一种基于时空图卷积神经网络的异常行为识别方法与流程
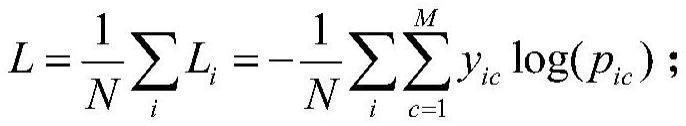
本技术涉及异常行为的识别领域,尤其是涉及一种基于时空图卷积神经网络的异常行为识别方法。
背景技术:
1、在场景识别中,有很大一部分研究是针对于人体行为识别的,主要进行识别的也是一些家庭内的危险行为,如小孩、老人摔倒检测,外来人员闯入等,这些都可归为人体行为识别的范畴之内。行为识别,即根据视频图像完成对于人体动作的区分,这其中包括但不限于摔倒等危险动作。
2、行为识别研究的是视频中目标的动作,比如判断一个人是在走路,跳跃还是挥手。在视频监督,视频推荐和人机交互中有重要的应用。近几十年来,随着神经网络的兴起,发展出了很多处理行为识别问题的方法。不同于目标识别,行为识别除了需要分析目标的空间依赖关系,还需要分析目标变化的历史信息。这就为行为识别的问题增加了难度。输入一系列连续的视频帧,机器首先面临的问题是如何将这一系列图像依据相关性进行分割,比如一个人可能先做了走路的动作,接下来又做了挥手,然后又跳跃。机器要判断这个人做了三个动作,并且分离出对应时间段的视频单独进行判断。
3、在生活过程中,有些目标物可能会做出一些异常行为,这些异常行为可能存在着危险,但是目前的算法不容易对这些异常行为进行识别,这就导致这些异常行为容易给人们带来危险。
技术实现思路
1、为了提高更好更准确的对目标物的异常行为进行识别,并提高对目标物异常行为识别的准确率,减少异常行为所带来的危险,本技术提供了一种基于时空图卷积神经网络的异常行为识别方法,其通过利用视频数据训练异常行为识别模型,然后让异常行为识别模型检测待检视频源中是否存在异常行为,若存在异常行为则发送告警信息,便于工作人员获知,减少异常行为所带来的危险。
2、本技术提供一种基于时空图卷积神经网络的异常行为识别方法,采用如下的技术方案:
3、一种基于时空图卷积神经网络的异常行为识别方法,包括以下步骤:
4、s1、获取目标对象的视频数据;
5、s2、标签标注视频数据的异常行为,得到数据集;
6、s3、构建异常行为识别模型,基于数据集在时空卷积神经网络上进行训练,得到异常行为识别模型;
7、s4、输入待检视频源,选取与待检视频源匹配的异常行为识别模型,并输入待检视频源的告警类型;
8、s5、异常行为识别模型对待检视频源进行检测,并在待检视频源发生异常行为时推送相应的告警信息。
9、优选的,视频数据包括:
10、异常行为视频数据,用于数据标注和神经网络模型训练,让神经网络模型从中提取到异常行为的特征;
11、正常行为视频数据,用于使数据均衡,使训练模型具有更高的精确度和泛化能力。
12、优选的,所述s2包括以下步骤:
13、s21、标注视频数据中目标的边界框、然后标注目标的骨骼关键点,接着标注目标的行为类型,最后得到数据集;
14、s22、数据集的划分,将数据集分成训练集、测试集和验证集。
15、优选的,训练集、验证集和测试集的比例设置为70%、10%和20%。
16、优选的,所述s3包括以下步骤:
17、s31、输入视频数据,然后通过目标检测算法获得每一帧目标的边界框信息和置信度;
18、s32、输入目标检测得到的边界框信息,然后通过人体关键点检测算法获得每一帧人体骨骼节点的二维坐标数据;
19、s33、对二维坐标输入数据进行多层时空图卷积运算,在图上生成更高层次的特征图;然后输入到softmax分类器进行动作分类。
20、优选的,所述s31包括以下步骤:
21、目标检测算法采用yolov5,yolov5网络包括数据增强单元、cspnet特征提取单元、panet尺度单元、k-means聚类算法单元、损失计算单元;
22、数据增强单元包括:
23、①对输入的图像进行色彩空间进行转换,由rgb转换为hsv;
24、其中,h/s/v分量值分别为0.015/0.7/0.4;
25、②对输入的图像进行亮度、颜色、对比度平衡调整;
26、③对输入的图像进行水平和垂直平移;
27、④对输入的图像进行缩小或放大处理,缩放因子为0.5.
28、⑤对输入的图像进行剪切处理,剪切因子为0.3;
29、⑥对输入的图像进行上下左右翻转处理,得到增强数据;
30、cspnet特征提取单元包括:
31、cspnet特征提取单元包括focus单元、cbm单元、bottleneck单元、conv卷积单元、连接单元、bn单元、leakyrelu激活单元;
32、focus单元,用于对增强后的源图像进行focus操作,得到第一特征图;
33、cbm单元,用于对第一特征图依次进行标准卷积操作、批量归一化操作和mish函数激活操作,得到第二特征图;
34、bottleneck单元,用于对第二特征图进行bottleneck操作,得到第三特征图;
35、bottleneck单元模块表示为:nout=f(ni,(wi))+ni,1≤i≤l-1;
36、其中,i为整数,f(ni,(wi))表示待学习且为进一步学习的映射,具体表示为:
37、k1=f(0.5x)+x,k2=f(k1)+x;
38、其中,ki代表i层模块的输出;
39、conv卷积单元,用于对第三特征图进行标准卷积操作,得到第三特征图卷积结果;用于对第一特征图进行标准卷积操作,得到第一特征图卷积结果;
40、连接单元,用于对第一特征图卷积结果和第三特征图卷积结果进行连接操作,得到连接处理结果;
41、bn单元,用于对连接处理结果进行批量归一化操作,得到归一化特征数据;
42、leakyrelu激活单元,用于对归一化特征数据进行激活函数leakyrelu操作,得到激活特征数据;
43、cbm单元,用于对激活特征数据依次进行标准卷积操作、批量归一化操作和mish函数激活操作,得到源图像特征图;
44、panet尺度单元包括:
45、panet尺度单元,用于融合源图像特征图,得到尺度为20的源图像特征图、尺度为32的源图像特征图、尺度为53的源图像特征图和尺度为80的源图像特征图;
46、k-means聚类算法单元包括:
47、k-means聚类算法单元,用于生成分别对应于四个尺度的源图像特征图的四组锚框,通过k-means聚类算法根据四个尺度的源图像特征图得出目标检测结果,检测结果包括目标位置信息和类别信息;操作为:
48、①随机选取k个点做为初始聚集的簇心(也可选择非样本点),本发明中k=4,最终将特征图分为四个尺度大小;
49、②分别计算每个样本点到k个簇核心的欧式距离,找到离样本点最近的簇核心,将它归属到对应的簇;
50、③将所有点m都归属到簇之后,m个点分为k个簇,重新计算每个簇的重心(平均距离中心),将其定为新的“簇核心”;
51、④反复迭代②-③的计算过程,直到达到中止条件;
52、上述损失计算单元具体包括:
53、网络的损失由三部分组成:坐标误差lcoord、交并比误差lciou和分类误差lclass;
54、lcoord和lclass是由交叉熵损失函数计算,其定义为:
55、
56、其中,n为类别数量,yic为符号函数,如果样本i的真实类别等于c取1,否则取0;pic为观测样本i属于类别c的预测概率;
57、交并比误差lciou的定义为:
58、
59、其中,iou代表交并比,b代表预测边界框b的中心点,bgt代表真实边界框bgt的中心点,ρ2(b,bgt)代表b和bgt之间的欧式距离,c代表预测框与真实框的最小外接矩形对角线的长度,a是一个参数,是用来权衡长宽比的系数,v用来计算长宽比的误差;
60、
61、其定义如下:
62、
63、其中,a代表真实标签边界框,b代表预测边界框,a∩b为预测边界框与真实边界框的交集,a∪b为预测边界框与真实边界框的并集。
64、优选的,所述s32具体包括以下步骤:
65、人体关键点检测算法采用alphapose;
66、人体关键点检测算法alphapose包括:
67、人体关键点检测算法alphapose中采用rmpe框架,rmpe框架包括sstn模块、pose-nms模块和pgpg模块;
68、sstn模块包括stn模块、sppe模块和sdtn模块;
69、stn模块包括:
70、stn模块定义如下:
71、
72、其中,为变换后的坐标,为变换前的坐标,θ1,θ2,θ3为变换参数;
73、sppe模块包括:
74、sppe为得到估计的姿态;
75、sdtn模块包括:
76、sdtn模块定义如下:
77、
78、其中,为变换后的坐标,为变换前的坐标,为变换参数;
79、变换参数的关系如下:
80、
81、pose-nms模块包括:
82、pose-nms为消除额外的估计到的姿态,令第i个姿态由m个关节点组成,定义为其中,k为位置信息,c为得分,得分最高的姿态作为基准,重复消除接近基准姿态的姿态,直到剩下单一的姿态,姿态距离用于消除和其他姿态太近且太相似的姿态,假定pi的边界框是bi,其定义如下:
83、
84、其中,为中心在的边界框,并且每个坐标b(kin)为原始坐标bi的1/10;
85、sppe模块包括:
86、sppe为训练阶段作为额外的正则项,避免陷入局部最优,并进一步提升sstn的效果,包含相同的stn及sppe,无sdtn;测试阶段不包含sppe模块,psppe模块和原始的sppe共享相同的stn参数,但是无sdtn模块,此分支的人体姿态已经中心化,和中心化后的真知标签直接比较,训练阶段,psppe所有层的参数均被冻结,目的是反传中心化的姿态误差到stn模块,若stn得到的姿态未中心化,会产生较大的误差,使得stn集中于正确的区域。
87、优选的,所述s33包括以下步骤:
88、对二维坐标输入数据进行多层时空图卷积运算,在图上生成更高层次的特征图;然后输入到softmax分类器进行动作分类;整个模型采用端对端反向传播的方式进行训练;
89、网络包括邻接矩阵、gcn、tcn;
90、邻接矩阵包括:
91、引入一个可学习的与邻接矩阵等大小相同的权重矩阵并与邻接矩阵按位相乘,该权重矩阵叫做“可学习的边缘重要性权重”,用来赋予邻接矩阵中重要边较大的权重且抑制非重要边的权重;
92、gcn包括:
93、将加权后的邻接矩阵与输入送至gcn中进行运算,同时引入残差结构计算获得res,与gcn的输出按位相加,实现空间维度信息的聚合,使用的图卷积公式定义为:
94、aggre(x)=d-1ax;
95、其中,可以理解为卷积核;
96、考虑到动作识别的特点,并未使用单一的卷积核,而是使用图划分,将分解成分别表达向心运动、离心运动和静止的动作特征,对于一个根节点,与它相连的边可以分为3部分:第1部分连接空间位置上比本节点更远离整个骨架重心的邻居节点,包含离心运动的特征;第2部分连接更为靠近重心的邻居节点,包含向心运动的特征;第3部分连接根节点本身,包含静止的特征,将1个图分解成3个子图,将卷积核从1个变为3个,3个卷积核的卷积结果分别表达不同尺度的动作特征对每个卷积核分别进行卷积,再进行加权平均,得到卷积的结果;
97、带有k个卷积核的图卷积可以定义为:
98、
99、其中,n表示所有视频中的人数,k表示卷积核数,k取用3,c表示关节特征数,c的取值范围为64至128,t表示关键帧数,t的取值范围为150至38,v表示关节数,v取用25;
100、对v求和代表节点的加权平均,对k求和代表不同卷积核特征图的加权平均;
101、tcn包括:
102、tcn网络实现时间维度信息的聚合,tcn网络采用普通的cnn,在时间维度的卷积核>1;
103、gcn网络输出特征图的维度为(c,v,t)与图像特征图的形状(c,w,h)相对应,图像的通道数c对应关节的特征数c;图像的宽度w对应关键帧数v;图像的高度h对应关节数t,
104、在时间卷积中,卷积核的大小为时间卷积核大小×1,则每次完成1个节点,时间卷积核大小个关键帧的卷积,步长为1,则每次移动1帧,完成1个节点后进行下1个节点的卷积。
105、优选的,所述目标对象为人或动物;
106、异常行为包括翻越围栏、攀爬、违规操作、跌倒、徘徊。
107、综上所述,本技术包括以下至少一种有益技术效果:
108、1.本技术通过利用视频数据训练异常行为识别模型,然后让异常行为识别模型检测待检视频源中是否存在异常行为,若存在异常行为则发送告警信息,便于工作人员获知,减少异常行为所带来的危险。
109、2.本技术通过构建不同的异常行为的异常行为识别模型,并利用这些异常行为识别模型实时的对待检视频源进行异常行为检测,便于工作人员及时发现异常行为,并能够及时的对异常行为进行制止,减少异常行为所带来的的危险,提高大众的安全性。
- 还没有人留言评论。精彩留言会获得点赞!