一种基于联邦学习的可信模型训练方法
本发明涉及一种基于联邦学习的可信模型训练方法,属于机器学习领域。
背景技术:
1、联邦学习(fl)是一个分布式机器学习框架,能够在不共享数据的情况下进行多方协作训练以获得高质量的全局模型,从而提供默认的隐私保护。虽然fl为参与的客户提供了隐私保护,但其特殊的架构也带来了许多安全问题。为了保护隐私,fl的模型训练过程只对客户本身可见,这为恶意客户端发动攻击提供了环境基础。
2、联邦学习在防御恶意攻击上的的缺陷,一些工作已经指出,恶意客户端可能不使用真实的本地数据集,或不按要求执行本地训练任务,使用中毒的数据来训练本地模型,或者上传过时的、虚假的模型更新参数。这些不当行为可能会影响本地模型的正确性,破坏模型的准确性或阻碍全局模型的收敛。特别是在基于联邦学习的现实应用中,它可能导致模型判断不及时或不正确,或造成严重的经济损失。
3、现有联邦学习框架很少考虑节点不可信的情况,大部分可验证的联邦学习方案是验证聚合结果的正确性,因为聚合服务器可能会受到破坏或恶意攻击。大多数现有的工作验证校正通过证明、签名和区块链的聚合结果。然而,它们都依赖于参与节点提交的梯度的假设是正确的,但它们都没有考虑到真实的本地数据集是否在模型训练过程中被使用。以跨机构的联邦学习场景为例,不诚实的客户端只使用部分本地数据来更新本地模型,然后他们可以用较少的数据集和训练工作来骗取奖励。此外,训练数据集的真实性也是联邦训练结果可用性的先决条件,它可以与上述的解决方案结合起来以实现在有恶意客户的联邦学习中建立模型可信。据我们所知,很少有作品探讨过这个问题。
4、现有的联邦学习方案通常使用基于可信硬件的可信执行环境来确保本地执行过程的可信,但由于很难为具有异构硬件资源的所有客户端提供统一的可信执行环境。最近,基于zk-snark证明确保本地训练过程可信的方式被提出,通过采用基于软件的zk-snark与各种加密技术实现对联邦学习本地训练进行证明和隐私保护,确保训练完整性,即客户端能够按预期正确执行训练任务,从而防止懒惰客户端不完全执行训练过程或恶意客户端提供虚假的模型更新,实现了公平可信的联邦学习。
5、现有方案直接使用zk-snark生成证明会导致性能急速下降,因为证明时间使得基于zk-snark的证明性能陷入瓶颈。一些工作致力于通过优化可信模型训练中的神经网络训练的证明来提高证明zk-snark的效率。因为卷积计算中涉及大量的乘法门,使得卷积运算时性能瓶颈的主导因素。此外,zk-snark适用于处理加法门和乘法门,如何进行变换使得其能处理神经网络中的非线性层的处理。所以,如何优化神经网络计算减少证明开销是实现联邦学习本地训练可信的一项挑战。
技术实现思路
1、针对现有技术中存在的问题,本技术提出一种基于联邦学习的可信模型训练方法,在不影响准确性的情况下,实现在恶意环境下的联邦学习可信安全的全局模型聚合。
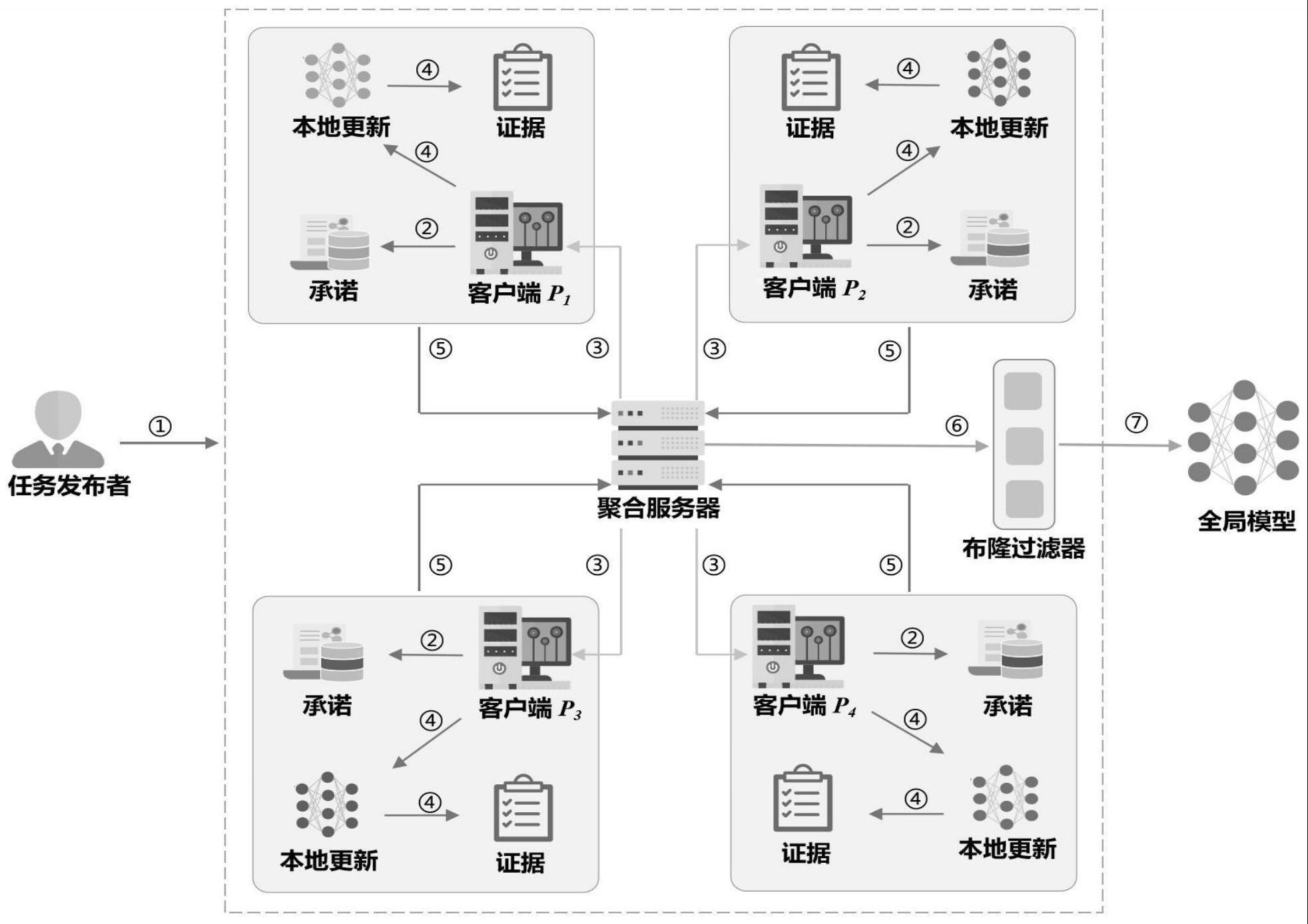
2、本发明采取的技术方案是,一种基于联邦学习的可信模型训练方法,包括初始化阶段、证明阶段和验证阶段,具体包括以下步骤:
3、初始化阶段包括,
4、任务发起者发布fl任务并生成公共参数;
5、客户端接受任务,下载公共参数对数据集进行预处理;
6、聚合服务器as分发全局模型;
7、证明阶段包括,
8、客户端本地训练,获得本地梯度更新,并根据训练过程生成可信证明;
9、客户端对数据承诺、可信证据、本地梯度进行打包发送到聚合服务器as;
10、验证阶段包括,
11、聚合服务器as接受消息,查询bloom过滤器,验证数据承诺,并验证可信证据。
12、优化的,上述基于联邦学习的可信模型训练方法,初始化阶段中,任务发起者发布联邦学习任务,公布初始全局模型θ0,生成公共参数pp并将其发送至聚合服务器as;多个节点协作生成和发布crs;
13、客户端pj将本地数据集的子集承诺发送到聚合服务器as,聚合服务器as将承诺存储至布隆过滤器后,将公共参数pp公开给各参与客户端pj;
14、客户端pj在接收到公共参数pp后,使用其中的模数序列h={h1,h2,...,hn-m+1}对本地数据集d中的样本矩阵x进行预处理,预处理操作包括中国剩余定理和im2col变化,之后获得处理后的矩阵e。
15、优化的,上述基于联邦学习的可信模型训练方法,证明阶段中,
16、在联邦学习任务的每轮迭代中,参与客户端pj使用本地数据子集训练新一轮的本地模型,并使用预处理后的矩阵e对训练的过程中的卷积神经网络操作生成一个本地证明,包含卷积层和非线性层证明,生成可信证据,用于证明客户端正确执行了本地训练操作,本地模型的生成过程是可信的;
17、参与客户端pj将本轮训练子集的承诺、可信证据,一同发送至聚合服务器as。
18、优化的,上述基于联邦学习的可信模型训练方法,验证阶段中,
19、聚合服务器as收到客户端pj发送的消息后,首先查询对应数据子集的承诺是否存储在布隆过滤器中,验证客户端的数据真实性;
20、聚合服务器as对客户端pj的可信证据进行验证,验证客户端的训练完整性;
21、聚合服务器as对客户端完整数据集的承诺和数据子集的承诺进行检验,验证客户端参与联邦学习的数据完整性。
22、优化的,上述基于联邦学习的可信模型训练方法,任务发起者发布联邦学习任务,公布初始全局模型θ0,生成公共参数pp并将其发送至聚合服务器as的具体过程包括,
23、任务发起者分发联邦学习任务,初始化全局模型θ0和公共参数pp,任务发起者选择一个大素数p,生成一个p阶素数群其中p>2λ,λ是安全参数,并生成一个双线性映射包含三个群g1,g2,gt满足e(g1,g2)→gt,其中g,h分别是g1,g2的生成元;
24、接着选择期望的训练轮数t,样本矩阵的维度n×n,卷积核维度m×m,构造一个m2×m2的奇异方阵u,最后计算一个模数序列h={h1,h2,...,hn-m+1};
25、任务发起者将公共参数发送给聚合服务器as;
26、多个节点协作生成和发布crs的具体过程包括,
27、假设有ρ个节点协同生成crs,每个节点首先将本地证明的约束条件从一种np语言转换为对应的关系,然后每个节点选择6个随机数xi,αi,βi,γi,δi,zi∈zq,计算如下:
28、每个节点广播(αi,βi,γi,δi,xi,zi),接收来自其他ρ-1节点的广播,并将所有节点的参数聚合如下:
29、
30、接着,每个节点计算如下,
31、
32、最后,将公开给所有节点。
33、优化的,上述基于联邦学习的可信模型训练方法,对本地数据集d中的样本矩阵x进行预处理的具体过程包括,
34、客户端pj下载公共参数pp后,使用其中的模数序列h={h1,h2,...,hn-m+1}对本地数据集d中的样本矩阵x进行预处理ei,j=crt(xi,j,xi+1,j,...,xi+n-m,j),
35、
36、客户端pj将本地数据子集dj的承诺comm(dj)=u×ej发送到聚合服务器as,聚合服务器as将承诺comm(dj)存储至布隆过滤器bf中。
37、优化的,上述基于联邦学习的可信模型训练方法,在联邦学习任务的每轮迭代中,参与客户端pj使用本地数据子集训练新一轮的本地模型,其具体过程包括,
38、假设客户端pj在第t轮训练中获得了全局模型θt-1,客户端pj在数据集dj的子集上训练本地模型,提取卷积核矩阵w和特征矩阵e;
39、使用预处理后的矩阵e对训练的过程中的卷积神经网络操作生成一个本地证明,其具体过程包括,
40、客户端pj使用优化zk-snark证据生成算法生成可信证据;
41、客户端pj首先对卷积层操作进行证明,客户端pj将批量卷积操作构造为多个矩阵乘法w×e=z,并通过设定不确定变量q将多个矩阵乘法联立,使得σqiwi×σqiei=σqizi成立;
42、根据基于qmp的zk-snark定义,左线输入为右线输入为输出线为客户端pj设置φ为(q1,q2,...,qs),设置ω为(qs+1,qs+2,...,qn),并生成可信证据通过执行算法π←prove(crs,φ,ω),客户端pj随机在选取r,s,并计算证据如下:
43、
44、客户端pj得到证据π=(a,b,c,d),能够使得等式e(a,b)==e(gα,hβ)·e(d,hγ)·e(c,hδ)成立;
45、对于最大池化层和激活函数层等非线性层,采用0/1矩阵来模拟非线性操作,并将非线性运算转换为矩阵运算;
46、在最大池化层,根据每个池化区域中最大元素的位置,将最大池化运算矩阵pm的相应元素设置为1,其余元素设置为0,以此将非线性最大池化操作转换为与前一层的输出矩阵z的矩阵乘法运算
47、在激活层,构造具有0和1个元素的relu运算矩阵rm,其中1对应于输入relu激活层中大于0的元素,将其与从卷积层输出的特征矩阵z进行矩阵相乘并使用上述设计的基于qmp优化证据生成算法进行处理;
48、客户端pj在完成模型训练和证据生成后,将子集承诺comm(dji),可信证据π和本地梯度更新打包,发送至聚合服务器as。
49、优化的,上述基于联邦学习的可信模型训练方法,聚合服务器as收到客户端pj发送的消息后,首先查询对应数据子集的承诺是否存储在布隆过滤器中,验证客户端的数据真实性,其具体过程为,
50、数据真实性验证,聚合服务器as使用布隆过滤器的ξ个无偏哈希函数来计算数据子集承诺的哈希,并同余布隆过滤器的长度l以将子集承诺的哈希存储至布隆过滤器中,具体bitk←hk(hash(comm(dji)))modl,判定对应的比特位在布隆过滤器中是否为1;
51、每个比特都将以ò的误判率被错误的判断,如果经过全部ξ次查询结果都为1,则有1-òξ的极大概率来确认布隆过滤器中包含改子集的承诺,即数据真实性验证成功,
52、聚合服务器as对客户端pj的可信证据进行验证,验证客户端的训练完整性,其具体过程为,
53、数据完整性验证,假设经过t轮训练,全局模型收敛,模型精度达到要求;
54、当t<t时,说明在所有的承诺子集使用完之前全局模型达到任务发起者的需求,联邦学习任务完成,此时我们要求所有客户端将剩下的承诺上传用于数据完整性验证;
55、当t=t时,直接进行数据完整性验证;
56、当t>t时,意味着在所有子集都经过训练后,全局模型一人没有达到要求,我们使用相同的数据子集对下t轮进行训练,每一个t轮执行一次完整性验证,直到模型收敛;
57、聚合服务器计算挑战值η=hash(comm(d)),验证等式是否成立,若成立,则数据完整性验证通过,得到b2=1;
58、聚合服务器as对客户端完整数据集的承诺和数据子集的承诺进行检验,验证客户端参与联邦学习的数据完整性,其具体过程为,
59、训练完整性验证,聚合服务器as通过执行算法b3←verify(crs,φ,π),解析π为(a,b,c,d),并计算等式e(a,b)=e(gα,hβ)·e(d,hγ)·e(c,hδ)是否成立,若成立,则训练完整性通过;
60、最后,验证若b为1,则证明客户端本地模型训练是真实执行的,否则,就认定该客户端是恶意的,将其梯度更新舍弃。
61、本技术的有益效果为:
62、本技术的技术方案中,设计实现联邦学习对本地训练完整性的可信证明,在不影响准确性的情况下,实现了在恶意环境下的客户端可信模型训练的证明生成。
63、通过使用中国剩余定理对数据集进行预处理操作,显著减少在线证据生成时间;优化了神经网络中的非线性层操作,减少了可信证据生成的证明开销。
64、解决了卷积神经网络模型中卷积运算开销过大的问题。
65、实现客户端/服务器架构下的数据真实性和数据完整性的轻量级验证;利用了一个基于零知识简洁的非交互式知识论证的电路改进来提高批量证明的证明效率。
66、本技术的技术方案还利用率轻量级的承诺方案和布隆过滤器,使得联邦学习的通信和存储开销得到较大改善。
- 还没有人留言评论。精彩留言会获得点赞!