气井日产气量预测方法、确定装置、电子设备及存储介质与流程
本发明涉及油气田开发,具体而言,涉及一种气井日产气量预测方法、确定装置、电子设备及存储介质。
背景技术:
1、我国的天然气储量丰富,有良好的开发前景。加快天然气的开发有利于我国能源清洁转型,是天然气工业的必然选择。其中,在气藏开发之前,做好产量的预测对气藏开发具有重要指导意义,它不仅可以检验勘探的效果,还有利于做好气藏的开发部署和规划。
2、目前,预测气井的日产气量的方法主要有经验公式法、解析方法和数值模拟法三种。经验公式和分析模型难以考虑气藏复杂的渗流特性,不同模型的应用条件和应用阶段不同,导致预测结果与实际储层特征差异较大。气井数值模拟的相关计算量大,历史拟合困难,产量预测效率低,结果不确定性大,故现场推广性一般。
3、综上所述,常规的日产气量的预测方法有对数据特征提取不充分、应用条件受限等缺点,针对这些不足日产气量预测需要提供新的思路。机器学习和深度学习广泛应用于多个领域,均取得了良好的效果。深度神经网络依托大量数据集和深层的网络结构,能够充分学习到数据的特征,使得预测结果具有较高的可信度。
技术实现思路
1、本发明目的是:为了解决常规方法确定气井日产气量效率低、准确性差,从而影响下一步开发方案的制定和工艺的应用情况,基于生产井生产历史数据,在机器学习原理的基础上建立了麻雀搜索算法优化lstm的气井日产气量预测模型,实现对气井的日产气量的高效精准的预测。
2、为实现上述目的,本发明提供一种气井日产气量预测方法、确定装置、电子设备及存储介质,采用以下技术方案实现:
3、本发明提供一种气井日产气量预测方法,该方法包括下列步骤:
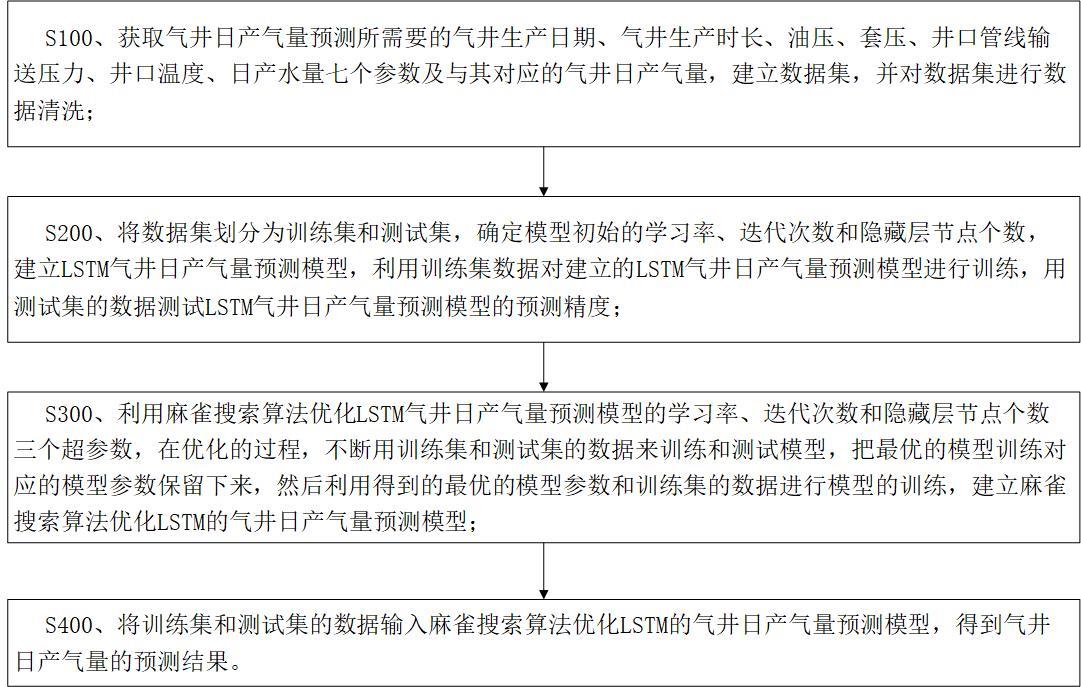
4、s100、获取气井日产气量预测所需要的气井生产日期、气井生产时长、油压、套压、井口管线输送压力、井口温度、日产水量七个参数及与其对应的气井日产气量,建立数据集,并对数据集进行数据清洗;
5、s200、将数据集划分为训练集和测试集,确定模型初始的学习率、迭代次数和隐藏层节点个数,建立lstm气井日产气量预测模型,利用训练集数据对建立的lstm气井日产气量预测模型进行训练,用测试集的数据测试lstm气井日产气量预测模型的预测精度;
6、s300、利用麻雀搜索算法优化lstm气井日产气量预测模型的学习率、迭代次数和隐藏层节点个数三个超参数,在优化的过程,不断用训练集和测试集的数据来训练和测试模型,把最优的模型训练对应的模型参数保留下来,然后利用得到的最优的模型参数和训练集的数据进行模型的训练,建立麻雀搜索算法优化lstm的气井日产气量预测模型;
7、s400、将训练集和测试集的数据输入麻雀搜索算法优化lstm的气井日产气量预测模型,得到气井日产气量的预测结果。
8、进一步的,所述步骤s100具体包括如下步骤:
9、s101、提取气井生产日期、气井生产时长、油压、套压、井口管线输送压力、井口温度、日产水量及气井日产气量的历史数据;
10、s102、剔除历史数据中的异常值和缺失值数据,并进行归一化处理;
11、s103、根据气井生产日期将历史数据进行排序,创建输入模型的数据集,数据集的输入包括气井生产日期、气井生产时长、油压、套压、井口管线输送压力、井口温度、日产水量七个参数,数据集的输出为气井日产气量。
12、进一步的,所述步骤s300具体包括如下步骤:
13、s301、初始化麻雀种群,设置麻雀种群总数量、发现者和加入者比例、最大迭代次数和安全值;
14、s302、将均方根误差作为适应度函数,计算所有麻雀的适应度值,并排序,选出当前最优和最差的位置;
15、s303、根据位置更新公式,更新发现者、加入者和预警麻雀的位置,得到第 i个麻雀在第 j维中的位置信息,并更新其适应度值;
16、s304、判断是否达到最大迭代次数,满足则停止迭代,适应度值最低的麻雀的位置作为最优解,并输出结果,否则,重复执行上述s302到s303步骤。
17、进一步的,所述步骤s303中的位置更新公式包括:
18、发现者的位置更新公式:
19、;
20、其中, t代表当前迭代数, j=1,2,3…, d;是一个常数,表示最大迭代次数;表示第 i个麻雀在发生t+1次迭代时在第 j维中的位置信息;表示第 i个麻雀在发生t次迭代时在第 j维中的位置信息;是一个随机数;和分别表示预警值和安全值; q是服从正态分布的随机数; l为且每个元素都为1的矩阵;exp表示以e为底的指数函数;
21、加入者的位置更新公式:
22、;
23、其中,表示第 i个麻雀在发生t+1次迭代时在第 j维中的位置信息;表示第 i个麻雀在发生t次迭代时在第 j维中的位置信息;表示发现者在发生t+1次迭代时在第 j维中的最优位置信息,则表示当前全局最差的位置; q是服从正态分布的随机数; l为且每个元素都为1的矩阵;exp表示以e为底的指数函数; a为一个一行n维矩阵,矩阵内元素为1或者-1,并且;
24、预警麻雀的位置更新公式:
25、;
26、其中,表示第 i个麻雀在发生t+1次迭代时在第 j维中的位置信息;表示第 i个麻雀在发生t次迭代时在第 j维中的位置信息;表示发生t次迭代时当前的全局最优位置;表示发生t次迭代时当前的全局最差位置;作为步长控制参数,是服从均值为0,方差为1的正态分布的随机数;是一个随机数,则是当前麻雀个体的适应度值;和分别是当前全局最佳和最差的适应度值;是非零常数。
27、进一步的,所述步骤s300中,是否是最优的模型训练是根据均方根误差来判断的,均方根误差最小的对应最优的模型训练。
28、本发明进一步提供一种确定装置,包括:
29、数据获取模块,用于获取目标数据集中的数据;
30、预处理模块,用于对获取的目标数据集中的数据进行预处理,删除异常值,进行归一化;
31、产量确定模块,用于根据目标数据集,利用麻雀搜索算法优化lstm气井日产气量预测模型超参数,提升模型预测效果,确定目标气井的日产气量。
32、本发明进一步提供一种电子设备,包括:
33、存储器、处理器、可在处理器中运行和可在存储器中存储的计算机程序、输入装置和输出装置,其中,处理器执行计算机程序时实现上述方法的步骤。
34、本发明进一步提供一种存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现上述方法的步骤。
- 还没有人留言评论。精彩留言会获得点赞!