一种基于知识图谱和文本对分类的立场检测方法与流程
本发明涉及立场检测领域,具体涉及一种基于知识图谱和文本对分类的立场检测方法。
背景技术:
1、立场检测的目的是将一段文本根据给定的立场检查目标,划分为支持、反对和中立三类或是在此基础上细分的多种类型。知识图谱是一种以实体—关系—实体形式的三元组为基本单位构成的语义网络,其网状结构可以用于表示现实世界中实体的复杂关系,这一特性使得知识图谱被广泛用于各种立场检测方法。
2、目前基于知识图谱的立场检测方案中,大多是将知识图谱中的三元组用作注入到句子中的领域知识,利用知识图谱增强bert来进行立场检测,但其未将知识图谱与立场检测目标将结合,导致立场检测目标外置,知识图谱的作用很难被区分为辅助还是外源的低效答案库,从而损失了检测性能。
3、此外,为了进行立场检测构建知识图谱所进行的海量数据收集以及实体和关系抽取工作,在进行立场检测时,绝大部分都被模型和知识筛选算法弃置。因此,如何提高知识图谱的利用率也应当被关注。然而,如果要引入更多的知识,就不得不解决外部知识对句意的干扰问题,否则也会影响检测的准确性。
技术实现思路
1、本发明所要解决的技术问题是:提出一种基于知识图谱和文本对分类的立场检测方法,目的在于提高知识图谱的利用率,降低外部知识对句意的影响,并缓解立场检测目标外置导致的检测性能损失。
2、本发明解决上述技术问题采用的技术方案是:
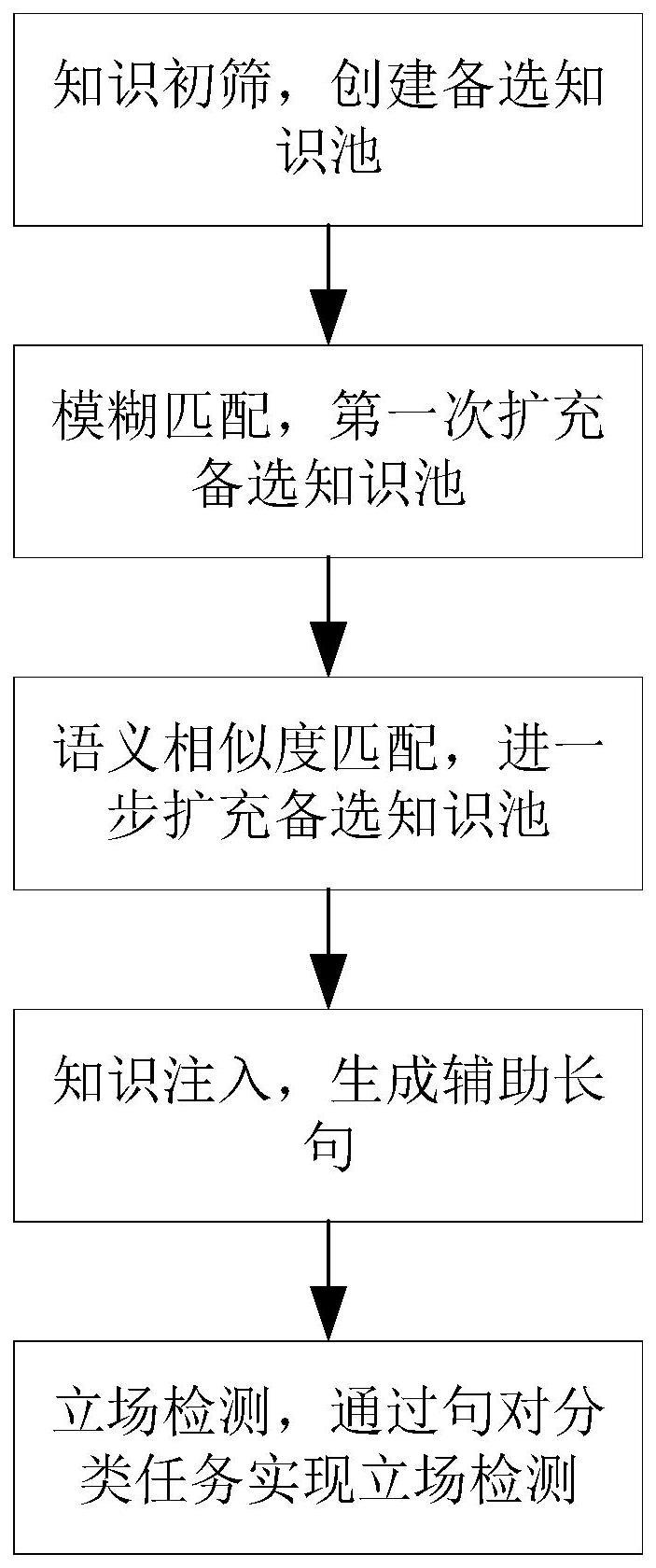
3、一种基于知识图谱和文本对分类的立场检测方法,包括以下步骤:
4、s1、针对给定的立场检测目标和原始输入文本,提取两者所包含的实体并进行任意的两两组合,构成实体对集合;
5、s2、将实体对集合中的各实体对分别与知识图谱中的实体对进行匹配,获得知识图谱中与实体对集合中各实体对相匹配的三元组,构建为备选知识池;
6、s3、将给定的立场检测目标及针对该立场检测目标的不同立场类别分别与备选知识池中的所有三元组相结合,构建不同立场类别表征的辅助句;
7、s4、将给定的原始输入文本分别与步骤s3中构建的不同立场类别表征的辅助句组合为输入对,并分别输入至文本检测模型,通过所述文本检测模型输出该原始输入文本隶属不同立场类别的置信度,并以最大置信度所对应立场类别作为该原始输入文本的立场检测结果。
8、进一步的,步骤s2中,将实体对集合中的各实体对分别与知识图谱中的实体对进行匹配,获得知识图谱中与实体对集合中各实体对相匹配的三元组,构建为备选知识池,包括:
9、首先,将实体对集合中的各实体对分别与知识图谱中的实体对进行直接匹配,获得知识图谱中实体对分别与实体对集合中的各实体对相一致的三元组,构建为初始的备选知识池;
10、然后,将初始的备选知识池中的三元组与知识图谱中的三元组,进行模糊匹配,将满足预设条件的知识图谱中的三元组加入备选知识池,获得第一次扩充后的备选知识池;
11、再然后,将第一次扩充后的备选知识池中的三元组与知识图谱中的三元组,进行语义相似度匹配,将满足预设条件的知识图谱中的三元组加入备选知识池,获得第二次扩充后的备选知识池。
12、具体的,将实体对集合中的各实体对分别与知识图谱中的实体对进行直接匹配,获得知识图谱中实体对分别与实体对集合中的各实体对相一致的三元组,构建为初始的备选知识池,具体为:
13、对于实体对集合中的实体对t=(ti,tj),当满足以下条件时:
14、t=(ti,tj)∈k=(km,r,kn),i≠j,m≠n
15、将知识图谱中的三元组k加入备选知识池;
16、其中,km、kn、r分别为知识图谱中的三元组中的头实体、尾实体以及关系;ti,tj分别为给定的原始输入文本中的实体。
17、具体的,将初始的备选知识池中的三元组与知识图谱中的三元组,进行模糊匹配,将满足预设条件的知识图谱中的三元组加入备选知识池,获得第一次扩充后的备选知识池,具体为:
18、将知识图谱中满足下式的三元组kf加入备选知识池:
19、
20、其中,fuzz()为模糊匹配函数,mf是模糊匹配后备选知识池中的三元组数量,m是模糊匹配前备选知识池中的三元组数量,lf是设定的模糊匹配数量上限,sf是模糊匹配相似度阈值。
21、具体的,模糊匹配相似度阈值sf的计算方式如下:
22、
23、其中,lt是知识图谱中的三元组的平均长度,le是知识图谱中的三元组中的实体的平均长度,lr是知识图谱中的三元组中的关系的平均长度。
24、具体的,将第一次扩充后的备选知识池中的三元组与知识图谱中的三元组,进行语义相似度匹配,将满足预设条件的知识图谱中的三元组加入备选知识池,获得第二次扩充后的备选知识池,具体为:
25、将知识图谱中满足下式的三元组ks加入备选知识池:
26、
27、其中,similarity()为语义相似度匹配函数,ms是语义相似度匹配后备选知识池中的三元组数量,m′是语义相似度匹配前备选知识池中的三元组数量,ls是设定的语义相似度匹配数量上限;sse是设定的语义相似度阈值。
28、具体的,步骤s3中,将给定的立场检测目标及针对该立场检测目标的不同立场类别分别与备选知识池中的所有三元组相结合,构建不同立场类别表征的辅助句,包括:
29、首先,对备选知识池k={k1,k2,...,kn}进行序列化,并添加描述性前缀pd,获得知识序列k′:
30、k′=[pd,h1,r1,t1,h2,r2,t2,...,hn,rn,tn]
31、其中,描述性前缀pd是预设的使得备选知识池的序列化三元组构成陈述性语句形式存在的前缀,所述h、r和t分别表示头实体、关系和尾实体,所述h、r和t的下标则为该三元组在备选知识池中的序号;
32、将立场检测目标及针对该立场检测目标的不同立场类别分别进行组合,获得立场文本:
33、supl=tgt+sfxl
34、其中,tgt为立场检测目标的文本,sfxl为针对立场检测目标tgt的第l个立场类别的文本,supl表示针对立场检测目标tgt的第l个立场类别的立场文本;
35、然后,将知识序列k′分别与各立场文本相结合,构建不同立场类别表征的辅助句:
36、supplementaryl=supl+k′
37、其中,supplementaryl表示针对立场检测目标tgt的第l个立场表征的辅助句。
38、具体的,所述针对该立场检测目标的不同立场类别包括支持、中立和反对,其中,所述支持,为对给定的立场检测目标持有肯定的态度;所述中立,为对给定的立场检测目标持有中立的态度;所述反对,为对给定的立场检测目标持有否定的态度;
39、所述描述性前缀pd为表示“已知”的描述性语句。
40、具体的,步骤s4中,将给定的原始输入文本分别与步骤s3中构建的不同立场类别表征的辅助句组合为输入对,具体为:
41、input1=[cls]+[originaltext]+[sep]
42、inputl=[cls]+[supplementaryl]+[sep]
43、其中,input1为原始输入文本的输入,[originaltext]表示原始文本;inputl为第l个立场表征辅助句的输入,[supplementaryl]表示第l个立场表征的辅助句;[cls]和[sep]分别为起始、结束标记。
44、具体的,步骤s4中,通过所述文本检测模型输出该原始输入文本隶属不同立场类别的置信度,并以最大置信度所对应立场类别作为该原始输入文本的立场检测结果具体包括:
45、首先,文本检测模型,利用编码器,分别对输入的各输入对进行特征编码:
46、el=encoder(input1,inputl)
47、然后,文本检测模型,以各输入对的特征编码为输入,利用全连接层,分别输出各输入对针对各立场类别的匹配度logitsl:
48、logitsl=wel+b
49、其中,w和b为全连接层的权重矩阵和偏置项;
50、之后,文本检测模型,利用各输入对针对各立场类别的匹配度logitsl,构建匹配度矩阵logits,所述匹配度矩阵的行和列分别表征输入对和立场类别,其值为各输入对针对各立场类别的匹配度;并以匹配度矩阵作为输入,利用softmax进行多分类,获得最终的置信矩阵c:
51、c=softmax(logits)
52、最后,选择置信矩阵c中的最大元素,将其所对应的立场类别作为该原始输入文本的立场检测结果。
53、本发明的有益效果是:
54、首先,在创建备选知识池时,将立场检测目标和原始输入文本所包含的实体作为匹配的备选实体,并将备选实体任意组合构成实体对集合,通过知识图谱的信息,能提取获得原始文本所包含实体与立场检测目标所包含实体的联系,无论立场检测目标是否存在于原始文本中,均能保证原始文本所包含实体与立场检测目标所包含实体进行连接,并作为辅助立场检测的知识,丰富备选知识池,缓解了立场检测目标外置导致的检测性能损失;其次,通过实体对匹配,筛选知识图谱中的知识,获得备选知识池,提高了知识图谱中知识的利用率,有助于充分利用这些知识提高检测的准确性;其三,将备选知识池所包含的外部知识与立场检测目标结合,构成带有不同立场的辅助句,避免了将外部知识直接插入原始文本中,降低了外部知识对句意的影响。
55、因此,本发明所提出的一种基于知识图谱和文本对分类的立场检测方法,提高了知识图谱的利用率,降低了外部知识对句意的影响,并缓解立场检测目标外置导致的检测性能损失。
- 还没有人留言评论。精彩留言会获得点赞!