一种基于差异化隐私泄露风险的数据商品动态定价方法
本发明属于数据共享领域,涉及一种基于差异化隐私泄露风险的数据商品动态定价方法。
背景技术:
1、当今社会,个人数据作为包含用户隐私信息的一种重要资产,已被广泛应用于征信系统、商品推荐、健康评估等领域,具有巨大的商业价值。这使得个人数据逐渐成为一种可交易的商品,对于想要利用这些数据来进行分析并提供商业服务的企业来说,个人数据具有重要价值,可以提高企业的竞争力。然而,大多数企业很难合法地获取足够的个人数据,因此需要向数据交易平台购买满足其需求的个人数据。
2、尽管企业渴望利用个人数据进行研究和商业活动,但这些数据都来自于数据拥有者,反映了每个人的独特属性和身份。因此,作为数据拥有者的企业或个人会考虑到提供个人数据给企业的隐私风险和利益等问题。这导致获取个人数据变得十分困难,即使企业向数据拥有者提供免费服务,数据拥有者也不愿意免费提供数据。在这种供需关系下,个人数据交易的概念应运而生。个人数据交易是指数据拥有者将数据出售给其他企业或个人获得报酬的过程。其可以为数据拥有者带来经济利益,同时也能够为数据买方提供更精准的服务和产品。
3、数据定价是个人数据交易的重要组成部分,即为数据确定一个价格。将数据视为一种可以自由交易的商品可以提高数据的市场流动性,从而创造更大的价值。在数据定价过程中,除了需要考虑交易双方的收益最大化和公平等问题,还需要考虑个人数据拥有方隐私泄露风险的问题。个人数据并不是相互独立的数据,存在属性关联。在不同的交易方式下,对于数据拥有者造成的隐私泄露风险程度也不同。例如,如果数据拥有者拥有多份属性数据,考虑两种售卖方式,一种是将其中两份数据售卖给同一个数据买家,另一种是将这两份数据分别出售给不同的两个买家。由于数据之间存在属性关联,数据买家购买的数据越多,拥有的背景知识越多,也就越容易推断出数据拥有者尚未出售的数据,这两种售卖方式对数据拥有者造成的隐私泄露风险程度也不同。因此,在数据定价过程中,需要考虑数据拥有者的心理价位和隐私泄露风险,对未出售数据进行动态的差异化定价是数据定价过程中的一个重要挑战。
4、目前的研究更关注于数据本身的隐私问题,例如通过差分隐私的方法对数据进行隐私保护,并根据隐私损失对数据所有者进行价格补偿。然而,这些研究并没有考虑到在数据出售过程中隐私泄露风险的动态变化问题。
技术实现思路
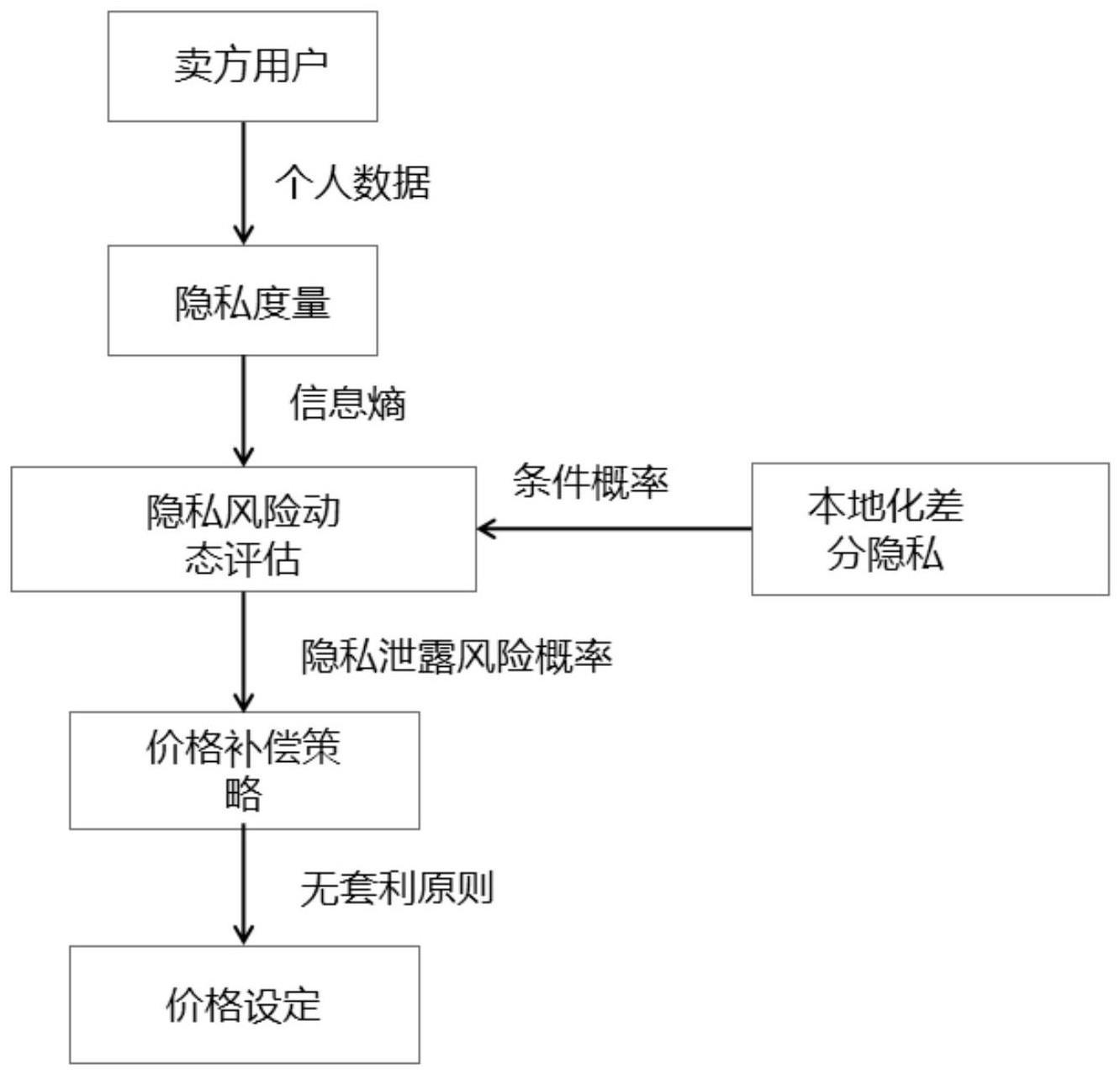
1、有鉴于此,本发明的目的在于提供一种基于隐私泄露风险的差异化数据商品动态定价机制。设计个人数据隐私泄露风险动态评估方法,分析数据之间的隐私关联等因素,结合信息熵、条件熵、互信息等理论,构建自定义隐私泄露风险动态概率;对多个数据集进行采样,从而收集数据进行属性之间条件概率的计算,使用本地化差分隐私技术保护数据;结合无套利原则等定价理论以及隐私风险泄露概率,设计差异化动态定价方式以出售数据。
2、为达到上述目的,本发明提供如下技术方案:
3、一种基于差异化隐私泄露风险的数据商品动态定价方法,包括以下步骤:
4、s1:构造数据属性矩阵,数据所有者使用本地化差分隐私对属性数据进行扰动,并上传至中心节点计算条件概率;
5、s2:数据所有者分析数据之间的隐私关联,基于信息熵理论计算自定义隐私泄露风险动态概率;
6、s3:基于隐私泄露风险动态评估系数设计定价策略,结合无套利等定价基础理论定价。
7、进一步,步骤s1具体包括以下步骤:
8、s11:设存在n个数据拥有者用户,x={x1,x2,...,xn},表示n个数据拥有者所拥有的数据集合,xi表示来自第i个数据拥有者用户的数据记录;数据拥有者的每条数据记录具有d维属性,设d维属性a={a1,a2,...,ad},其中每个数据记录xi表示为其中表示第i个数据拥有者的第j个属性的记录;对于某一个用户的一条记录的属性集合aj,j=1,2,...,d,设置每个属性的值域其中表示一个属性中的一个变量,|ωj|表示该属性中能取的变量个数;
9、s12:对数据拥有者的数据进行本地化差分隐私;设第i个数据拥有者拥有的数据为对其中的进行编码:
10、
11、其中,构造一个编码长度mj=|ωj|的零向量b,编码的方式是将对应的位置设置为1,其他位为0;随后对其中每一位进行扰动,扰动概率如下:
12、
13、其中,给定p和q,以概率p和q对编码向量中的每一位进行随机响应扰动,该扰动方法满足于ε-ldp:
14、
15、s13:数据拥有者xi将每个属性的编码扰动后进行合并,形成一个长度为的向量,即编码扰动后的数据,中心节点随后收集多个数据拥有者的数据并使用lasso回归方法来推导数据属性的联合分布概率。
16、进一步,步骤s13所述使用lasso回归方法来推导数据属性的联合分布概率,具体包括:
17、首先构建候选矩阵mt×r,表示d维属性编码后的位长,表示候选值的总数,将d维属性联合分布为一个向量p=(p1,p2,...,pr);将编码扰动后的每一位求和并校正,得到计数向量c=(c1,c2,...,ct),联合分布估计通过lasso得到:
18、p=lasso regression(m,ct)
19、将扰动后的编码生成一个近似与原始属性数据的分布:
20、
21、px(a1,a2...ad)被定义为i∈{1,2,...,n},ω1∈ω1,...,ωd∈ωd,ωj表示在一个属性域中的具体的属性值,通过联合分布结合属性的边缘分布得到条件概率。
22、进一步,步骤s2具体包括以下步骤:
23、s21:假设一个n×d属性数据集t,n表示数据集中的个体用户数量,d表示属性的数量,表示第i个用户的第j个属性,其中i∈{1,2,...,n},j∈{1,2,...,d};数据商品集合为x={x1,x2,...,xd},其中xi表示结合中的第i个属性集合;
24、s22:利用信息熵理论构建待交易属性数据集的自信息:
25、
26、其中p(xi)表示属性值在属性域中的出现概率;h(x)描述为待出售属性数据的不确定程度,h(x)越大,数据的不确定程度越高,隐私风险泄露程度越小;
27、s23:在数据商品交易发生后,设原数据商品集合中的属性被卖出了h份,记为y={y1,y2,...,yh},在数据交易过程中,待出售数据的信息量发生改变,利用条件熵来刻画:
28、
29、条件熵h(x/y)表示在数据售卖过程中,h(x)所保留的不确定程度;
30、s24:互信息表示用户出售数据给原始的隐私信息量带来的损失,用来表示用户出售数据后,随着出售数据数量上的动态变化,用户隐私的不确定程度以及隐私泄露程度发生变化的情况,互信息由自信息和条件熵求得:
31、i(x;y)=h(x)-h(x/y)
32、引入平均隐私加权交互信息量i(x;y)来刻画出售过程中的隐私泄露风险,定义为
33、
34、i(x;y)表示数据出售前用户数据x和数据出售后用户数据y之间交互的平均信息量,即在交易过程中传播的隐私信息量,将i(x;y)视为隐私泄露风险动态评估系数,即i(x;y)越大,隐私泄露风险越高;
35、定义动态隐私风险泄露概率p(x;y):
36、
37、动态隐私风险泄露概率p(x;y)能够直观地刻画数据交易过程中数据拥有者的隐私泄露风险。
38、进一步,步骤s3中,基于动态补偿方案的定价设定方案π(y)为:
39、
40、其中α是补偿系数,为一个常数,根据数据属性类型进行设置,θj∈{θ1,θ2,...,θh},是数据出售的初始单价,θj根据属性数据的成本、重要性以及数据质量设定;并且,π(y)需要满足套利规避:
41、若{y1,y2,...yh}→y,
42、则
43、其中,表示进行一系列购买的定价,π(y)表示一次性购买的定价。
44、本发明的有益效果在于:本发明解决了在数据交易过程中不同的交易方式导致的动态隐私泄露问题,本发明结合信息熵理论,构建自定义隐私泄露风险动态概率,以量化个人数据的隐私和交易过程中的隐私泄露风险,采用本地差分隐私对计算数据商品之间的条件概率时采样的大量个人数据进行了隐私保护,最后,利用无套利定价原则,对数据商品进行合理定价。
45、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
- 还没有人留言评论。精彩留言会获得点赞!