一种基于元认知的面向群体协作的个性化角色定位方法
本发明涉及群体元认知,尤其是一种基于元认知的面向群体协作的个性化角色定位方法。
背景技术:
1、元认知(metacognition)是对认知的认知,基本功能是监测和调控认知。元认知不仅对于个体学习起着作用,帮助学习者提高学习能力、走出负面情绪,它还会影响学习者在群体协作中的表现。
2、群体过程的元认知是全局特征,而不是单个方面的总和。群体协作时会产生群体元认知,彼此监督,思想碰撞引发重新思考。现阶段对于群体元认知的研究发现,可能对群体元认知造成负面影响的主要因素有:不匹配、地位影响、沟通不足和文化差异。在现实的团队协作场景中,当团队成员已经确定的情况下,地位、沟通和文化差异较难改变。此时可以通过为每位成员分配相应的角色来增强群体元认知,提升团队协作表现。
3、近期,在以教育为背景的研究里,在协作问题解决的过程中利用教育聊天机器人提供了不同水平的元认知支架。研究发现,通过聊天机器人在不同阶段提出问题进行干预,实验组成员的决策能力和团队的协作表现都有显著提升。随后,尝试了撤销聊天机器人提供的元认知支架干预后,从实验组中人为随机选择一位学习者模仿聊天机器人的工作在新任务中提供元认知支架。结果显示尽管群体协作表现和成员决策能力仍有一定程度的提升,但提升并未达到聊天机器人干预时的高度。分析其原因得出,人为随机指派的学习者并不一定适合担当聊天机器人所扮演的角色。
4、现有技术的个性化角色定位,单个成员无法替代聊天机器人提供的元认知支架,而且在群体协作的不同阶段,也需要由不同的角色来提供元认知支架,比如在问题识别阶段需要计划员,而在探索阶段需要监督员等,可见并非一人就能胜任。在团队协作中,每个人都在被动扮演着或者必须扮演着一个或多个角色,每个角色都有其不同的特点和功用,角色之间的合理调配和运用则是高绩效团队的重要基础。故对于既定的项目,找出能推动协作的关键角色是至关重要的。
技术实现思路
1、本发明的目的是针对现有技术的不足而提供的一种基于元认知的面向群体协作的个性化角色定位方法,采用元认知策略理论建立角色库与场景库,根据不同场景为角色赋予不同的权重,对于待分配角色的目标团队,基于认知水平生成成员的元认知能力嵌入,结合心理学与教育学理论生成成员画像,最后依据任务场景与元认知的关系建立角色与成员的匹配模型,为成员匹配最合适的角色。该方法进一步研究基于元认知、性格与能力的角色定位算法,利用聊天机器人为每位成员分配最合适的角色,使成员们更好地学会在群体协作中运用合理的元认知支架自己提出个性化的提示问题,并逐渐达成群体决策共识,有效解决了在意图增强群体元认知的研究中,单个成员无法替代聊天机器人提供的元认知支架问题。方法简便,具有有效性,能够优化群体协作表现,提升群体成员的元认知水平。
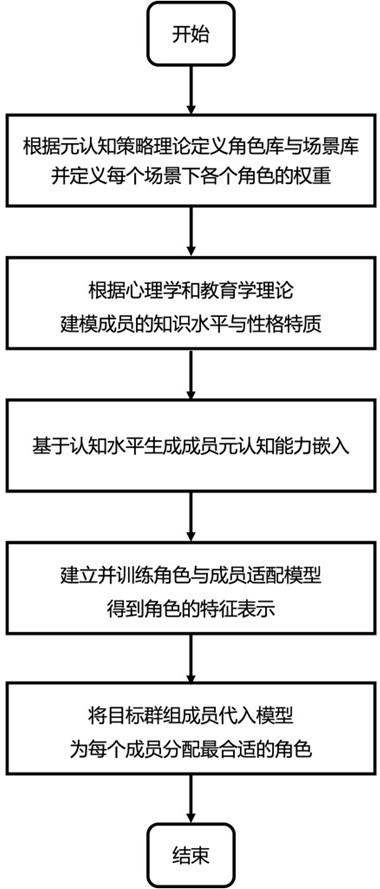
2、实现本发明的具体技术方案是:一种基于元认知的面向群体协作的个性化角色定位方法,特点是基于元认知策略理论建立角色库和场景库;根据不同任务场景实现个性化分配;基于认知水平生成成员的元认知能力画像;建立角色和成员的个性化适配模型,该方法具体包括以下步骤:
3、步骤一、根据元认知策略理论定义角色库与场景库,并定义每个场景下各个角色的权重;
4、在团队协作中,每个人都在被动扮演着或者必须扮演着一个或多个角色,每个角色都有其不同的特点和功用,角色之间的合理调配和运用则是高绩效团队的重要基础。故对于既定的项目,找出能推动协作的关键角色是至关重要的。本发明基于元认知策略理论,从元认知流程中的作用出发,对团队中替代元认知机器人所需要的角色进行界定与归纳,将角色类型分为推进者、计划员、监督员、协调者、领导者等共n个角色。团队协作任务所需要的角色库表示为矩阵c={c1,c2,...,cn},其中ci(i=1,...,n)为由专家基于元认知策略理论对团队协作任务界定与归纳出的角色的向量表示。
5、接下来按照界定与归纳出的角色对团队中的成员进行标定,即为团队中的每名成员分配最匹配的角色。将标定好的成员作为训练集,用于训练角色与成员适配程度定量模型,得到由下述(a)式表示的角色矩阵表示c:
6、c={c1,c2,...,cn} (a)。
7、场景库表示s由下述(b)式表示为:
8、s={s1,s2,…,st} (b)。
9、其中,sj为由专家基于元认知策略理论定义的场景,是一个维数为n的向量,第i个分量的值代表对应角色ci在该场景中的重要程度。
10、步骤二、根据心理学和教育学理论建模成员的知识水平与性格特质;
11、第一,由成员的历史成绩获取其知识水平表示;
12、从成员的历史成绩中选择合适的特征来表示学生的知识水平,如总成绩在团队中的排名、成绩波动程度、分析题与主观题得分情况等。
13、根据选择的特征,将每个学生的历史成绩转换为一个特征向量,特征向量的维度为选择的特征数量,获取到的知识水平kx由下述(c)式表示为:
14、kx=(k1,k2,…,kl) (c)。
15、其中,ki代表从成员历史成绩中提取出的第i个特征。
16、第二,利用统计学方法,得到成员的性格特质表示;
17、团队中的每名成员基于tf-idf算法的性格特质表示px由下述(d)式表示为:
18、px=(p1,p2,…,ps) (d)。
19、首先,获取到性格的liwc词库类,并截取相关性最高的s个词库类。
20、其中,pi是成员x关于第i个心理词库类别的显著度,所述性格特质表示px由成员的历史对话文本信息计算得到。
21、对于每一个用户,首先计算每个性格词库类别的词频tf,具体如下述(m)式表示为:
22、
23、其中,mhj是第j类心理词库类别词在该成员的历史对话文本中出现的总次数,mt是其历史对话文本的词汇总数。
24、接下来计算每个心理词库类别的逆文本频率指数idf,具体如下述(n)式表示为:
25、
26、其中,t表示历史对话文本的总数,hj表示包含第j类心理词库类别词的对话文本数量。
27、最后,成员x的性格特质表示px由下述(d)式定义为:
28、px=(p1,p2,…,ps)=tf*idf*{r1,r2…rs} (d)。
29、其中,rj是第j个性格词库类别与性格的相关性因子;*为对应位置元素相乘运算。
30、步骤三、基于认知水平生成成员元认知能力嵌入;
31、考虑到元认知与认知的关联,即当下的元认知是对之前所有对话认知的监督和反思,首先获取成员的认知水平,再由此计算得出元认知能力。
32、首先将每个成员的对话分为两部分,最后一次发言作为当前对话,其余为历史对话。然后将对话放入lstm模型中进行编码,得到对应的隐藏状态序列,lstm模型中的隐藏状态由下述(o1)~(o5)式计算:
33、it=sigmoid(wi·[ht-1,xt]+bi) (o1);
34、ft=sigmoid(wf·[ht-1,xt]+bf) (o2)
35、ot=sigmoid(wo·[ht-1,xt]+bo) (o3);
36、ct=ft⊙ct-1it+tanh⊙(wc·[ht-1,xt]+bc) (o4);
37、ht=ot⊙tanh(ct) (o5)。
38、其中,it、ft、ot分别表示输入门(input gate)、遗忘门(forget gate)和输出门(output gate)的激活值;ct表示记忆细胞状态,ht表示隐藏状态;wi、wf、wo、wc分别表示权重矩阵;bi、bf、bo、bc表示偏置向量;[ht-1,xt]表示连接前一个时间步的隐藏状态ht-1和当前时间步的输入xt。
39、历史对话的隐藏状态序列表示为dh={dh1,dh2,...,dhr},其中dhj表示第j个历史对话序列。当前对话的隐藏状态序列为dc={c1,c2,...,cp},其中cj表示第j个当前对话状态。
40、将历史对话序列放入bert中,经过可训练的权重矩阵wm,得到其对于整段话的认知表示cog由下述(f)式表示为:
41、cog={cog1,cog2,...,cogr} (f)。
42、其中,cogi=wmbert(dhi)为第i个认知序列。
43、最终使用注意力机制来获取成员元认知的向量表示,对每个认知序列cogj,由下述(h)计算注意力权重向量aj:
44、
45、其中,chj为下述(g)计算的cogj的隐藏状态:
46、chj=tanh(wh·cogj+wk·cj) (g)。
47、其中,wh、wk、wa是可学习的参数,chj是cogj的隐藏状态。
48、使用注意力权重向量aj对认知水平矩阵cog进行加权,得到由下述(i)式计算的成员元认知能力表示mj:
49、mj=cog·aj (i)。
50、成员的元认知能力嵌入由下述(e)式表示为:
51、mx={m1,m2,...,mr} (e)。
52、其中,mx为成员的元认知能力表示向量,mj为其分量。
53、步骤四、建立并训练角色与成员适配程度定量模型,得到角色的特征表示;
54、成员画像gx由下述(j)式表示为:
55、gx=kx||px||mx (j)。
56、其中,kx为成员的知识水平表示,px为成员的性格表示,mx为成员的元认知能力表示,||表示拼接操作。
57、角色库c={c1,c2,...,cn}为h×n的画像矩阵,其中每个列向量ci代表一个角色画像。为了使成员画像与角色矩阵在同一个向量空间中,利用投影参数矩阵w进行空间映射。任务为场景库中的场景j时,成员x与各个角色间的适配程度r由下述(k)式计算:
58、
59、其中,为成员x的画像向量经过转置运算得到的行向量;为场景j对应的场景向量sj经过转置运算得到的行向量;*为对应位置元素相乘运算。
60、模型训练过程中,损失函数由下述(p)式计算:
61、
62、其中,pi为每个成员被分类为第i个角色的概率;θ为模型可训练的参数集合;λ为l2正则化参数。
63、训练模型得到角色矩阵表示c={c1,c2,...,cn}与接口矩阵w。
64、步骤五、将目标群组成员代入模型,为每个成员分配最合适的角色。
65、对于需要进行角色分配的团体g={g1,g2,...,gq}和任务对应的场景sk,先按照步骤二、三、四得到每个成员的画像嵌入gx,具体由下述(j)式表示为:
66、gx=kx||px||mx (j)。
67、其中,kx,px,mx分别为第x个成员的知识水平表示、性格特质表示与元认知能力表示。
68、再按照场景sk中标定的角色的重要程度由高到低的顺序,由下述(1)式依次计算每个角色与成员间的适配程度rij:
69、
70、其中,为成员j的画像向量经过转置运算得到的行向量。
71、对于每个角色ci,将其分配给与其适配程度rij最高的成员gj后,再分配下一个角色ci+1,直到完成所有成员的角色分配。
72、本发明与现有技术相比具有能够优化群体协作表现,提升群体成员的元认知水平,利用聊天机器人为每位成员分配最合适的角色,使成员们更好地学会在群体协作中运用合理的元认知支架自己提出个性化的提示问题,并逐渐达成群体决策共识,有效解决了在意图增强群体元认知的研究中,单个成员无法替代聊天机器人提供的元认知支架问题,方法简便,具有有效性。
- 还没有人留言评论。精彩留言会获得点赞!