一种基于人工智能的异常人员风险预测方法、系统及介质
本发明涉及数据处理,具体涉及一种基于人工智能的异常人员风险预测方法、系统及介质。
背景技术:
1、近年来,在社会飞速发展,人民生活水平提高的同时,还存在部分社会安全问题;从社会学角度来看,部分刑满释放异常人员回归社会后面临着来自亲友、社区、企业等各方面的问题,存在难以继续学业、难以顺利就业,难以维持基本生活的问题,导致了再次犯罪的发生。另一部分刑满释放异常人员在生存问题得到解决后,依然存在犯罪风险,具有较高的社会风险。因此,在异常人员回归社会以前,对其进行风险评估,根据评估结果采取相应的跟踪帮扶措施,对于社会治理具有重大意义。
2、目前,该工作主要由专职人员根据异常人员的犯罪性质、犯罪情节及服刑期间的表现等对其进行评估,主要依赖于一线工作人员的相关经验和主观看法,缺乏定量、客观、可复制的依据。
3、近年来,也有部分研究型的工作尝试通过大数据和人工智能的方法实现客观的犯罪预测。如专利“犯罪预测方法、装置、设备及计算机可读存储介质”中记载了一种发明,其通过异常人员的多维数据集构建人工智能模型,自动预测犯罪风险。但该发明中仅涉及了包含人员基本信息和行为轨迹在内的客观数据,缺乏对异常人员原始犯罪信息相关的特征提取,而后者在犯罪动机中不可忽视。
技术实现思路
1、本发明所要解决的技术问题是:传统的犯罪预测方法主要依赖于一线工作人员的相关经验和主观看法,缺乏定量、客观、可复制的依据;本方案依托于监狱、看守所现有的评估数据源,通过人工智能技术,提出基于异常人员原始犯罪信息的犯罪情节提取定量的高维特征,融合从结构数据中提取的数字化特征,共同实现异常人员风险评估的系统。在对客观事实的结构化数据进行数字化分析的同时,从异常人员犯罪信息的文本数据中提取出描述犯罪意愿的特征,进一步提高了风险评估的准确性,其采用的数据源具有容易获取、不增加基层人员额外工作的特点,具有良好的应用前景。
2、本发明通过下述技术方案实现:
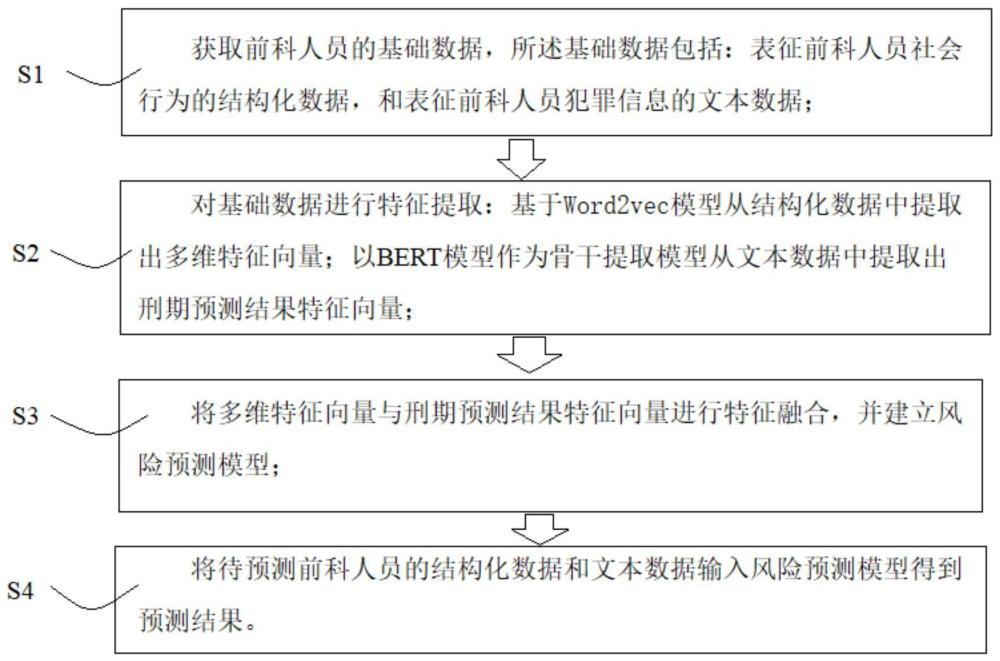
3、本方案提供一种基于人工智能的异常人员风险预测方法,包括步骤:
4、s1,获取异常人员的基础数据,所述基础数据包括:表征异常人员社会行为的结构化数据,该类信息通过构造结构化数据库的形式进行特征数字化;和表征异常人员犯罪信息的文本数据,如犯罪情节描述;
5、s2,对基础数据进行特征提取:基于word2vec模型从结构化数据中提取出多维特征向量,word2vec模型将结构化数据原始的一维特征转化为多维特征,其中维度的大小取决于原始特征中不同特征值的个;以bert模型作为骨干提取模型从文本数据中提取出刑期预测结果特征向量;
6、s3,将多维特征向量与刑期预测结果特征向量进行特征融合,并建立风险预测模型;
7、s4,将待预测异常人员的结构化数据和文本数据输入风险预测模型得到预测结果。
8、本方案工作原理:传统的犯罪预测方法主要依赖于一线工作人员的相关经验和主观看法,缺乏定量、客观、可复制的依据;本方案依托于监狱、看守所现有的评估数据源,通过人工智能技术,提出基于异常人员原始犯罪信息的犯罪情节提取定量的高维特征,融合从结构数据中提取的数字化特征,共同实现异常人员风险评估的系统。在对客观事实的结构化数据进行数字化分析的同时,从异常人员原始犯罪信息的文本数据中提取出描述犯罪意愿的特征,进一步提高了风险评估的准确性,其采用的数据源具有容易获取、不增加基层人员额外工作的特点,具有良好的应用前景。
9、进一步优化方案为,所述多维特征向量的提取方法包括:
10、t1,获取结构化数据的原始特征;
11、t2,对特征值为2的原始特征进行分类处理得到二分类特征数据,并基于one_hot编码将二分类特征数据映射为多维特征数据;
12、t3,对特征值大于2的原始特征,基于one_hot编码将多维特征数据映射为多维特征数据。通过one_hot编码,就可以把原始类别向量转变为计算机可识别的二进制向量表示。
13、进一步优化方案为,刑期预测结果特征向量的提取方法包括:
14、r1,对文本数据进行预处理得到词向量表示数据;
15、r2,建立bert-crf模型,基于词向量表示数据和bert-crf模型进行数据标注训练创建出数据池;
16、r3,基于数据池和bert模型训练刑期判决模型以获取刑期预测结果特征向量。
17、为了学习到犯罪情节中蕴藏的描述主观犯罪意愿的关键特征,以刑期判决模型作为bert模型训练的下游任务;法院量刑过程中,异常人员的犯罪意愿是刑期裁定的主要因素之一,因此,以刑期预测作为下游任务,从文本数据中所提取的特征能够对人员的犯罪意愿进行描述。
18、bert模型属于自然语言处理模型,需要大量的标注语料以便实现训练。而犯罪情节到刑期的映射属于极为专业的法律相关业务,为法律专业人士根据相关专业知识和经验进行逐案判断得到,标注过程较为困难。因此,在bert模型训练过程中采用半监督方法,所用的语料库包含两部分,一部分是公开的裁判文书平台上获取的真实文书数据,由犯罪情节和判决刑期构成,为有标签数据,另一部分是互联网平台上获取的关于犯罪情节的描述性文本段落,缺乏判决刑期,为无标签数据。
19、进一步优化方案为,所述预处理包括方法:
20、r11,基于beautifulshop中的html格式化方法先对文本数据进行数据清洗,去除html标签,再按照段落对文本数据进行分块处理;
21、r12,使用jieba分词对分块处理后的文本数据进行分词得到法律裁判文书数据;
22、r13,将法律裁判文书数据根据bert的中文词典进行编码得到全文的词向量表示数据。
23、进一步优化方案为,数据池的创建方法包括:通过主动学习和人工标注相结合,用更少的标注量来进行数据标注;
24、r21,建立bert-crf模型,通过语料库中的有标签数据对初始bert-crf模型进行训练,获得初始文本数据标注模型;
25、r22,基于初始文本数据标注模型的参数标注语料库中的无标签数据,并将标注后的无标签数据放入已标注数据池;
26、r23,计算已标注数据池中两文本数据间的余弦距离dist(a,b):
27、
28、dist(a,b)=1-cos(a,b)
29、其中,a、b分别表示已标注数据中不同文本的词向量表示数据;‖*‖表示文本信息向量的模长;
30、r24,将余弦距离超过距离阈值的两文本数据视为难标注数据,并使人工介入对难标注数据进行标注后放入已标注数据池;
31、r25,基于更新后的数据池强化训练bert-crf模型,直至难标注数据少于数据池中数据量的百分之一时停止,舍弃此时的难标注数据,得到最后的数据池。
32、进一步优化方案为,步骤r3包括以下子步骤:
33、r31,建立由n个encoder结构组成的bert模型;
34、r32,将数据池中的文本数据及其标签作为encoder结构中多头注意力机制的输入,计算在自注意力机制中的查询矩阵q、键矩阵k和值矩阵v:
35、q=ywq
36、k=xwk
37、v=xwv
38、其中,x为第n层隐藏层的输出,y为隐藏层以外其它层隐藏层的输出;wq,wk,wv分别是初始化的查询矩阵、键矩阵和值矩阵;
39、r33,对查询矩阵q、键矩阵k和值矩阵v进行softmax计算,得出隐藏层输出的权重attention(q,k,v):
40、
41、其中,kt表示键矩阵k的转置矩阵,d表示查询矩阵q的维度,softmax(*)表示softmax计算;
42、r34,将bert模型的隐藏层输出与对应权重先求积再求和得到信息向量表示;
43、r35,将r34得到的信息向量表示输入到encoder结构的前馈网络层,具体步骤为,先经过w1线性映射表示成高维,再通过w2线性映射投影回原空间,最后经过relu函数对投影回原空间的文本数据进行整合:
44、x=relu(x1*w1*w2)
45、式中w1表示线性映射的结果,w2线性映射投影的结果,x1表r34得到的信息向量,x表示整合后的信息向量;
46、r36,在bert模型的最后一层取出文本数据的向量表示,将其作为下一层bert模型的输入,并将取出的向量表示经过全连接层和softmax计算得到每个刑期预测的概率分布,以概率最大者作为刑期预测结果获取刑期预测结果特征向量。
47、进一步优化方案为,特征融合的方法包括:
48、基于下式进行特征融合:
49、z=concat(x,y)
50、z=[x,y]∈rm+n,x∈rm,y∈rn
51、式中,rm+n表示长度为m+n的向量,x为m维向量,表示多维特征向量,y为n维向量,表示刑期预测结果特征向量,z表示特征融合的结果,concat(*)表示融合操作。
52、进一步优化方案为,风险预测模型的建立方法包括:
53、将特征融合得到的特征信息向量按照7:3划分成训练数据集和测试数据集;
54、将练数据集输入logistic回归模型进行回归分析:
55、
56、其中,α0至αn分别为各变量系数,x1至xn为指标,如人员的各项社会行为信息,刑期判决信息,如刑期年限、是否缓刑等,表示描述异常人员重入社会后重新犯罪发生强度的统计指标;
57、基于logist(p)计算p值:
58、
59、根据风险预测模型计算出待预测异常人员的p值,其中p>50判断为再犯罪情况可能发生,且p值越高再犯罪概率越大,即该异常人员回归社会风险越大。
60、本方案还提供一种基于人工智能的异常人员风险预测系统,用于实现上述的基于人工智能的异常人员风险预测方法,包括:
61、数据收集模块,用于获取异常人员的基础数据,所述基础数据包括:表征异常人员社会行为的结构化数据,和表征异常人员犯罪信息的文本数据;
62、特征提取模块,用于对基础数据进行特征提取:基于word2vec模型从结构化数据中提取出多维特征向量;以bert模型作为骨干提取模型从文本数据中提取出刑期预测结果特征向量;
63、特征融合模块,用于将多维特征向量与刑期预测结果特征向量进行特征融合得到风险预测模型;
64、风险预测模块,用于将待预测异常人员的结构化数据和文本数据输入风险预测模型得到预测结果。
65、本方案还提供一种计算机可读介质,其上存储有计算机程序,所述计算机程序被处理器执行可实现如上述的一种基于人工智能的异常人员风险预测方法。
66、本发明与现有技术相比,具有如下的优点和有益效果:
67、本发明提供的一种基于人工智能的异常人员风险预测方法、系统及介质,融合异常人员犯罪信息的文本数据中提取的定量高维特征,和结构化数据中提取的数字特征,共同实现异常人员风险预测,为异常人员提供解除惩罚措施前预测回归社会风险的客观方法。
68、本发明提供的一种基于人工智能的异常人员风险预测方法、系统及介质,通过大数据和人工智能方法对待预测异常人员的信息进行定量计算,预测结果具有客观性和可重复性;区别于现有的、同类的、基于人工智能技术的风险评估方法,本发明引入了从异常人员原始犯罪信息的文本数据中提取的高维度特征,能够描述异常人员的犯罪意愿,从而提升了风险评估的准确性。
69、为了构建大规模语料库提升bert模型对情节特征提取的性能,本发明设计了主动学习策略,并且将置信度评分作为评价指标,能够大大地增加数据标注的效率。
- 还没有人留言评论。精彩留言会获得点赞!