一种基于模态联合交互的图像问答方法
该发明涉及人工智能深度学习图像问答,具体涉及一种基于模态联合交互的图像问答方法。
背景技术:
1、目前在计算机领域,不管是网速还是性能上都有极大的提升,因此数据也以各个模态的形式在互联网上传递着,比如从最开始的文本到图像传输,再到语音、视频等模态,都离不开计算机软硬件的发展。图像问答作为一种经典的跨模态任务,它需要计算机从给定的图像和问题中寻找关键信息并推理出问题的答案,相比于单模态的目标检测、问答系统等任务,需要计算机模型对图文信息有更细粒度的理解,同时对两种模态进行融合交互进而实现模型推理的能力。
2、图像问答需要分别对图像和问题文本进行理解,对图像而言,它本身是以高维数据结构的形式存储,同时包含着大量的譬如颜色、形状等视觉信息,这些信息对人类是很直观的,但对于计算机来说是极具挑战的。
3、随着计算机视觉的发展,越来越多的图像特征提取方法能够有效地提取和编码图像中的信息,使计算机能够理解图像中的各类信息。而问题文本属于自然语言,其中会包含大量的语义和语法信息,对于计算机来说也不能直观理解。除此之外,自然语言会存在多义和歧义等问题,这也增加了计算机对自然语言理解的难度。当前自然语言处理领域也涌现出词嵌入方法能够让计算机很好地理解自然语言,这对计算机推理能力的提升是很关键的。而对图文特征由于存在语义差异,导致难以进行有效的融合并让模型获得推理能力,且模型的交互能力低,这也是图像问答任务的主要难题。
技术实现思路
1、针对现有技术中的上述不足,本发明提供的一种基于模态联合交互的图像问答方法解决了现有技术中图文特征难以融合导致的无法进行答案预测的问题。
2、为了达到上述发明目的,本发明采用的技术方案为:
3、提供了一种基于模态联合交互的图像问答方法,其包括以下步骤:
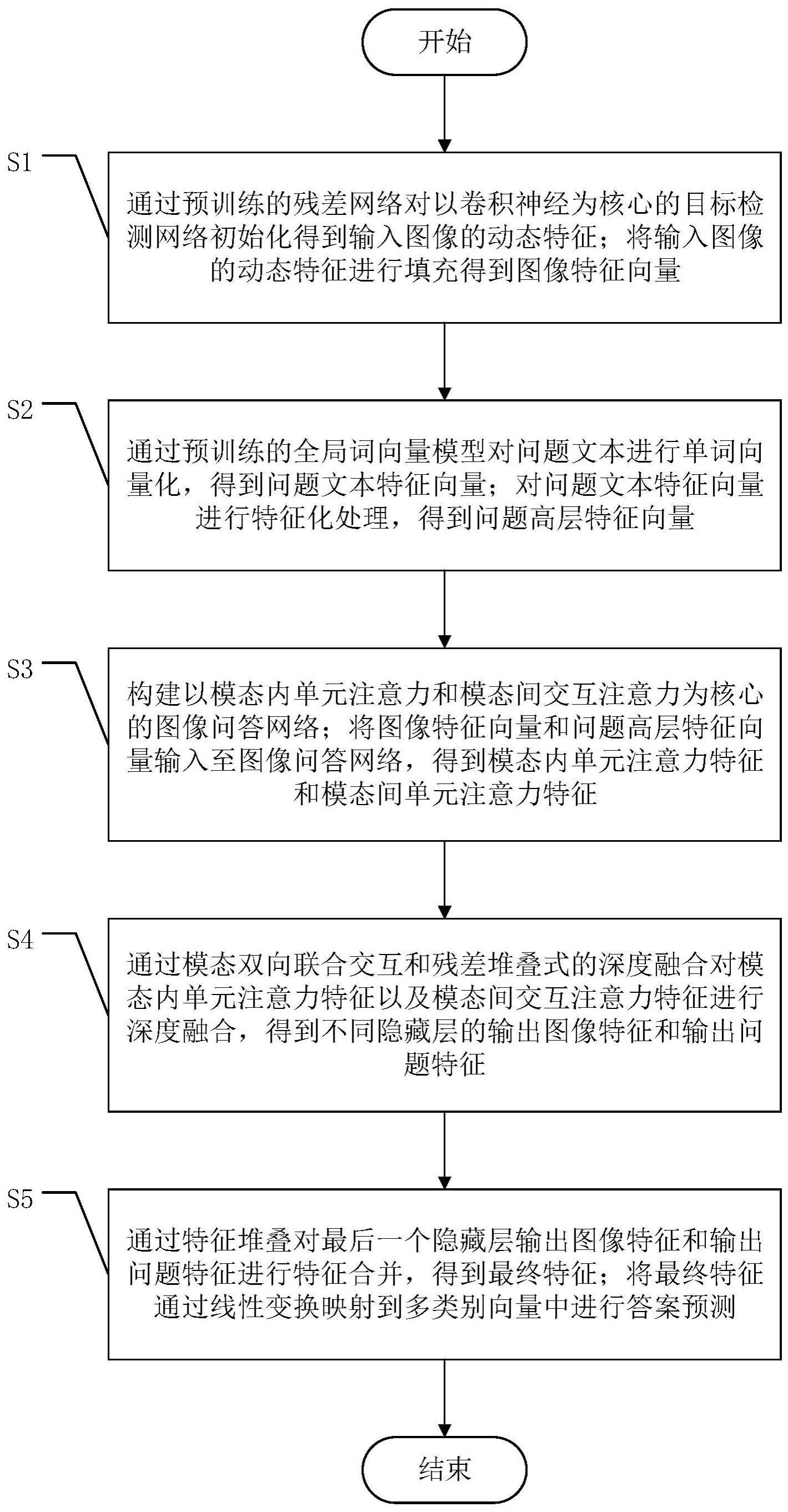
4、s1、通过预训练的残差网络对以卷积神经为核心的目标检测网络初始化得到输入图像的动态特征;将输入图像的动态特征进行填充得到图像特征向量;
5、s2、通过预训练的全局词向量模型对问题文本进行单词向量化,得到问题文本特征向量;对问题文本特征向量进行特征化处理,得到问题高层特征向量;
6、s3、构建以模态内单元注意力和模态间交互注意力为核心的图像问答网络;将图像特征向量和问题高层特征向量输入至图像问答网络,得到模态内单元注意力特征和模态间单元注意力特征;
7、s4、通过模态双向联合交互和残差堆叠式的深度融合对模态内单元注意力特征以及模态间交互注意力特征进行深度融合,得到不同隐藏层的输出图像特征和输出问题特征;
8、s5、通过特征堆叠对最后一个隐藏层输出图像特征和输出问题特征进行特征合并,得到最终特征;将最终特征通过线性变换映射到多类别向量中进行答案预测。
9、进一步地,步骤s1中预训练的残差网络采用resnet-101网络结构,卷积神经网络采用faster r-cnn网络结构;所述步骤s2中全局词向量模型采用glove模型。
10、进一步地,步骤s2的具体步骤如下:
11、s2-1、将问题文本中的m个单词进行分词和向量化得到问题文本特征向量;
12、s2-2、将问题文本特征向量用0进行填充得到维度为mques×emb_size的向量表示其中,表示问题文本t时刻的向量表示,mques表示问题单词数,emb_size表示问题的嵌入维度;
13、s2-3、引入双向门控循环单元,根据公式:
14、
15、
16、得到t时刻的双向隐藏状态,即前向隐藏状态和反向隐藏状态其中,gru(·)表示循环神经网络模型,表示t-1时刻的前向隐藏状态,表示t+1时刻的反向隐藏状态;
17、s2-4、将所有时刻的问题文本特征向量进行拼接得到最后的问题高层特征向量
18、进一步地,步骤s3的具体步骤如下:
19、s3-1、将图像问答网络的模型参数进行初始化,将图像特征向量和问题高层特征向量输入至图像问答网络;
20、s3-2、对图像问答网络的模型进行训练,将预设的答案类别为训练目标,通过反向传播算法和随机梯度下降对图像问答网络进行训练,对图像问答网络的参数进行调整,得到训练后的图像问答网络;其中,图像问答网络的参数包括可学习的权重矩阵wn和偏置项bn;
21、s3-3、构建图像模态内单元注意力模块和问题模态内单元注意力模块,选取其中一个模态内单元注意力模块,根据公式:
22、q,k,v=trans(x)
23、得到查询向量q、键向量k和值向量v;其中,n表示问题的单词数或图像的对象数,emb_dim表示问题的嵌入维度,x表示维度为n×emb_dim的某一个模态的特征向量,trans(·)表示将特征向量x转换为多头特征向量;特征向量x包括图像特征向量和问题高层特征向量;
24、s3-4、根据公式:
25、
26、得到注意力得分矩阵s;其中,kt表示键向量k的转置矩阵,dk表示查询向量q的emb_dim大小;
27、s3-5、根据公式:
28、a=softmax(s),s∈rmh×n×n
29、得到注意力权重矩阵a;其中,softmax(·)表示归一化指数函数,r表示实数,mh表示注意力头的个数;
30、s3-6、将多头特征向量进行转换得到与原始输入相同维度的多头特征向量,根据公式:
31、o=trans'(a·v)
32、o'=layernorm(o+dropout(o))
33、ffn(o')=max(0,o'w1+b1)w2+b2
34、oi=layernorm(o'+dropout(ffn(o')))
35、得到模态内单元注意力矩阵oi,即该模态的模态内单元注意力特征;其中,trans'(·)表示维度转换函数,o表示初始模态内单元注意力矩阵,o'表示中间模态内单元注意力矩阵,dropout(·)表示随机失活,layernorm(·)表示归一化函数,ffn(·)表示前馈神经网络,max(·)表示实现relu激活函数,w1表示输入层到隐藏层的可学习的权重矩阵,w2表示隐藏层到输出层的可学习的权重矩阵,b1表示输入层到隐藏层的偏置项,b2表示隐藏层到输出层的偏置项;
36、s3-7、重复步骤s3-3至步骤s3-6,得到另一个模态的模态内单元注意力矩阵oi;
37、s3-8、构建模态间交互注意力,将一个模态的特征作为查询,将另一个模态的特征作为键值,根据公式:
38、
39、得到注意力权重矩阵a1;其中,q1表示一个模态特征的查询向量,k1表示另一个模态特征的键向量,k1t表示键向量k1的转置矩阵,d1表示查询向量q1的emb_dim大小,v1表示另一个模态特征的值向量;
40、s3-9、根据公式:
41、o1=layernorm(a1+dropout(a1))
42、oa=layernorm(o1+dropout(ffn(o1)))
43、得到模态间单元注意力矩阵oa,即模态间单元注意力特征;其中,o1表示初始模态间单元注意力矩阵。
44、进一步地,步骤s3-2的反向传播算法采用的损失函数为二元交叉熵损失函数。
45、进一步地,步骤s4的具体步骤如下:
46、s4-1、根据公式:
47、
48、得到以图像特征为引导的模态间交互注意力特征xo和以问题特征为引导的模态间交互注意力特征yo;其中,cr(·)表示模态间交互注意力,x'表示图像模态内单元注意力特征,y'表示问题模态内单元注意力特征;
49、s4-2、根据公式:
50、
51、得到第i个隐藏层的深度堆叠后的以图像特征为引导的模态间交互注意力特征x[i]和第i个隐藏层的深度堆叠后的以问题特征为引导的模态间交互注意力特征y[i];其中,i表示第i个隐藏层,xo[i-1]表示第i-1个隐藏层的以图像特征为引导的模态间交互注意力特征,yo[i-1]表示第i-1个隐藏层的以问题特征为引导的模态间交互注意力特征;
52、s4-3、根据公式:
53、
54、得到第i个隐藏层的输出图像特征x[i]和第i个隐藏层的输出问题特征y[i];其中,x[i-1]表示第i-1个隐藏层的深度堆叠后的以图像特征为引导的模态间交互注意力特征,y[i-1]表示第i-1个隐藏层的深度堆叠后的以问题特征为引导的模态间交互注意力特征,αi表示第i个隐藏层的图像可训练权值变量,βi表示第i个隐藏层的问题可训练权值变量。
55、步骤s5中的线性变换映射的公式如下:
56、of=proj(concat(x[i],y[i]))
57、其中,of表示答案,x[i]表示最后一个隐藏层的输出图像特征x[i],y[i]表示最后一个隐藏层的输出问题特征,concat(·)表示拼接算子,proj(·)表示线性变换映射函数。
58、本发明的有益效果为:
59、1.本发明可通过构建基于模态联合交互的图文特征提取与深度融合的模型以及引入模态联合交互的机制,实现了图像和问题特征之间的双向引导,提升了模型交互能力;通过使用残差式的深度堆叠融合机制,增强了跨模态语义空间的信息共享。
60、2.本发明中的模态双向引导的机制同时考虑到两个模态之间的深度交互,采用了正向和反向对两个模态内单元注意力特征的联合引导,增强了模型的多模态交互能力,提升了答案分类的效果;
61、3.本发明中的残差堆叠的融合机制采用了深度堆叠的方式让双向引导后的特征进一步交互;其残差动态机制的设计,提高了表达能力以及避免了训练过程中深度神经网络梯度消失的问题,提升了模型的泛化性。
- 还没有人留言评论。精彩留言会获得点赞!