一种基于自监督对比学习的HPC作业功耗预测方法及系统与流程
本发明属于hpc作业预测领域,尤其涉及一种基于自监督对比学习的hpc作业功耗预测方法及系统。
背景技术:
1、本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
2、对于高性能计算(high performance computing,hpc)平台而言,hpc作业功耗时间序列对作业功耗的预测是至关重要的,因为它可以帮助hpc管理员优化作业分配和资源调度,从而提高计算效率和性能。
3、传统的时间序列预测方法通常采用基于统计学的方法,如自回归移动平均(autoregressive integrated moving average model,arima)和指数平滑时间序列(exponential time smoothing,ets)等。arima模型可以捕捉到时间序列的历史趋势和周期性,并以此进行预测,而ets可以对不同时间序列进行组合以提高预测精准性,上述模型都是时间序列预测中常用的方法。但是,这些方法通常需要大量领域知识和手工调整参数,限制了它们的泛化能力和预测精度。
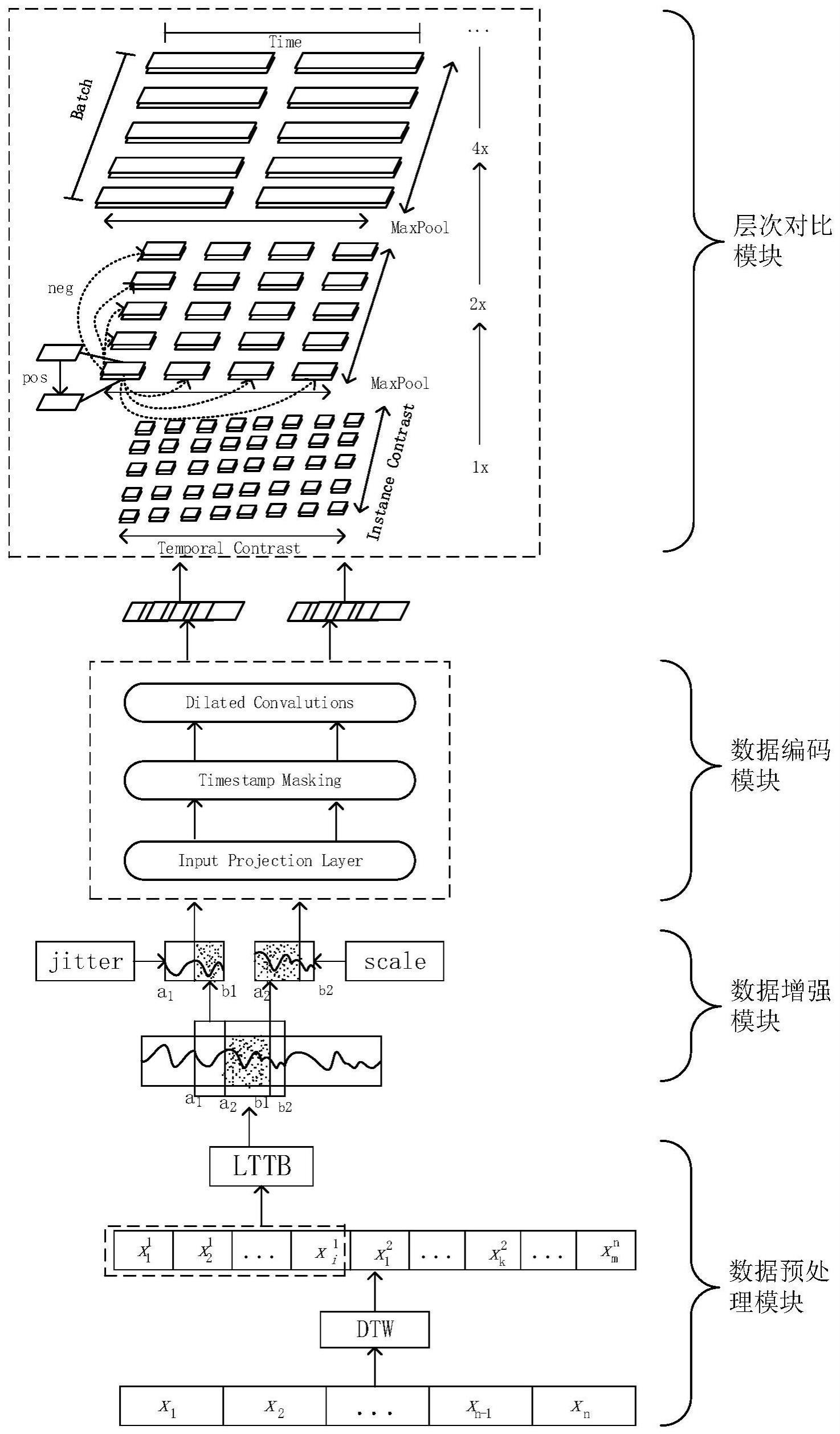
4、除了传统的基于统计学的方法,近年来深度学习方法已经成为时间序列预测的主流方法之一。其中,循环神经网络(recurrent neural network,rnn)和门控循环单元(gaterecurrent unit,gru)等模型,可以通过学习时间序列数据中的长期依赖关系和非线性关系来实现更准确的预测。另外,随着时间序列数据规模的增加,基于图神经网络(graphneural networks,gnn)的方法也成为研究热点,它们能够利用图结构对时间序列数据进行建模和预测。然而,这些模型也存在诸多缺点。首先,rnn和gru模型需要大量的时间序列数据,然后按照时间步进行计算,计算效率低,计算复杂度高。其次,rnn和gru模型通常在短期预测上效果较好,但是在长期预测时容易出现偏移现象,导致预测效果不佳。此外,图神经网络考虑了节点之间的关系,可以将节点信息和他们的关系结合在一起进行预测,比较适用于图数据的预测。但是,图神经网络模型通常比较复杂,需要更多的计算资源以及更长的训练时间,使得图神经网络在处理大规模数据集时的预测效率较低。
技术实现思路
1、为了解决上述背景技术中存在的至少一项技术问题,本发明提供一种基于自监督对比学习的hpc作业功耗预测方法及系统,其将时间序列数据转化为向量表示,然后利用这些向量进行预测,模型考虑了数据的连续性,可以在长期预测任务中取得较好的性能,计算复杂度也明显低于传统预测方法。
2、为了实现上述目的,本发明采用如下技术方案:
3、本发明的第一个方面提供一种基于自监督对比学习的hpc作业功耗预测方法,包括如下步骤:
4、获取hpc作业功耗数据,并转化为hpc作业功耗时间序列;
5、基于hpc作业功耗时间序列和训练后的作业功耗预测模型,得到作业功耗预测结果;其中,所述作业功耗预测模型的构建过程为:
6、通过编码器将hpc作业功耗时间序列映射到高层特征空间,生成向量表示;
7、采用向量对比的方式进行学习,将生成的向量表示在时间戳粒度以及实例粒度进行对比;在时间粒度上进行对比,学习数据随时间的动态变化趋势;在实例粒度上进行对比,学习不同类别的数据之间的差异和相似特征;基于得到的动态变化趋势、差异和相似特征进行作业功耗预测。
8、本发明的第二个方面提供一种基于自监督对比学习的hpc作业功耗预测系统,包括:
9、数据获取模块,其用于获取hpc作业功耗数据,并转化为hpc作业功耗时间序列;
10、作业功耗预测模块,其用于基于hpc作业功耗时间序列和训练后的作业功耗预测模型,得到作业功耗预测结果;其中,所述作业功耗预测模型的构建过程为:
11、通过编码器将hpc作业功耗时间序列映射到高层特征空间,生成向量表示;
12、采用向量对比的方式进行学习,将生成的向量表示在时间戳粒度以及实例粒度进行对比;在时间粒度上进行对比,学习数据随时间的动态变化趋势;在实例粒度上进行对比,学习不同类别的数据之间的差异和相似特征;基于得到的动态变化趋势、差异和相似特征进行作业功耗预测。
13、本发明的第三个方面提供一种计算机可读存储介质。
14、一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如第一方面所述的一种基于自监督对比学习的hpc作业功耗预测方法中的步骤。
15、本发明的第四个方面提供一种计算机设备。
16、一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如第一方面所述的一种基于自监督对比学习的hpc作业功耗预测方法中的步骤。
17、与现有技术相比,本发明的有益效果是:
18、1、本发明采用了基于表示学习和自监督学习的方法进行训练,在不需要标注数据的情况下自动学习时间序列数据的特征表示,本模型将时间序列数据转化为向量表示,然后利用这些向量进行预测。模型考虑了数据的连续性,可以在长期预测任务中取得较好的性能,计算复杂度也明显低于rnn和gru模型。
19、2、通过学习时间序列数据的表示,能够更加准确地预测hpc作业所产生的高功耗。相比于传统的预测方法,本发明采用了一种全新的思路,即利用对时间序列数据进行对比学习的方式,将时间序列数据转换为更能有效表示时间序列特征的向量,从而使得预测效果得到了显著提高。
20、本发明附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
技术特征:
1.一种基于自监督对比学习的hpc作业功耗预测方法,其特征在于,包括如下步骤:
2.如权利要求1所述的一种基于自监督对比学习的hpc作业功耗预测方法,其特征在于,在获取hpc作业功耗数据后进行数据预处理和数据增强,包括:
3.如权利要求2所述的一种基于自监督对比学习的hpc作业功耗预测方法,其特征在于,所述对每组数据进行降采样处理,包括:
4.如权利要求2所述的一种基于自监督对比学习的hpc作业功耗预测方法,其特征在于,所述采用随机截取两个具有重叠区域的子序列的方式进行数据增强,具体包括:
5.如权利要求1所述的一种基于自监督对比学习的hpc作业功耗预测方法,其特征在于,所述通过编码器将hpc作业功耗时间序列映射到高层特征空间,具体包括:
6.如权利要求1所述的一种基于自监督对比学习的hpc作业功耗预测方法,其特征在于,在时间粒度上进行对比时,将时间序列的不同增强视图中相同时间戳的向量表示作为正样本,将来自同一时间序列的不同时间戳的表示作为负样本,通过这种方式,模型可以学习到具区分性的时间序列表示。
7.如权利要求1所述的一种基于自监督对比学习的hpc作业功耗预测方法,其特征在于,在实例粒度上进行对比时,在实例级别上将来自同一聚类中不同时间序列的数据作为负样本进行对比。
8.一种基于自监督对比学习的hpc作业功耗预测系统,其特征在于,包括:
9.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现如权利要求1-7中任一项所述的一种基于自监督对比学习的hpc作业功耗预测方法中的步骤。
10.一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现如权利要求1-7中任一项所述的一种基于自监督对比学习的hpc作业功耗预测方法中的步骤。
技术总结
本发明属于HPC作业预测领域,提供了一种基于自监督对比学习的HPC作业功耗预测方法及系统,本发明采用了基于表示学习和自监督学习的方法进行训练,采用向量对比的方式进行学习,将生成的向量表示在时间戳粒度以及实例粒度进行对比;在时间粒度上进行对比,学习数据随时间的动态变化趋势;在实例粒度上进行对比,学习不同类别的数据之间的差异和相似特征;基于得到的动态变化趋势、差异和相似特征进行作业功耗预测。考虑了数据的连续性,可以在长期预测任务中取得较好的性能,计算复杂度也明显低于RNN和GRU模型。
技术研发人员:张杰,李响,田学森,赵志刚,王继彬,武鲁
受保护的技术使用者:山东省计算中心(国家超级计算济南中心)
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!