计算法从时间和空间维度上对动态视频数据的反射信号和背景噪声进行估计,输出背景反射噪声;拼接强度图、背景反射噪声和人体表面径向速度来获取粗粒度的雷达数据,采用u-net网络拟合出逼真的毫米波雷达数据。
8、进一步地,步骤s1中,所述的模糊和抖动过滤器,采用具有并行帧预测和长期时序依赖建模能力的视频恢复转换器来进行视频噪声过滤,同时采用将邻域运动感知局部模型和正则化模型结合的方法来求解不同运动状态的最优扭曲变换。
9、进一步地,步骤s1中,所述的人体网格数据包括人体的姿势和形状以及相对深度,其中,人体姿势和形状是由若干个人体表面三维点云构成,相对深度描述了每个人距离摄像头的距离。
10、进一步地,步骤s2中,所述的相机姿态估计算法,对视频中的人进行了剔除,利用连续帧之间的背景和真实值作为输入来获取准确的相机自我运动状态参数。
11、进一步地,步骤s2中,人体位置校准的过程为:基于相机自我运动状态参数,得出相机相对于人的真实位置;人体网格数据的平移和旋转估计序列表示相机自运动结果;随后集成相机自我运动参数和位置校准,以完成在连续帧中对人体位置的校准;最后人体位置校准对局部人体网格数据进行位置校准,推断出人在真实世界坐标系下的位置信息,生成全局的人体网格数据。
12、进一步地,步骤s3中,所述的深度预测模型将人体不同部位的深度值求平均值来确定用户的深度信息。
13、进一步地,步骤s3中,所述的反射模型添加了多个虚拟目标,并设置相应的衰减系数来模拟真实的信号衰减现象。
14、进一步地,步骤s4中,所述的时空噪声估计算法,从时间和空间维度上对背景噪声进行估计;其中,对于空间部分,采用实例分割网络对单帧图像中的背景和人进行分割,随后剔除视频中的人而保留背景用于接下来的噪声模拟;对于时间部分,使用光流网络获取连续帧之间的位移向量,从而计算出帧中任意目标的速度;接下来将速度映射到空间部分得到的分割结果上,获得背景在时空上的表征形式,从而模拟出背景的噪声特性,生成背景反射噪声。
15、进一步地,步骤s4中,所述的u-net网络由特征提取网络和特征融合网络组成,其中特征提取网络由卷积和下采样组成,所用的卷积结构统一为3×3的卷积核。
16、另一方面,本发明还提供了一种移动场景下基于视频生成毫米波雷达数据的装置,包括以下组件以实现上述任一项所述的移动场景下基于视频生成毫米波雷达数据的方法:
17、模糊和抖动过滤器,用于对动态视频数据进行噪声过滤;
18、人体网格提取模块,基于处理后的视频提取出相对于相机坐标系下的人体网格数据;
19、相机姿态估计模块,用于把背景和获得的相机运动真实值作为输入来估计相机自我运动状态参数;
20、人体位置校准模块,基于相机自我运动状态参数和局部人体网络数据进行人体位置校准,输出全局人体网格数据;
21、深度预测模型,用于估计出动态视频数据中人体的深度信息;
22、反射模型,基于人体的深度信息,利用全局人体网格数据计算出人体顶点的雷达横截面,通过每个顶点的先前帧位置来计算人体表面径向速度;将深度信息和雷达横截面作为输入来模拟雷达信号的多径反射与衰减,并输出强度图;
23、时空噪声估计模块,用于从时间和空间维度上对动态视频数据的反射信号和背景噪声进行估计,输出背景反射噪声;拼接强度图、背景反射噪声和人体表面径向速度来获取粗粒度的雷达数据;
24、u-net网络模块,用于将粗粒度的雷达数据拟合出逼真的毫米波雷达数据。
25、与现有技术相比,本发明的有益效果为:
26、1、本发明提出的移动场景下基于视频生成毫米波雷达数据的方法及装置,首次利用丰富的动态视频数据生成大量逼真的、可转换的动态毫米波雷达数据,包括多普勒数据和点云数据,有效解决了移动场景中毫米波雷达数据不足的问题,可应用于动作识别、目标检测等应用中。
27、2、本发明通过相机姿态估计算法把背景和获得的相机运动真实值作为输入来估计相机自我运动,再基于相机自我运动参数来校准人的真实位置,随后集成自我运动参数和位置校准,解决了动态场景中人在连续帧之间的相对位置会存在偏差的问题,进而解决了相机自我运动估计和人体网格数据不准确问题。
28、3、本发明通过深度预测模型来获取人体的深度信息,并通过反射模型将深度信息和雷达的横截面作为输入来模拟雷达信号在发射和接收过程中的传播特性,解决了移动场景中背景和人的反射特征难模拟问题。
- 还没有人留言评论。精彩留言会获得点赞!