结构化文本信息生成方法、装置、电子设备及存储介质与流程
本发明涉及文本结构化,特别是涉及一种结构化文本信息生成方法、一种结构化文本信息生成装置、一种电子设备以及一种计算机可读存储介质。
背景技术:
1、nlp(自然语言处理,natural language processing),是通过计算机理解、处理以及运用人类语言,它属于人工智能的一个分支。在自然语言处理过程中,文本结构化可以将自然文本转化为具有不同分段且各分段都可以具备对应类别的文本。其中,分段在文本结构化中也通常被称为结构段,即,文本结构化主要包括对自然文本包括的多个结构段进行拆分,再对多个结构段所对应的类别进行区分。
2、文本结构化的结果是否准确决定了自然语言处理的效率,所以,如何提升文本结构化的效率成为了本领域技术人员需要克服的技术问题。
技术实现思路
1、本发明实施例是提供一种结构化文本信息生成方法、装置、电子设备以及计算机可读存储介质,以解决如何提升文本结构化的效率的问题。
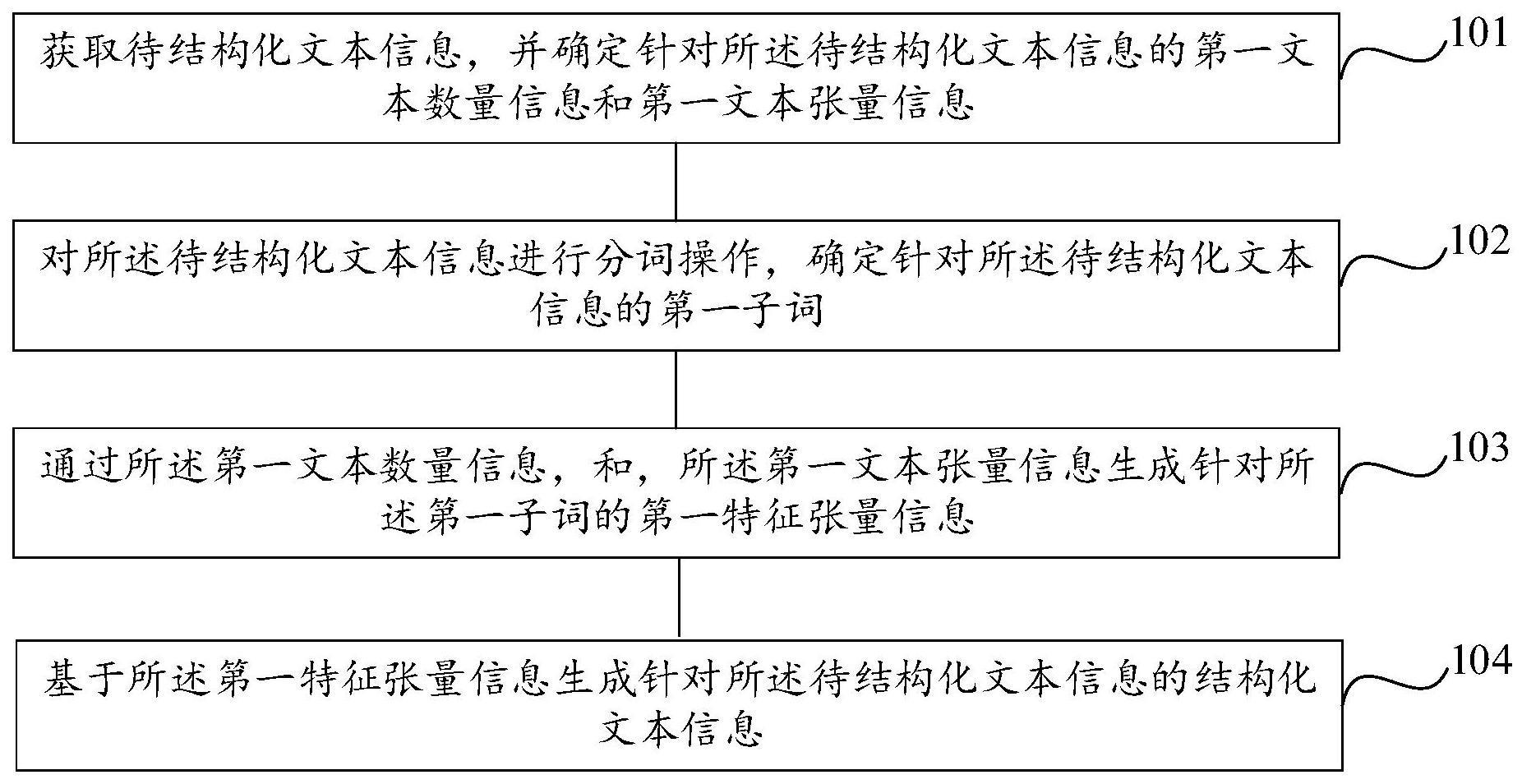
2、本发明实施例公开了一种结构化文本信息生成方法,包括:
3、获取待结构化文本信息,并确定针对所述待结构化文本信息的第一文本数量信息和第一文本张量信息;
4、对所述待结构化文本信息进行分词操作,确定针对所述待结构化文本信息的第一子词;
5、通过所述第一文本数量信息,和,所述第一文本张量信息生成针对所述第一子词的第一特征张量信息;
6、基于所述第一特征张量信息生成针对所述待结构化文本信息的结构化文本信息。
7、可选地,所述方法应用于经预训练的多语言模型bert,所述多语言模型bert包括词嵌入层和编码层,所述通过所述第一文本数量信息,和,所述第一文本张量信息生成针对所述第一子词的第一特征张量信息的步骤包括:
8、通过所述第一文本张量信息确定针对所述词嵌入层的词嵌入层维度信息,和,针对所述编码层的编码层维度信息;
9、基于所述词嵌入层维度信息,和,所述编码层维度信息,和,所述第一文本数量信息生成针对所述第一子词的第一特征张量信息。
10、可选地,所述基于所述第一特征张量信息生成针对所述待结构化文本信息的结构化文本信息的步骤包括:
11、对所述第一特征张量信息执行降维操作,生成第二特征张量信息;
12、基于所述第二特征张量信息生成针对所述待结构化文本信息的结构化文本信息。
13、可选地,所述多语言模型bert包括连接层,所述对所述第一特征张量信息执行降维操作,生成第二特征张量信息的步骤包括:
14、确定针对所述连接层的连接层维度信息;
15、基于所述连接层维度信息采用所述多语言模型bert对所述第一特征张量信息执行降维操作,生成第二特征张量信息。
16、可选地,所述待结构化文本信息包括多个第一结构段,所述基于所述第二特征张量信息生成针对所述待结构化文本信息的结构化文本信息的步骤包括:
17、基于所述第二特征张量确定针对所述第一结构段的第一结构段锚点;
18、基于所述结构段锚点,确定针对所述第一结构段的第一结构段起止位置信息;
19、基于所述起止位置,确定针对所述第一结构段的第一结构段类别信息;
20、根据所述第一结构段锚点,和,所述第一结构段起止位置信息,和,所述第一结构段类别信息确定针对所述待结构化文本信息的结构化文本信息。
21、可选地,还包括:
22、获取标注文本信息,并确定针对所述标注文本信息的第二文本数量信息;
23、确定针对所述标注文本信息的第二文本张量信息;
24、通过所述第二文本数量信息,和,所述第二文本张量信息生成针对所述标注文本信息的第三特征张量信息;
25、对所述第三特征张量信息执行降维操作,生成第四特征张量信息;
26、基于所述第四特征张量信息训练所述多语言模型bert。
27、可选地,所述标注文本信息包括多个第二结构段,所述基于所述第四特征张量信息训练所述多语言模型bert的步骤包括:
28、对所述标注文本信息进行分词操作,以确定针对所述标注文本信息的第二子词,以及用于表达第二子词的子词序列向量;所述子词序列向量具有对应的序列向量长度信息;
29、确定针对所述标注文本信息的文本标签信息;所述文本标签信息包括针对所述第二结构段的第二结构段起止位置信息,和,第二结构段类别信息;
30、采用所述第四特征张量信息确定针对所述第二子词的锚点预测值,和,针对所述第二结构段的结构段起止位置信息预测值,和,针对所述第二结构段的结构段类别得分预测值;
31、采用所述序列向量长度信息和所述锚点预测值确定目标锚点得分标签值;
32、采用所述第二结构段起止位置信息和所述结构段起止位置信息预测值确定目标结构段起始位置标签值;
33、采用所述第二结构段类别信息和所述结构段类别得分预测值确定目标结构段类别得分标签值;
34、采用所述目标锚点得分标签值,和,所述目标结构段起始位置标签值,和,所述目标结构段类别得分标签值训练所述多语言模型bert。
35、本发明实施例还公开了一种结构化文本信息生成装置,包括:
36、待结构化文本信息获取模块,用于获取待结构化文本信息,并确定针对所述待结构化文本信息的第一文本数量信息和第一文本张量信息;
37、第一子词确定模块,用于对所述待结构化文本信息进行分词操作,确定针对所述待结构化文本信息的第一子词;
38、第一特征张量信息生成模块,用于通过所述第一文本数量信息,和,所述第一文本张量信息生成针对所述第一子词的第一特征张量信息;
39、结构化文本信息生成模块,用于基于所述第一特征张量信息生成针对所述待结构化文本信息的结构化文本信息。
40、可选地,所述方法应用于经预训练的多语言模型bert,所述多语言模型bert包括词嵌入层和编码层,所述通过所述第一文本数量信息,和,所述第一特征张量信息生成模块用于:
41、通过所述第一文本张量信息确定针对所述词嵌入层的词嵌入层维度信息,和,针对所述编码层的编码层维度信息;
42、基于所述词嵌入层维度信息,和,所述编码层维度信息,和,所述第一文本数量信息生成针对所述第一子词的第一特征张量信息。
43、可选地,所述结构化文本信息生成模块用于:
44、对所述第一特征张量信息执行降维操作,生成第二特征张量信息;
45、基于所述第二特征张量信息生成针对所述待结构化文本信息的结构化文本信息。
46、可选地,所述多语言模型bert包括连接层,所述结构化文本信息生成模块用于:
47、确定针对所述连接层的连接层维度信息;
48、基于所述连接层维度信息采用所述多语言模型bert对所述第一特征张量信息执行降维操作,生成第二特征张量信息。
49、可选地,所述待结构化文本信息包括多个第一结构段,所述结构化文本信息生成模块用于:
50、基于所述第二特征张量确定针对所述第一结构段的第一结构段锚点;
51、基于所述结构段锚点,确定针对所述第一结构段的第一结构段起止位置信息;
52、基于所述起止位置,确定针对所述第一结构段的第一结构段类别信息;
53、根据所述第一结构段锚点,和,所述第一结构段起止位置信息,和,所述第一结构段类别信息确定针对所述待结构化文本信息的结构化文本信息。
54、可选地,还包括:
55、标注文本信息获取模块,用于获取标注文本信息,并确定针对所述标注文本信息的第二文本数量信息;
56、第二文本张量信息确定模块,用于确定针对所述标注文本信息的第二文本张量信息;
57、第三特征张量信息生成模块,用于通过所述第二文本数量信息,和,所述第二文本张量信息生成针对所述标注文本信息的第三特征张量信息;
58、第四特征张量信息生成模块,用于对所述第三特征张量信息执行降维操作,生成第四特征张量信息;
59、多语言模型bert训练模块,用于基于所述第四特征张量信息训练所述多语言模型bert。
60、可选地,所述多语言模型bert训练模块用于:
61、对所述标注文本信息进行分词操作,以确定针对所述标注文本信息的第二子词,以及用于表达第二子词的子词序列向量;所述子词序列向量具有对应的序列向量长度信息;
62、确定针对所述标注文本信息的文本标签信息;所述文本标签信息包括针对所述第二结构段的第二结构段起止位置信息,和,第二结构段类别信息;
63、采用所述第四特征张量信息确定针对所述第二子词的锚点预测值,和,针对所述第二结构段的结构段起止位置信息预测值,和,针对所述第二结构段的结构段类别得分预测值;
64、采用所述序列向量长度信息和所述锚点预测值确定目标锚点得分标签值;
65、采用所述第二结构段起止位置信息和所述结构段起止位置信息预测值确定目标结构段起始位置标签值;
66、采用所述第二结构段类别信息和所述结构段类别得分预测值确定目标结构段类别得分标签值;
67、采用所述目标锚点得分标签值,和,所述目标结构段起始位置标签值,和,所述目标结构段类别得分标签值训练所述多语言模型bert。
68、本发明实施例还公开了一种电子设备,包括处理器、通信接口、存储器和通信总线,其中,所述处理器、所述通信接口以及所述存储器通过所述通信总线完成相互间的通信;
69、所述存储器,用于存放计算机程序;
70、所述处理器,用于执行存储器上所存放的程序时,实现如本发明实施例所述的方法。
71、本发明实施例还公开了一种计算机可读存储介质,其上存储有指令,当由一个或多个处理器执行时,使得所述处理器执行如本发明实施例所述的方法。
72、本发明实施例包括以下优点:
73、本发明实施例,通过对所述待结构化文本信息进行分词操作,确定针对所述待结构化文本信息的第一子词;通过所述第一文本数量信息,和,所述第一文本张量信息生成针对所述第一子词的第一特征张量信息;基于所述第一特征张量信息生成针对所述待结构化文本信息的结构化文本信息,从而实现了以子词作为粒度为基础,有效避免了输出子词多结构穿插的问题,从而提升了文本结构化的效率。
- 还没有人留言评论。精彩留言会获得点赞!