一种GPT生成语言识别与检测系统的制作方法
本发明涉及一种,特别涉及一种gpt生成语言识别与检测系统。
背景技术:
1、
2、现如今的社会对今年1月对1000名18岁以上学生进行了调查,结果显示48%的学生会使用chatgpt完成小测验,而53%的学生则使用chatgpt撰写论文。英国thetab网站的调查显示,在12月和1月这两个大学的冬季考试季中,调查的八所大学中,就有高达128402次和982809次使用大学wifi浏览chatgpt网站的记录,数量相当惊人。如何与剽窃作斗争,保证学术诚信,已引起各高校的高度重视。许多其他的应用和活动也面临着类似的问题,法律、医疗和金融等专业领域问题上的实证评估领域,可能会产生潜在的有害或虚假信息。大量的基于ai恶意程序生成的假新闻或知识问答,也可能会导致大量不实的误导信息肆意传播。
3、现有技术中,通常试图采用统计离群点检测法试图根据生成文本中的痕迹区分人类编写的文本和机器生成的文本,并引入了gltr可视化工具,以帮助人类验证者检测机器生成的文本。它使用掩码填充策略构建模型生成文本的多个扰动,并将扰动的对数概率与未扰动的生成进行比较。如果未扰动文本的对数概率显著高于扰动的对数概率,则认为文本是模型生成的。
4、另一种检测方法依赖于分类器,这些分类器经过微调以区分人类书写的文本和机器生成的文本。这方面的早期努力是利用分类器来检测虚假的评论,主要通过多种语言模型微调,从而分辨人类的回答和机器的回答。
5、然而现有技术在中文领域的分辨具有较大的缺陷,具体包含有:
6、对非英语语种的支持问题:大型语言模型通常是在大规模的英文语料库上进行训练,对其他小语种的支持相对较弱,需要加强对小语种的支持;
7、准确性问题:llm文本检测器的准确率可能会受到数据不平衡、语言差异、对抗攻击和复杂文本等方面的限制,因此在实际应用中需要进行充分的评估和优化;
8、泛化性问题:通常情况下,深度学习模型对于训练集中的数据可以取得很好的拟合效果,但在面对未曾见过的数据时,可能会出现过拟合的现象,导致泛化性能下降,生成的文本质量也会受到影响。
技术实现思路
1、本发明要解决的技术问题是克服现有技术的缺陷,提供一种gpt生成语言识别与检测系统。
2、为了解决上述技术问题,本发明提供了如下的技术方案:
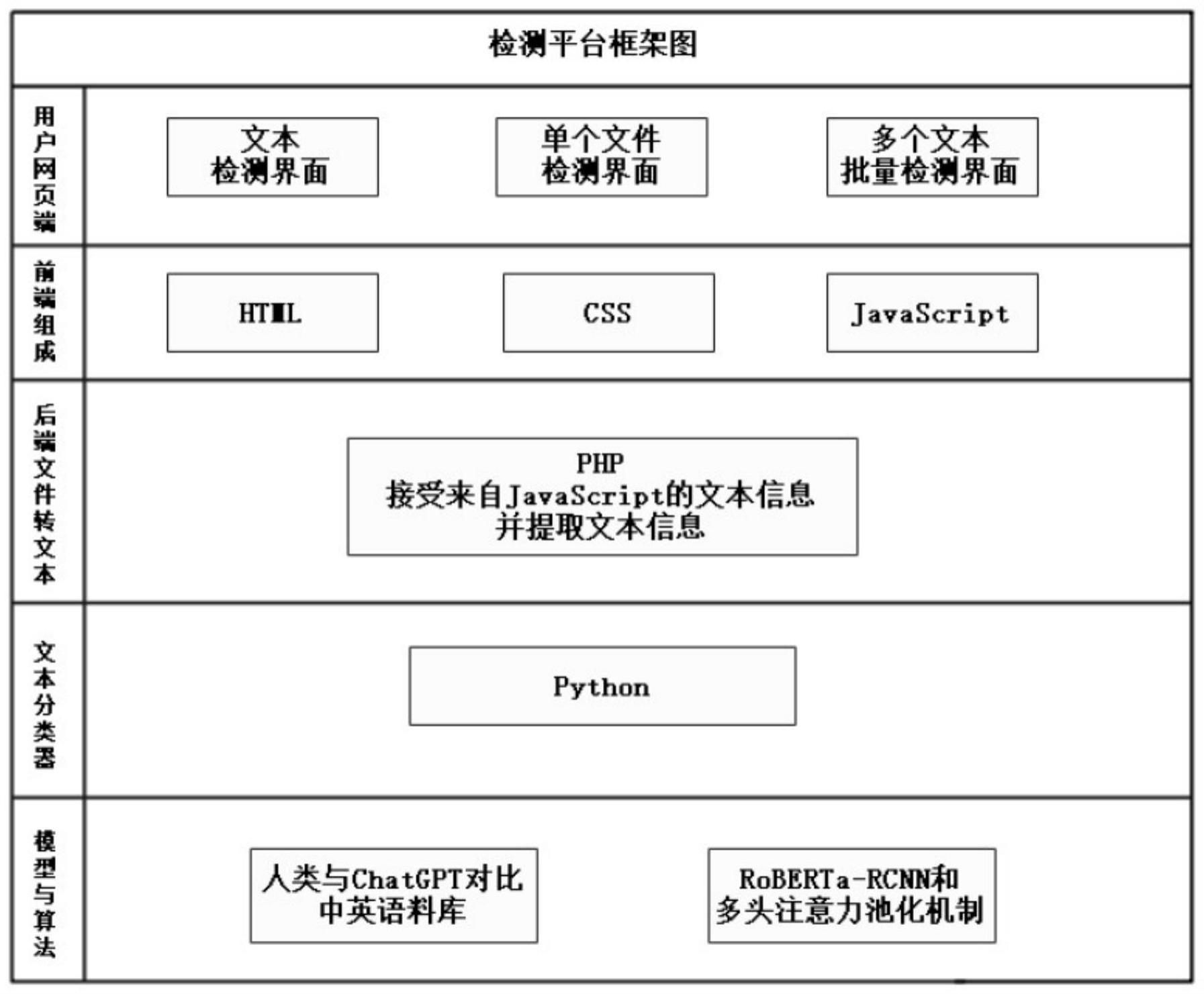
3、本发明一种gpt生成语言识别与检测系统,包括用户网页端、前端组成和模型与算法模块;
4、用户网页端包含有文本检测界面、单个文件检测界面和多个文本批量检测界面;
5、前端组成包含有html、css和javascript算法,用于前端展示和列序;
6、所述模型与算法模块包含有回译模块和rmap模型,其中rmap模型包含有roberta转换词向量模块、rcnn卷积神经网络、多头注意力池化和标签平滑正则化单元,用于形成人类与chatgpt对比中英文数据库以及对生成语言的识别;
7、回译模块包含有后端文件转文本和文本分类器,其中后端文件转文本包含有php算法,用于接受来自javascript的文本信息并提取文本信息;文本分类器包含有python,用于对文本类型分类;
8、模型与算法模块包含有如下步骤
9、s1.roberta转换词向量模块分别调用中文与英文roberta模型,从词嵌入层获取初始字向e1~en然后输入到多层双向transformer编码器中以获得带有特征信息的向量t1~tn,以此将输入的文本信息形成预处理后文本的向量表示返回;
10、s2.通过rcnn卷积神经网络作为深度特征提取模块,将输入的预处理文本向量表示处理为文本词向量表示输出;
11、s3.通过多头注意力池化,将处理后的文本词向量输入后处理为二分类结果;
12、s31.当模型在训练过程中面对数据较少或特征量较少时,采用标签平滑正则化单元,通过输入文本特征向量表示,并设置真实的标签以及平滑因子,调节平滑程度后,即可输出经过平滑法处理后的预测结果。
13、作为本发明的一种优选技术方案,回译模块主要用删除重复的语句、进行分词和去除无用的词汇,先对句子进行分词,删除重复语句,基于hc3数据集预处理。
14、作为本发明的一种优选技术方案,s2中,在经典rcnn模型的词表示学习过程中采用bilstm获得文本的上下文信息并将bilstm获得的隐层输出与词向量拼接组合为新的词表示,具体公式如下
15、cl(ωi)=f(w(l)cl(ωi-1)+w(sl)e(ωi-1))
16、cr(ωi)=f(w(r)cr(ωi+1)+w(sr)e(ωi+1)),
17、其中:cl(ωi)表示第i个目标词上下文的上文;cr(ωi)表示第i个目标词上下文的下文,它们都是维度为c的向量;e(ωi-1)和e(ωi+1)分别表示第i-1和i+1个词的词向量;w(1),w(r)∈rc×c是当前隐藏层转换到下一个隐藏层的权重矩阵;w(s1)和w(sr)是将当前词的语义与下一个词的上下文进行语义结合的矩阵;f为非线性激活函数;
18、获取目标词上下文表示后,将其与目标词的词向量进行拼接:
19、xi=[cl(ωi);e(ωi);cr(ωi)]
20、一条文本的词表示通过xi拼接后可以表示为:
21、x=[x1,x2,...,xi]
22、文本词向量表示通过映射后,进行激活函数的处理,
23、yi=f(wix+bi)
24、其中,映射矩阵wi∈r为属于cnn过滤器的权重;bi是偏置量;f(wix+bi)代表激活函数,在此选用更适合深度特征提取与分类的swish激活函数:
25、f(x)=xsigmoid(βx);
26、β为变量x的缩放参数,本步骤的缩放参数的取值为1。
27、作为本发明的一种优选技术方案,s3中,在进行文本分类时,将每条文本的向量作为q、k、v分别映射到不同子空间中矩阵乘积过程为矩阵乘积过程为:
28、[q1,q2,...,qh]wqh=[q1 wq1,q2 wq2,...,qh wqh]=[q1,q2,...,qh],
29、[k1,k2,...,kh]wkh=[k1 wk1,k2 wk2,...,khwkh]=[k1,k2,...,kh],
30、[v1,v2,...,vh]wvh=[v1 wv1,v2 wv2,...,vh wvh]=[v1,v2,...,vh],
31、其中:qh、kh、vh为多头注意力各子空间的查询、键、值;wqh、wkh、wvh为在训练中随机生成的权重矩阵;h为子空间的数量;
32、多头自注意力机制采用缩放点积注意力,计算公式为:
33、
34、其中,f函数采用了放缩机制,通过使用softmax函数利用注意力分数ui计算注意力的权重分布ai:
35、
36、对v加权求和得到注意力机制的输出,多头注意力机制的计算过程为:
37、
38、hi=attentionvalue(qwqi,kwki,vwvi)
39、multiheadatt=concat(h1,h2,...,hi)wo
40、最大池化层的基本操作是为词向量矩阵的每一个维度都设定一个滑动窗口,去掉文本词向量中其他的值,仅保留维度中最大的值:
41、mp=maxpooling(y1,y2,...,yi)
42、最大池化层保留了文本单个关键信息,注意力机制则注意到与输入文本关联大的局部信息,引入多头的思想进一步提取文本所有特征。将最大池化层、多头注意力模块的结果进行融合,并通过全连接层可得:
43、
44、最后将全连接层的输出通过改进的softmax函数得到文本分类概率分布p,再取概率最大值对应的标签为分类结果。
45、作为本发明的一种优选技术方案,s31中,模型会根据当前文本对应的各个类别返回一个置信分数,再经过softmax归一化处理,得到当前文本属于某一个类别的概率p。x作为训练的输入,得到的每一个类i的概率为:
46、
47、文本分类使用的交叉熵损失函数为:
48、
49、其中,qi为真实标签概率。文本分类模型的训练数据是以文本正确标签和错误标签差值最小为目标来学习的,当训练数据有限时,会导致过拟合问题的发生,故对loss进行了改进:
50、
51、其中,本步骤取超参数ε=0.1。
52、与现有技术相比,本发明的有益效果如下:
53、本发明提出了rmap融合机制,保证模型的分类效果与泛化能力。首先采用数据增强技术对部分训练数据进行回译处理,使用自编码预训练模型roberta和rcnn对文本进行特征提取,并利用多头注意力思想改进最大池化层的。完成深度特征提取后,通过softmax函数得到文本分类概率分布p,再取概率最大值对应的标签为分类结果,实现辨别效率高,且辨别更迅速准确的技术效果。
- 还没有人留言评论。精彩留言会获得点赞!